If clients receive errors every time you scale-in,
it’s not a design problem, but a termination strategy problem.
>

>
The narrative of Graceful Shutdown, completing all tasks just before termination and safely concluding — the heart of a sailor tidying up and departing orderly amidst chaos.
🎯 What this article covers
- What happens to in-flight requests when a Pod terminates
- How SIGTERM and Graceful Shutdown work
- How to make termination safe with the terminationGracePeriodSeconds setting
- How to use preStop Hook
- Recommended timeout strategies in an MSA environment
📌 Introduction / Background
Kubernetes’ HPA (Horizontal Pod Autoscaler) automatically reduces the number of Pods when traffic decreases. This is an excellent feature.
However, a practical problem arises here.
“What happens to requests being processed by a Pod the moment it scales down?”
Without any handling, the following occurs:
- HPA decides to terminate a Pod
- The Pod is busy processing API requests
- The Pod is forcibly SIGKILLed and disappears immediately
- The client receives no response and the TCP connection is broken
- The client waits until timeout and then receives a Connection reset or 502/504 error
This article addresses how to solve this problem with a Graceful Shutdown strategy.
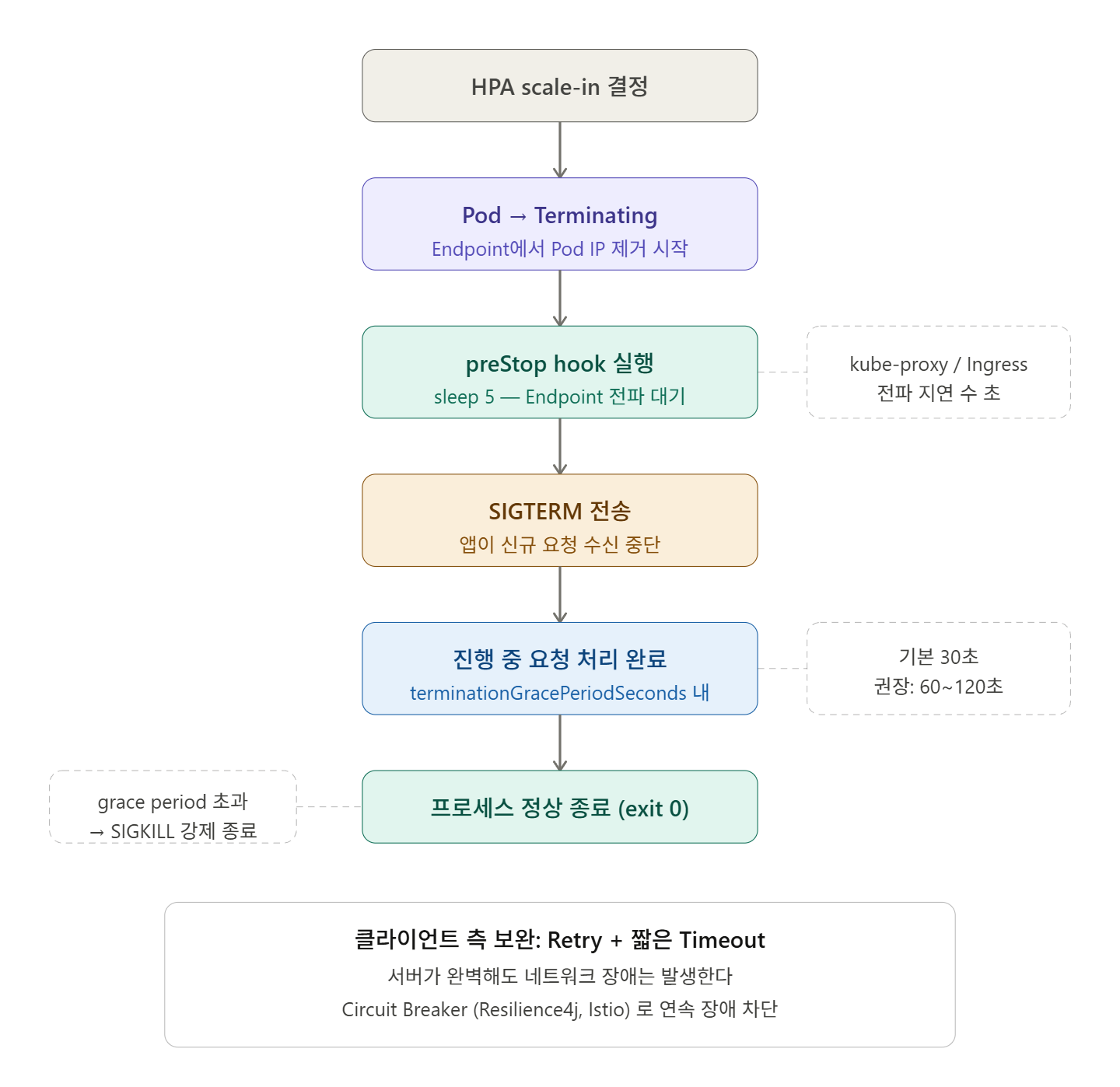
🔍 Understanding Kubernetes Pod Termination Flow
When a Pod is deleted, Kubernetes operates in the following sequence:
1. kubectl delete pod / HPA scale-in 명령
2. Pod 상태 → Terminating
3. Endpoint에서 해당 Pod IP 제거 (더 이상 새 요청을 받지 않음)
4. Container에 SIGTERM 신호 전송
5. terminationGracePeriodSeconds 동안 대기 (기본 30초)
6. 기간 내 종료 안 되면 SIGKILL로 강제 종료The key here is that steps 3 and 4 do not happen simultaneously.
There is a propagation delay of several seconds for kube-proxy and Ingress Controller to detect Endpoint changes. This means new requests can still come in even after SIGTERM is received.
💡 Solution 1 — SIGTERM Handling + terminationGracePeriodSeconds
This is the most fundamental solution. When an application receives SIGTERM, it should not die immediately, but instead finish processing existing requests before shutting down.
Application-level handling (Node.js example)
const server = app.listen(3000);
process.on('SIGTERM', () => {
console.log('SIGTERM received. Closing server gracefully...');
// Do not accept new connections, wait for existing connections to complete processing
server.close(() => {
console.log('All connections closed. Exiting.');
process.exit(0);
});
// Safety net: Force shutdown after 25 seconds (shorter than gracePeriod)
setTimeout(() => {
console.error('Forced exit after timeout');
process.exit(1);
}, 25000);
});Java Spring Boot example
With Spring Boot 2.3 or later, you can enable Graceful Shutdown with a single line of configuration.
# application.yaml
server:
shutdown: graceful # Default is immediate
spring:
lifecycle:
timeout-per-shutdown-phase: 30sKubernetes Deployment Configuration
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-api
spec:
template:
spec:
# Grace period until SIGKILL (default 30 seconds)
terminationGracePeriodSeconds: 60
containers:
- name: my-api
image: my-api:latest
lifecycle:
preStop:
exec:
# Sleep to cover Endpoint propagation delay
command: ["/bin/sh", "-c", "sleep 5"]💡 Role of preStop hook: It runs just before SIGTERM is sent. Adding a ‘sleep 5’ prevents new requests from coming in while kube-proxy removes the Endpoint. This may seem minor, but it’s a very effective pattern in practice.
💡 Solution 2 — MSA Standard Pattern: Retry + Short Timeout
This is another recommended approach in an MSA (Microservices Architecture) environment.
While it’s important to make the server perfect, clients should also be designed to handle transient failures themselves.
The core principles are:
- Short Timeout: Detect failures quickly without waiting too long
- Retry with Backoff: Retry at intervals upon failure
- Circuit Breaker: Block requests on consecutive failures (e.g., Resilience4j, Istio)
// Resilience4j Retry configuration example
RetryConfig config = RetryConfig.custom()
.maxAttempts(3)
.waitDuration(Duration.ofMillis(500))
.retryOnException(e -> e instanceof ConnectException
|| e instanceof SocketTimeoutException)
.build();The advantage of this approach is that it can handle various situations beyond just Pod termination, such as temporary network outages, redeployments, and node failures.
💻 Recommended Combination in Practice
Combining both approaches results in the most stable configuration.
spec:
template:
spec:
terminationGracePeriodSeconds: 60 # Server-side grace period
containers:
- name: my-api
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 5"] # Wait for Endpoint propagation
# Control traffic reception with Readiness Probe
readinessProbe:
httpGet:
path: /health/ready
port: 3000
initialDelaySeconds: 5
periodSeconds: 5And in the application:
- Create a /health/ready endpoint that returns 503 upon receiving SIGTERM
- Continue processing existing requests
- Terminate the process after all requests are completed
This creates a clean flow: readinessProbe fails → kube-proxy removes Endpoint → new requests are blocked → existing requests complete → Pod terminates.
⚠️ Cautions / Common Mistakes
🔴 Setting terminationGracePeriodSeconds too long
Setting it too long, like 600 seconds (10 minutes), drastically increases deployment time. Generally, 60-120 seconds is appropriate.
🔴 Relying only on SIGTERM without preStop sleep
Due to kube-proxy’s Endpoint propagation delay, new requests can still come in immediately after SIGTERM. A `preStop: sleep 5` is essential.
🔴 Beware of languages/frameworks without SIGTERM handlers
Some older frameworks or containers running shell scripts ignore SIGTERM by default. The process must be run as PID 1 using the `exec` command for SIGTERM to be delivered.
# Bad example — SIGTERM goes to sh, not delivered to app
CMD ["sh", "-c", "node server.js"]
# Correct example — node becomes PID 1 and receives SIGTERM directly
CMD ["node", "server.js"]🔴 Long-polling / WebSocket require special handling
Unlike HTTP requests, persistent connections may not naturally terminate within the grace period. These connection types require explicit logic to close connections upon receiving SIGTERM.
✅ Summary / Conclusion
The problem of lost in-flight requests when a Pod terminates in Kubernetes is not a design flaw, but a configuration issue. Applying the following three points can cover most situations.
| Layer | Setting | Purpose |
| Kubernetes | terminationGracePeriodSeconds: 60 | Secure SIGKILL grace period |
| Kubernetes | preStop: sleep 5 | Wait for Endpoint propagation delay |
| Application | Implement SIGTERM handler | Complete existing requests then terminate |
| Client | Retry + Short Timeout | Automatic recovery from transient failures |
A system equipped with all four of these will virtually eliminate situations where clients receive errors during scale-in.
As a next step, introducing a Service Mesh like Istio or Linkerd can automatically handle all these patterns at the infrastructure level without application code changes.
Leave a Reply