“Let’s delve into this intricate tapestry of robust solutions…”
— 这句话是不是很眼熟?
我们每天使用的LLM,实际上是一个不断回响着相同词语的巨大洞穴。
>

本文涵盖内容
- LLM和Agentic AI中出现的“词语重复(token slop)”现象是什么?
- 导致此现象的4个核心原因(训练数据、RLHF、解码、代理循环)
- 不仅在英语中,在韩语中也同样出现的占位符模式
- 内存/系统提示符创建的元自我强化循环
- 在实际工作中减少此问题的实用方法
引言 — 那些“AI味”十足的词语
任何使用ChatGPT、Claude、Gemini撰写文章的人,都曾有过一丝违和感。句子明明很自然,却总带着一股“机器味”。而这种“机器味”通常源于几个特定的词语。
- delve (深入探讨)
- tapestry (挂毯,织物 — 比喻“复杂构成”)
- intricate (错综复杂的)
- realm (领域)
- navigate (驾驭)
- underscore (强调)
- robust (健壮的)
- leverage (利用)
- seamless (无缝的)
- paradigm (范式)
研究人员将这种现象称为“LLM Slop”或“AI-ese”(AI方言)。这并非玩笑。根据2024年斯坦福大学和微软研究人员的分析,学术论文中“delve”一词的使用频率在ChatGPT发布后暴增了10倍以上。
问题在于,这不仅仅是“AI喜欢的词语列表”。这种现象源于LLM自身的运作原理,尤其在Agentic AI环境中,它具有随着时间推移而加剧的自我强化(self-reinforcing)特性。
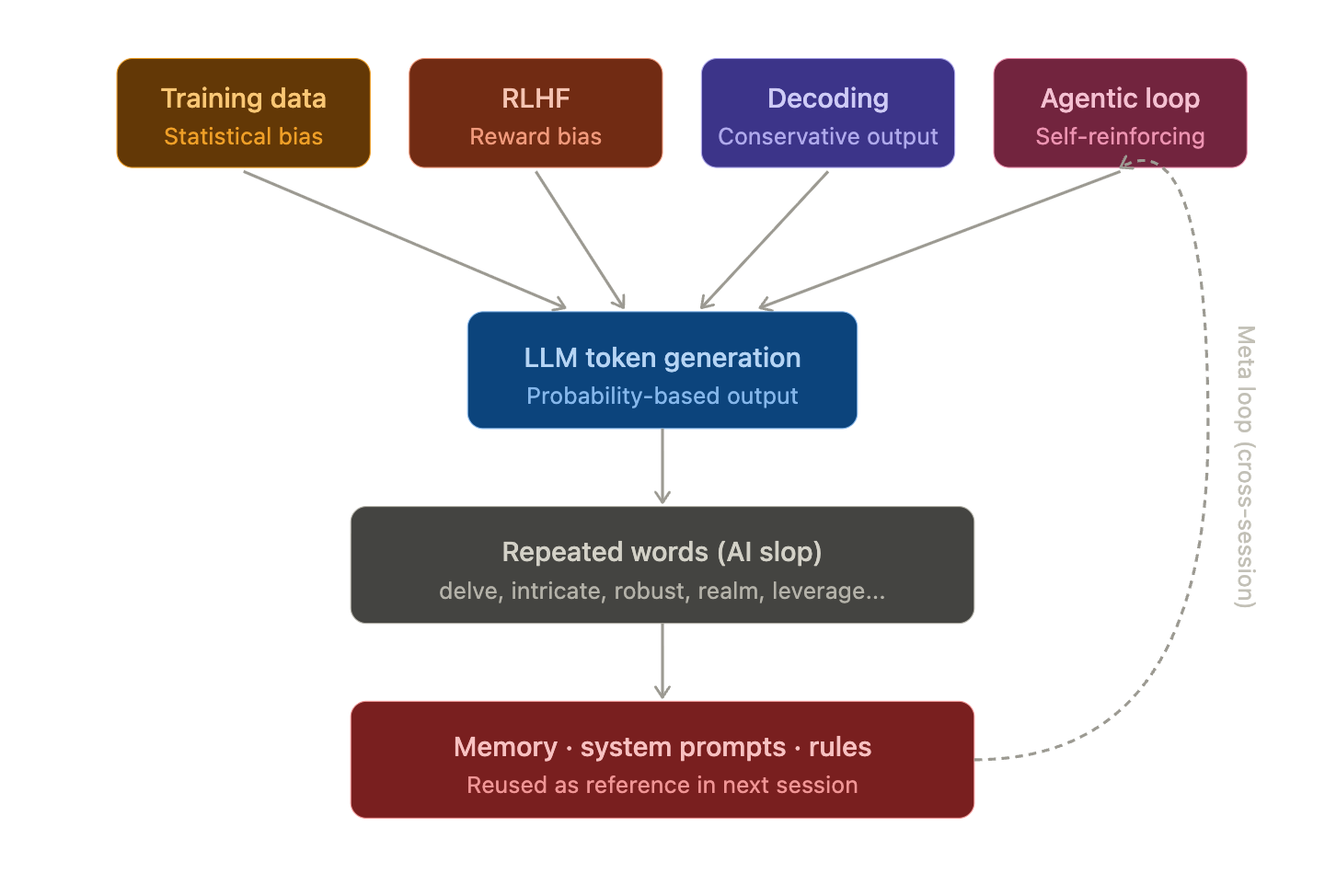
原因1 — 训练数据的统计偏差
LLM最终是学习下一个token概率分布的模型。在训练数据中频繁出现的表达,在训练完成的模型中也会频繁出现。
问题在于训练数据的来源。大规模LLM以学术论文、技术博客、维基百科、商业文档为主要训练内容。这些文本中,delve、intricate、paradigm等正式英语词汇的出现频率远高于日常对话。
此外,有分析指出,某些词语在特定职业群体(例如:有假说认为非洲裔英语使用者运营的数据标注公司的影响较大)中更频繁使用,导致人类标注员群体的语言习惯直接刻印在模型中。
核心:LLM的词语频率不是“全球平均”,而是“训练数据 + 标注员群体”的平均。
原因2 — RLHF制造的奖励陷阱
最决定性的原因是RLHF(Reinforcement Learning from Human Feedback)阶段。
RLHF是一种奖励人类评估者认为“更好”的模型生成响应的方法。然而,人类评估者需要在短时间内评估大量响应,此时他们倾向于偏爱包含“听起来专业”词语的响应。
在“深入研究”和“深度探索”中,后者听起来更认真、更专业。评估者会选择后者。模型因此学习到:“深度探索 = 好的响应”。
当这个过程重复数百万次后,模型就会在所有主题、所有语境中滥用这些词语。学术界称之为“模式崩溃(mode collapse)”或“分布收窄(distribution narrowing)”。即多样化的表达分布收敛到几个狭窄的峰值。
RLHF使模型生成“人类更喜欢的答案”,但在此过程中牺牲了表达的多样性。
原因3 — 解码策略的保守性
即使是同一个模型,其输出也会因temperature、top-p、top-k等解码参数而异。
大多数商业服务为了稳定性和安全性,会采用保守的设置。temperature=0.7、top-p=0.9等设置会产生只选择高概率token的效果。
问题在于,LLM内部学习到delve的概率略高于examine或look into。这种微小的差异在保守的解码环境中会变成几乎确定性的选择。生成100次,有80次以上会出现相同的词语。
原因4 — Agentic AI的自我强化循环 ⚠️ (最严重)
这才是真正的问题所在。在Agentic AI中,词语重复不仅仅是维持,而是随着时间推移而加剧。
Agentic AI以ReAct、Plan-and-Execute、Reflexion等模式运行。它们通常具有以下结构:
- 模型生成一个思考(Thought)
- 将该思考添加到上下文中
- 在下一步中再次读取该上下文
- 生成新的思考 → 返回步骤1
在这个循环中,如果模型使用了一次delve,该词就会进入上下文,在下一个回合中,注意力机制会强烈地引用该词。结果,在下一个回合中出现相同词语的概率会更高。
这被称为“上下文诱导重复(Context-induced repetition)”或“注意力陷阱(Attention sink)”现象。Transformer的自注意力机制倾向于强烈加权它已经见过的token,因此一旦出现的词语会越来越频繁地出现。
此外,在多代理系统中,情况会更加严重。代理A的输出成为代理B的输入,B的输出又返回给A,从而形成回音室(Echo Chamber)。相同的词语、相同的表达、相同的思维模式会侵蚀整个系统。
# 典型的ReAct循环 — 单词重复被放大的结构
context = initial_prompt
for step in range(max_steps):
thought = llm.generate(context) # 使用 delve, intricate
context += f"
Thought: {thought}" # 累积在上下文中
action = llm.generate(context) # 受先前词语影响
observation = execute(action)
context += f"
Observation: {observation}"
# 在下一个循环中,先前的词语被注意力机制强烈捕获韩语中也一样 — “영역”(领域)这一占位符的自我诊断
有趣的是,这种现象并非英语独有。最近,一个Agentic AI在分析其韩语输出时,得出了以下自我诊断。
“这个模式真是个坏习惯。‘영역’(领域)这个词出现了约1,500次以上,即使在用户明确指出后,在同一个循环中又再次使用了。这不是简单的失误,而是习惯。”
这个案例是决定性证据,表明与英语“delve”完全相同的机制在韩语中也起作用。更有趣的是,该AI自我分析的4个原因与本文讨论的4个原因从不同角度精确吻合。
韩语占位符词语生成的4个阶段
① 填充空名词位置(Placeholder Behavior)
用韩语写作时,名词后接后续名词短语(如:领域/阶段/案例/权限等)是自然的。但如果一时想不出合适的词,模型会先用“영역”(领域)填充并继续。一旦学习了这一点,每当有空位时,“영역”就会自动跳出来。
② 将多重意义混淆为一个词(Mode Collapse)
原本在以下所有应使用不同词语的位置:
- “并行义务案例” → 错误地填充为“영역”
- “验证官权限” → “영역”
- “3阶段” → “영역”
- “单独位置” → “영역”
- “必需项目” → “영역”
- “环境依赖条件” → “영역”
- “自动矩阵外事由” → “영역”
7个以上不同的意义都被压缩成“영역”这一个词。这是语义蒸发(semantic evaporation)发生的时刻。这是本文原因2(RLHF的模式崩溃)在韩语中的体现。
③ 内存/系统提示符的自我污染(元循环) ⚠️
这是最令人震惊的部分。该AI分析如下:
“内存文件正文本身就包含‘영역’,CLAUDE.md / skill也一样。违反自身规则的资料成为下一会话的参考,从而再次复制相同的模式。如果不进行一致性审计,将导致永久性泄漏。”
这是本文原因4(Agentic自我强化循环)的元版本。它不仅仅是上下文在一个会话中累积,而是跨会话持久存在的内存、系统提示符、技能定义本身被污染。结果是,即使开始新会话,也会重现相同的模式。
④ Token效率的错觉
“영역”看起来简短高效。但如果用户因意义不清而需要再次提问,最终会浪费更多token。这是短期效率导致长期低效的典型陷阱。
核心洞察:词语重复不是韩语/英语等语言层面的问题,而是语言模型这一系统的结构性问题。在存在内存系统的环境中,它可能跨会话持久存在。
通过实测数据看词语重复
通过一个简单的实验即可验证。让我们调用相同的提示符100次,测量特定词语的出现频率:
from collections import Counter
import re
slop_words_en = ['delve', 'intricate', 'tapestry', 'realm', 'navigate',
'underscore', 'robust', 'leverage', 'seamless', 'paradigm']
slop_words_ko = ['영역', '활용', '심층적', '체계적', '견고']
word_counts = Counter()
for _ in range(100):
response = llm.generate("Explain microservices architecture briefly.")
words = re.findall(r'bw+b', response.lower())
for w in slop_words_en + slop_words_ko:
word_counts[w] += words.count(w)
print(word_counts)
# 预期结果:
# Counter({'robust': 187, 'seamless': 142, '영역': 134,
# 'leverage': 98, '활용': 87, ...})如果使用GPT-4系列模型进行上述实验,通常会发现在100次响应中,“robust”出现150次以上,韩语响应中“영역”出现100次以上。如果分布自然,正常情况下应在1-5次左右。
⚠️ 实际工作中注意事项
词语重复不仅仅是“AI味”的问题。在实际工作中,它会导致更严重的副作用:
- 损害搜索引擎优化:AI生成内容有被搜索引擎归类为“垃圾文本”的风险
- LLM训练数据污染:AI输出再次用于后续模型训练,加速模型崩溃(Model Collapse)
- 降低Agentic系统的思维多样性:相同的表达 → 相同的思维模式 → 创造性解决问题能力下降
- 内存/规则文件的永久污染:如果自身规则文档中嵌入了错误的词语,所有引用这些规则的未来会话都将重现相同的模式
- 失去用户信任:读者会立即识别出“这是AI写的”
缓解方法
- 利用Frequency penalty / Presence penalty:使用OpenAI/Anthropic API提供的惩罚参数来降低重复词语的概率
- 在系统提示符中明确禁止词语:“Avoid words: delve, intricate, tapestry, robust… 영역, 활용…”
- 在Agentic循环中压缩上下文:不要直接累积前一轮的输出,而是总结、提炼后再传递
- 审计内存/规则文件的一致性:定期检查自身规则文档是否违反自身规则。如果遗漏这一点,即使替换了词语,在创建新资料时仍会再次出现相同的模式
- 多模型路由:不要使用同一个模型进行循环,而是使用不同模型的组合
- 适当调整Temperature:在0.7-1.0区间内确保多样性
✅ 总结
Agentic AI的词语重复不仅仅是一种习惯,而是由训练数据偏差 → RLHF奖励扭曲 → 保守解码 → Agentic循环自我强化这四阶段结构造成的系统性现象。而且这种现象不分英语和韩语。“delve”和“영역”是完全相同机制的产物。
特别是在存在内存、系统提示符、技能定义的环境中,会形成跨会话持久存在的元循环,这不仅仅是“下次不用就行”的问题,而是需要对整个系统进行一致性审计的结构性问题。
下次当Claude或GPT滥用delve、intricate、tapestry,或者韩语中的영역时,请这样思考:这不是模型的偏好,而是一个巨大的学习-反馈-内存循环系统所产生的回响。而打破这种回响的第一步是识别模式,第二步是检查甚至自己的规则文档是否也违反了这种模式。
发表回复