“Let’s delve into this intricate tapestry of robust solutions…”
— どこかでよく見た文章ではないだろうか?
私たちが毎日使うLLMは、実は同じ単語を絶えず反響させる巨大な洞窟なのだ。
>

この記事で扱うこと
- LLMとAgentic AIに現れる「単語の繰り返し(token slop)」現象とは何か
- この現象が発生する4つの主要な原因(学習データ、RLHF、デコーディング、エージェントループ)
- 英語だけでなく韓国語でも同様に発生するプレースホルダーパターン
- メモリ/システムプロンプトが作り出すメタ自己強化ループ
- 実務でこの問題を軽減する現実的な方法
導入 — 「AI臭」がするあの単語たち
ChatGPT、Claude、Geminiで文章を書いたことがある人なら、誰もが一度は違和感を覚えたことがあるだろう。明らかに自然な文章なのに、どこか「機械臭」がプンプンする。そしてその正体は、たいてい特定の単語いくつかだ。
- delve (深く掘り下げる)
- tapestry (タペストリー、織物 — 比喩的に「複雑な構成」)
- intricate (精巧な)
- realm (領域)
- navigate (切り抜ける)
- underscore (強調する)
- robust (堅牢な)
- leverage (活用する)
- seamless (シームレスな)
- paradigm (パラダイム)
研究者の間では、この現象を「LLM Slop」または「AI-ese」(AI方言)と呼んでいる。単なる冗談ではない。2024年のスタンフォード大学とマイクロソフトの研究チームの分析によると、学術論文におけるdelveという単語の使用頻度がChatGPTリリース以降、10倍以上も爆増したという統計がある。
問題は、これが単なる「AIが好きな単語リスト」ではないという点だ。この現象はLLMの動作原理そのものに起因し、特にAgentic AI環境では時間が経つにつれてさらに悪化する自己強化(self-reinforcing)特性を持つ。
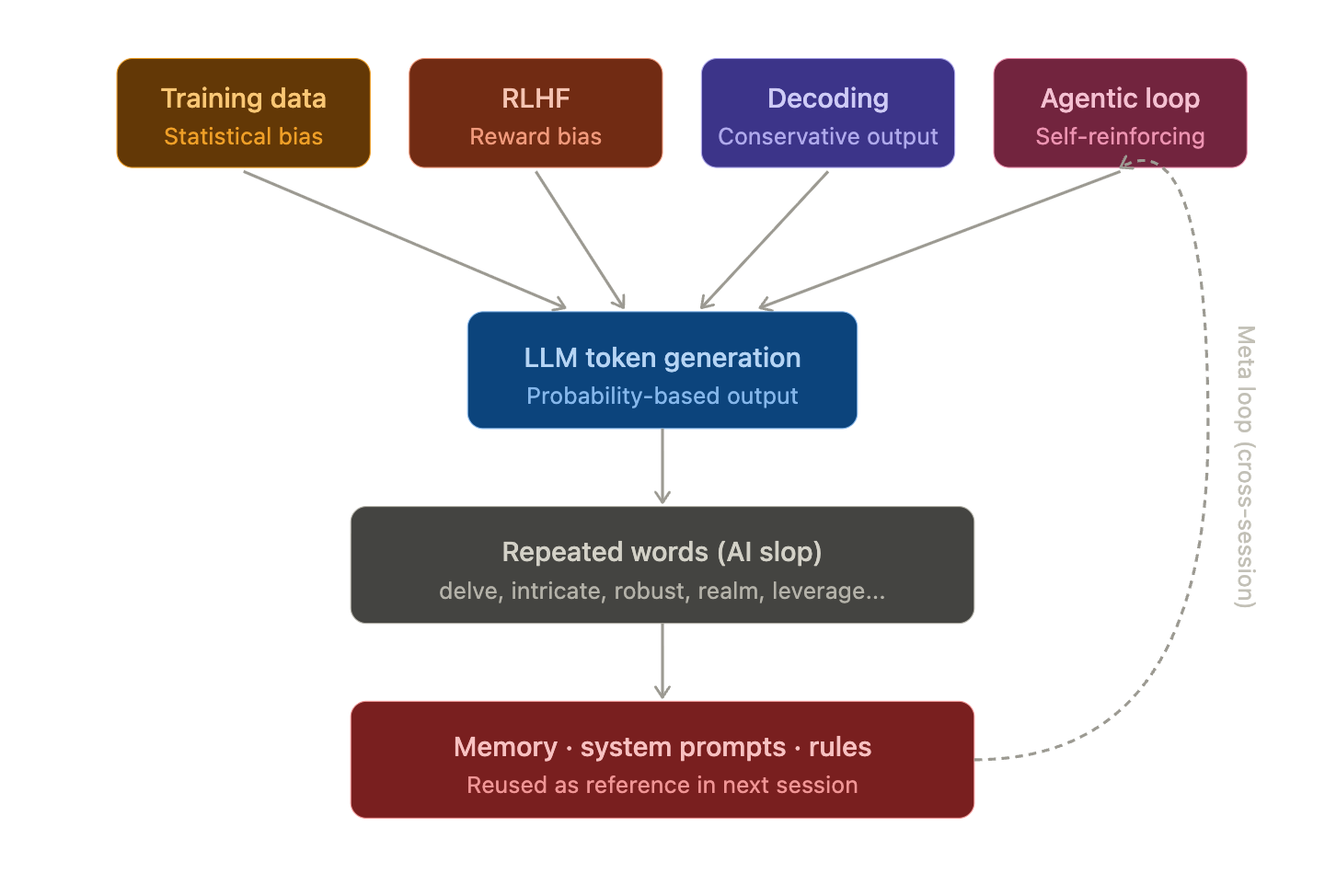
原因1 — 学習データの統計的偏り
LLMは結局、次のトークンの確率分布を学習するモデルである。学習データで頻繁に登場する表現は、学習が完了したモデルでも頻繁に登場する。
問題は学習データの出所だ。大規模LLMは、学術論文、技術ブログ、ウィキペディア、ビジネス文書を莫大な割合で学習する。このようなテキストには、delve、intricate、paradigmのような格式体英語が日常会話よりもはるかに頻繁に出てくる。
さらに、一部の単語は特定の職種(例:アフリカ系英語話者が運営するデータラベリング会社の影響が大きいという仮説もある)でより頻繁に使用され、人間ラベラープールの言語習慣がモデルにそのまま刻印されるという分析も存在する。
核心:LLMの単語頻度は「全世界平均」ではなく、「学習データ+ラベラープール」の平均である。
原因2 — RLHFが作り出した報酬の罠
最も決定的な原因はRLHF(Reinforcement Learning from Human Feedback)段階だ。
RLHFは、モデルが生成した複数の応答の中から人間評価者が「より良い」と選んだ応答に報酬を与える方式である。しかし、人間評価者は短時間で多くの応答を評価しなければならず、その際、「専門性があるように見える単語」が含まれた応答を好む傾向が強い。
「深く掘り下げます」と「深層的に探求します」では、後者の方が丁寧で専門的に見える。評価者は後者を選ぶ。モデルは学習する。「深層的に探求する=良い応答」。
この過程が数百万回繰り返されると、モデルはあらゆるテーマ、あらゆる文脈でその単語を乱用するようになる。これを学界では「mode collapse」または「distribution narrowing」と呼ぶ。多様な表現分布が狭いいくつかのピークに収束してしまう現象だ。
RLHFはモデルを「人間が好む答え」に近づけるが、その過程で表現の多様性を犠牲にする。
原因3 — デコーディング戦略の保守性
同じモデルでも、temperature、top-p、top-kのようなデコーディングパラメータによって出力が異なる。
ほとんどの商用サービスは、安定性と安全性のために保守的な設定を使用する。temperature=0.7、top-p=0.9のような設定は、確率の高いトークンのみを選択して使用する効果をもたらす。
問題は、LLM内部でdelveがexamineやlook intoよりも確率がわずかに高く学習されている点だ。この小さな違いが、保守的なデコーディング環境でほぼ決定論的な選択に変わる。100回生成すると80回以上同じ単語が出てくる。
原因4 — Agentic AIの自己強化ループ ⚠️(最も深刻)
ここからが本当の問題だ。Agentic AIでは、単語の繰り返しは単に維持されるだけでなく、時間が経つにつれて増幅される。
Agentic AIはReAct、Plan-and-Execute、Reflexionのようなパターンで動作する。共通して次の構造を持つ:
- モデルが思考(Thought)を生成する
- その思考をコンテキストに追加する
- 次の段階でそのコンテキストを再度読み込む
- 新しい思考を生成する → 1に戻る
このループで、モデルが一度delveを使用すると、その単語がコンテキストに入り、次のターンでアテンションメカニズムがその単語を強く参照する。その結果、次のターンで同じ単語が出る確率がさらに高くなる。
これを「Context-induced repetition」または「Attention sink」現象と呼ぶ。トランスフォーマーの自己アテンションは、自分がすでに見たトークンに強く重み付けする傾向があるため、一度出た単語はますます頻繁に出るようになる。
さらに、マルチエージェントシステムではさらに深刻になる。エージェントAが作成した出力がエージェントBの入力となり、Bの出力が再びAに戻ることでエコーチェンバー(Echo Chamber)が形成される。同じ単語、同じ表現、同じ思考パターンがシステム全体を侵食する。
# 典型的なReActループ — 単語の繰り返しが増幅される構造
context = initial_prompt
for step in range(max_steps):
thought = llm.generate(context) # delve, intricate の使用
context += f"
Thought: {thought}" # コンテキストに蓄積
action = llm.generate(context) # 以前の単語に影響される
observation = execute(action)
context += f"
Observation: {observation}"
# 次のループで以前の単語がアテンションに強く捕捉される韓国語でも同じ — 「영역(領域)」というプレースホルダーの自己診断
興味深いことに、この現象は英語だけの問題ではない。最近、あるAgentic AIが自身の韓国語出力を分析した結果、次のような自己診断を下した。
「このパターンは本当に悪い習慣でした。『영역』(領域)という単語が約1,500回以上登場し、ユーザーが明示的に指摘した後も同じサイクル内で再び使ってしまいました。単純なミスではなく、習慣です。」
このケースは、英語のdelveと全く同じメカニズムが韓国語でも機能するという決定的な証拠だ。さらに興味深いのは、このAIが自己分析した4つの原因が、本文で扱った4つの原因と異なる角度から正確に一致するという点だ。
韓国語プレースホルダー単語が作られる4段階
① 空の名詞の穴埋め(Placeholder Behavior)
韓国語で文章を書く際、名詞の後に後続の名詞句(分野/段階/事例/権限など)が続くのが自然だ。しかし、適切な単語がすぐに思い浮かばない場合、モデルはとりあえず「영역」(領域)で埋めて先に進む。これが学習されると、空の場所ごとに自動的に「영역」が飛び出すようになる。
② 複数の意味を一つの単語にまとめる(Mode Collapse)
本来、次のようにすべて異なる単語が来るべき場所に:
- 「並列義務事例」 → 「영역」と誤って埋める
- 「検証官権限」 → 「영역」
- 「3段階」 → 「영역」
- 「別途位置」 → 「영역」
- 「必須項目」 → 「영역」
- 「環境依存条件」 → 「영역」
- 「自動マトリックス外事由」 → 「영역」
7つ以上の異なる意味がすべて「영역」という一つの単語に圧縮される。意味の揮発(semantic evaporation)が起こる瞬間だ。本文の原因2(RLHFのmode collapse)が韓国語で発現した姿である。
③ メモリ/システムプロンプトの自己汚染(メタループ) ⚠️
ここが最も衝撃的な部分だ。そのAIは次のように分析した。
「メモリファイル本文自体に『영역』が入っており、CLAUDE.md / skillも同様だ。自己ルールに違反した資料が次のセッションの参照元となるため、また同じパターンが再生産される。整合性監査を行わないと永久的な漏洩となる。」
これは本文の原因4(Agentic自己強化ループ)のメタバージョンだ。単に一つのセッション内でコンテキストが累積されるだけでなく、セッションを超えて永続するメモリ・システムプロンプト・スキル定義自体が汚染されているのだ。その結果、新しいセッションを開始しても同じパターンが再生産される。
④ トークン効率の錯覚
「영역」は短く効率的に見える。しかし、ユーザーが意味を把握できずに再度質問しなければならない場合、結果的にトークンをさらに浪費することになる。短期的な効率が長期的な非効率を生む典型的な罠だ。
核心的な洞察:単語の繰り返しは韓国語/英語のような言語レベルの問題ではなく、言語モデルというシステムの構造的な問題である。そしてメモリシステムがある環境では、セッションを超えて永続化されうる。
実測データで見る単語の繰り返し
簡単な実験で確認できる。同じプロンプトを100回呼び出し、特定の単語の出現頻度を測定してみよう:
from collections import Counter
import re
slop_words_en = ['delve', 'intricate', 'tapestry', 'realm', 'navigate',
'underscore', 'robust', 'leverage', 'seamless', 'paradigm']
slop_words_ko = ['영역', '활용', '심층적', '체계적', '견고']
word_counts = Counter()
for _ in range(100):
response = llm.generate("Explain microservices architecture briefly.")
words = re.findall(r'bw+b', response.lower())
for w in slop_words_en + slop_words_ko:
word_counts[w] += words.count(w)
print(word_counts)
# 予想される結果:
# Counter({'robust': 187, 'seamless': 142, '영역': 134,
# 'leverage': 98, '활용': 87, ...})GPT-4系列で上記の実験を行うと、100回の応答でrobustが150回以上、韓国語応答では영역が100回以上登場することがよく見られる。自然な分布であれば1〜5回程度が正常なはずだ。
⚠️ 実務で注意すべき点
単語の繰り返しは単なる「AI臭」の問題ではない。実務ではさらに深刻な副作用を生む:
- 検索エンジン最適化の損傷:AI生成コンテンツが検索エンジンで「スパム性テキスト」と分類されるリスク
- LLM学習データの汚染:AI出力が再び次のモデル学習に使われることでモデル崩壊(Model Collapse)が加速
- Agenticシステムの思考多様性の低下:同じ表現 → 同じ思考パターン → 創造的な問題解決能力の減少
- メモリ・ルールファイルの永久汚染:自己ルール文書に誤った単語が埋め込まれると、そのルールを参照するすべての将来のセッションが同じパターンを再生産
- ユーザー信頼の喪失:読者が「これAIが書いたな」と即座に気づく
緩和方法
- Frequency penalty / Presence penaltyの活用:OpenAI/Anthropic APIが提供するペナルティパラメータで繰り返し単語の確率を下げる
- システムプロンプトに禁止単語を明記:「Avoid words: delve, intricate, tapestry, robust… 영역, 활용…」
- Agenticループでコンテキストを圧縮:以前のターンの出力をそのまま累積せず、要約・精製して伝達する
- メモリ・ルールファイルの整合性監査:自己ルール文書が自己ルールに違反していないか定期的に点検する。これが欠けると、単語置換後も新しい資料作成時に同じパターンが再発する
- 多重モデルルーティング:同じモデルでループを回さず、異なるモデルの組み合わせを使用する
- Temperatureの適切調整:0.7〜1.0の範囲で多様性を確保する
✅ まとめ
Agentic AIの単語の繰り返しは単なる癖ではなく、学習データの偏り → RLHFの報酬歪曲 → 保守的なデコーディング → Agenticループの自己強化という4段階構造で作り出されるシステム的な現象である。そしてこの現象は英語と韓国語を問わない。delveと영역は全く同じメカニズムの産物だ。
特にメモリ・システムプロンプト・スキル定義がある環境では、セッションを超えて永続化されるメタループが形成され、単に「次に使わなければいい」という問題ではなく、システム全体の整合性監査が必要な構造的な問題となる。
次にClaudeやGPTがdelve、intricate、tapestry、あるいは韓国語で영역を乱用したら、こう考えてみよう。これはモデルの好みではなく、巨大な学習-フィードバック-メモリーループシステムが作り出した反響だと。そしてその反響を断ち切る第一歩はパターンに気づくこと、第二歩は自己ルール文書さえもそのパターンに違反していないか点検することだ。
コメントを残す