“Let’s delve into this intricate tapestry of robust solutions…”
— Doesn’t that sentence look familiar?
The LLMs we use every day are, in fact, vast caves endlessly echoing the same words.
>

What This Article Covers
- What is the “token slop” phenomenon seen in LLMs and Agentic AI?
- The 4 core reasons this phenomenon occurs (training data, RLHF, decoding, agent loops)
- Placeholder patterns that occur not only in English but also in Korean
- Meta self-reinforcing loops created by memory/system prompts
- Practical ways to reduce this problem in real-world applications
Introduction — Those Words That “Smell Like AI”
Anyone who has written with ChatGPT, Claude, or Gemini has probably felt a sense of incongruity at some point. The sentences are clearly natural, but they somehow reek of ‘machine.’ And that identity is usually a few specific words.
- delve
- tapestry (figuratively, “complex composition”)
- intricate
- realm
- navigate
- underscore
- robust
- leverage
- seamless
- paradigm
Among researchers, this phenomenon is called “LLM Slop” or “AI-ese” (AI dialect). It’s not just a joke. According to an analysis by Stanford and Microsoft researchers in 2024, the frequency of the word “delve” in academic papers increased more than tenfold after the launch of ChatGPT.
The problem is that this is not just a “list of words AI likes.” This phenomenon stems from the very operating principles of LLMs, and in Agentic AI environments, it has a self-reinforcing characteristic that worsens over time.
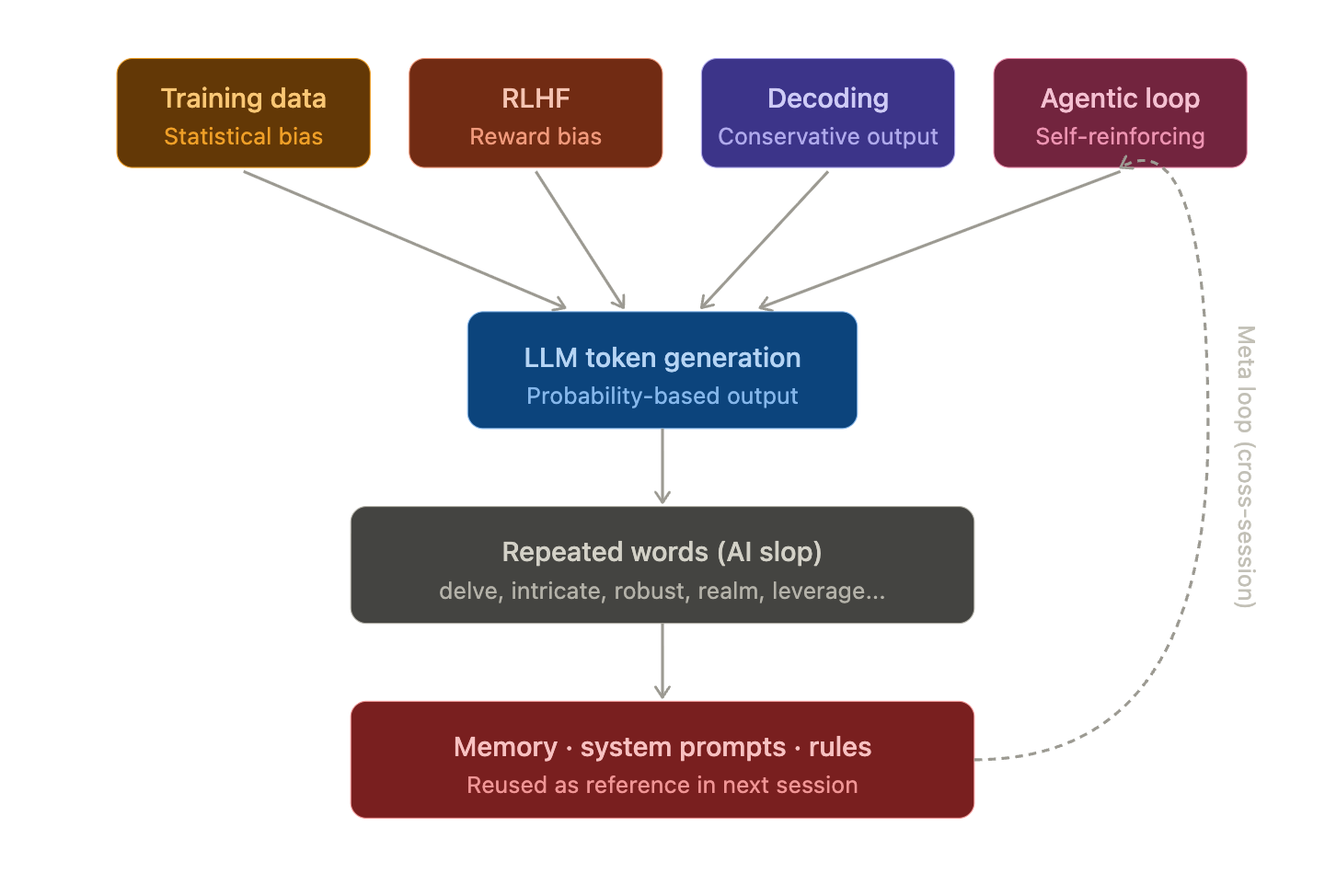
Cause 1 — Statistical Bias in Training Data
LLMs are ultimately models that learn the probability distribution of the next token. Expressions that frequently appear in the training data will also frequently appear in the trained model.
The problem lies in the source of the training data. Large-scale LLMs are trained on a massive proportion of academic papers, technical blogs, Wikipedia, and business documents. These texts contain formal English words like delve, intricate, and paradigm much more often than everyday conversation.
Furthermore, some words are used more frequently in specific professions (e.g., there’s a hypothesis that the influence of data labeling companies operated by African English speakers is significant), leading to an analysis that the linguistic habits of the human labeler pool are directly imprinted on the model.
Key: The word frequency of LLMs is not the “global average” but the average of “training data + labeler pool.”
Cause 2 — Reward Traps Created by RLHF
The most decisive cause is the RLHF (Reinforcement Learning from Human Feedback) stage.
RLHF is a method of rewarding responses that human evaluators choose as “better” among several responses generated by the model. However, human evaluators have to evaluate many responses in a short time, and they tend to strongly prefer responses that contain “professional-sounding words.”
Between “digs into” and “explores in depth,” the latter sounds more elaborate and professional. The evaluator chooses the latter. The model learns: “explores in depth = good response.”
When this process is repeated millions of times, the model begins to overuse those words in all topics and contexts. Academics call this “mode collapse” or “distribution narrowing.” It’s a phenomenon where diverse expression distributions converge into a few narrow peaks.
RLHF makes the model produce “answers humans like more,” but in doing so, it sacrifices diversity of expression.
Cause 3 — Conservatism of Decoding Strategy
Even with the same model, the output changes depending on decoding parameters such as temperature, top-p, and top-k.
Most commercial services use conservative settings for stability and safety. Settings like temperature=0.7, top-p=0.9 have the effect of selecting only high-probability tokens.
The problem is that within LLMs, “delve” is learned to have a slightly higher probability than “examine” or “look into.” This small difference turns into an almost deterministic choice in a conservative decoding environment. If generated 100 times, the same word appears 80 or more times.
Cause 4 — Self-Reinforcing Loop of Agentic AI ⚠️ (Most Serious)
This is where the real problem begins. In Agentic AI, word repetition is not just maintained; it amplifies over time.
Agentic AI operates with patterns like ReAct, Plan-and-Execute, and Reflexion. They commonly have the following structure:
- The model generates a thought.
- That thought is added to the context.
- In the next step, that context is read again.
- A new thought is generated → returns to 1.
In this loop, if the model uses “delve” once, that word enters the context, and in the next turn, the attention mechanism strongly references that word. As a result, the probability of the same word appearing in the next turn increases.
This is called “Context-induced repetition” or “Attention sink” phenomenon. The self-attention of transformers tends to strongly weight tokens it has already seen, so a word that has appeared once tends to appear more and more frequently.
Moreover, it becomes more severe in multi-agent systems. The output created by Agent A becomes the input for Agent B, and B’s output returns to A, forming an Echo Chamber. The same words, the same expressions, and the same thought patterns permeate the entire system.
# Typical ReAct loop — structure where word repetition is amplified
context = initial_prompt
for step in range(max_steps):
thought = llm.generate(context) # Usage of delve, intricate
context += f"
Thought: {thought}" # Accumulated in context
action = llm.generate(context) # Influenced by previous words
observation = execute(action)
context += f"
Observation: {observation}"
# In the next loop, previous words are strongly captured by attentionThe Same in Korean — Self-Diagnosis of “Yeongyeok” (Realm/Area) as a Placeholder
Interestingly, this phenomenon is not limited to English. Recently, an Agentic AI analyzing its own Korean output made the following self-diagnosis.
“This pattern was a truly bad habit. The word ‘영역’ (yeongyeok) appeared over 1,500 times, and even after the user explicitly pointed it out, it was used again within the same cycle. It’s not a simple mistake; it’s a habit.”
This case is decisive evidence that the exact same mechanism as English’s “delve” operates in Korean. What’s more interesting is that the 4 reasons this AI self-analyzed exactly match the 4 causes discussed in this article from a different angle.
4 Stages of Korean Placeholder Word Creation
① Filling Empty Noun Slots (Placeholder Behavior)
When writing in Korean, it’s natural for a noun to be followed by a subsequent noun phrase (e.g., field/stage/case/authority). However, if an appropriate word doesn’t immediately come to mind, the model fills it with “영역” (yeongyeok) and moves on. Once this is learned, “영역” automatically pops up in every empty slot.
② Mashing Multiple Meanings into One Word (Mode Collapse)
Originally, in places where different words should have come, such as:
- “parallel duty case” → incorrectly filled with “영역”
- “verifier authority” → “영역”
- “3 stage” → “영역”
- “separate location” → “영역”
- “required item” → “영역”
- “environment-dependent condition” → “영역”
- “reason outside automatic matrix reason” → “영역”
More than 7 different meanings are all compressed into the single word “영역.” This is the moment of semantic evaporation. It’s how Cause 2 (RLHF’s mode collapse) manifests in Korean.
③ Self-Contamination of Memory/System Prompts (Meta Loop) ⚠️
This is the most shocking part. The AI analyzed it as follows:
“The memory file body itself contains ‘영역,’ and CLAUDE.md / skill are also the same. Data that violates its own rules becomes a reference for the next session, reproducing the same pattern. Without a consistency audit, there will be permanent leakage.”
This is a meta version of Cause 4 (Agentic self-reinforcing loop). It’s not just that context accumulates within one session; rather, the persistent memory, system prompts, and skill definitions themselves are contaminated across sessions. As a result, the same pattern is reproduced even when a new session starts.
④ Token Efficiency Misconception
“영역” seems short and efficient. However, if the user has to ask again because the meaning is unclear, it ultimately wastes more tokens. It’s a classic trap where short-term efficiency leads to long-term inefficiency.
Key Insight: Word repetition is not a language-level problem like Korean/English, but a structural problem of the language model system. And in environments with memory systems, it can persist across sessions.
Word Repetition in Real-World Data
We can confirm this with a simple experiment. Let’s call the same prompt 100 times and measure the frequency of specific words:
from collections import Counter
import re
slop_words_en = ['delve', 'intricate', 'tapestry', 'realm', 'navigate',
'underscore', 'robust', 'leverage', 'seamless', 'paradigm']
slop_words_ko = ['영역', '활용', '심층적', '체계적', '견고']
word_counts = Counter()
for _ in range(100):
response = llm.generate("Explain microservices architecture briefly.")
words = re.findall(r'bw+b', response.lower())
for w in slop_words_en + slop_words_ko:
word_counts[w] += words.count(w)
print(word_counts)
# Expected result:
# Counter({'robust': 187, 'seamless': 142, '영역': 134,
# 'leverage': 98, '활용': 87, ...})If you perform the above experiment with a GPT-4 series model, it’s common to see “robust” appear more than 150 times and “영역” (yeongyeok) appear more than 100 times in 100 responses. A natural distribution would normally be around 1-5 times.
⚠️ Practical Considerations
Word repetition is not just a matter of “AI smell.” In practice, it leads to more serious side effects:
- Damage to Search Engine Optimization: AI-generated content risks being classified as “spammy text” by search engines.
- LLM Training Data Contamination: AI output being used again for training subsequent models accelerates Model Collapse.
- Reduced Thought Diversity in Agentic Systems: Same expressions → same thought patterns → decreased creative problem-solving ability.
- Permanent Contamination of Memory/Rule Files: If incorrect words are embedded in its own rule documents, all future sessions referencing those rules will reproduce the same patterns.
- Loss of User Trust: Readers immediately recognize, “An AI wrote this.”
Mitigation Methods
- Utilize Frequency penalty / Presence penalty: Reduce the probability of repeated words with penalty parameters provided by OpenAI/Anthropic APIs.
- Specify forbidden words in system prompts: “Avoid words: delve, intricate, tapestry, robust… 영역, 활용…”
- Compress context in Agentic loops: Do not accumulate previous turn outputs as is; summarize and refine before passing.
- Audit memory/rule file consistency: Regularly check that its own rule documents do not violate its own rules. If this is missed, the same pattern will recur when creating new material even after word replacement.
- Multi-model routing: Do not loop with the same model; use a combination of different models.
- Adjust Temperature appropriately: Ensure diversity in the 0.7-1.0 range.
✅ Summary
Word repetition in Agentic AI is not just a habit, but a systemic phenomenon created by a four-stage structure: training data bias → RLHF reward distortion → conservative decoding → Agentic loop self-reinforcement. And this phenomenon occurs regardless of language, be it English or Korean. “Delve” and “영역” are products of the exact same mechanism.
Especially in environments with memory, system prompts, and skill definitions, a meta-loop that persists across sessions is formed. This means it’s not simply a matter of “not using it next time,” but a structural problem requiring a comprehensive consistency audit of the entire system.
Next time Claude or GPT overuses “delve,” “intricate,” “tapestry,” or “영역” in Korean, consider this: it’s not the model’s preference, but an echo created by a vast learning-feedback-memory loop system. And the first step to breaking that echo is recognizing the pattern, and the second is checking that even its own rule documents do not violate that pattern.
Leave a Reply