スケールインするたびにクライアントがエラーを受け取るなら、
それは設計の問題ではなく、終了戦略の問題だ。
>

>
終了直前にすべての作業を完了し、安全に終えるGraceful Shutdownの物語 — 混沌の中でも秩序をもって整理し、去っていく船乗りの心。
🎯 この記事で扱うこと
- Podが終了する際に実行中のリクエストに何が起こるか
- SIGTERMとGraceful Shutdownの動作原理
- terminationGracePeriodSeconds設定で終了を安全にする方法
- preStop Hookの活用法
- MSA環境で推奨されるタイムアウト戦略
📌 導入 / 背景
KubernetesのHPA(Horizontal Pod Autoscaler)は、トラフィックが減少するとPod数を自動的に減らしてくれる。これは非常に優れた機能だ。
しかし、ここで現実的な問題が生じる。
“Podが減少する瞬間、そのPodで処理中だったリクエストはどうなるのか?”
何も処理しないと以下のようになる。
- HPAがPodの終了を決定
- Pod内でAPIリクエストを懸命に処理中
- Podが強制的にSIGKILLを受け、即座に消滅
- クライアントは応答を受け取れず、TCP接続が切断
- クライアントはタイムアウトまで待機し、Connection resetまたは502/504エラーを受信
この記事では、この問題をGraceful Shutdown(優雅な終了)戦略で解決する方法を扱う。
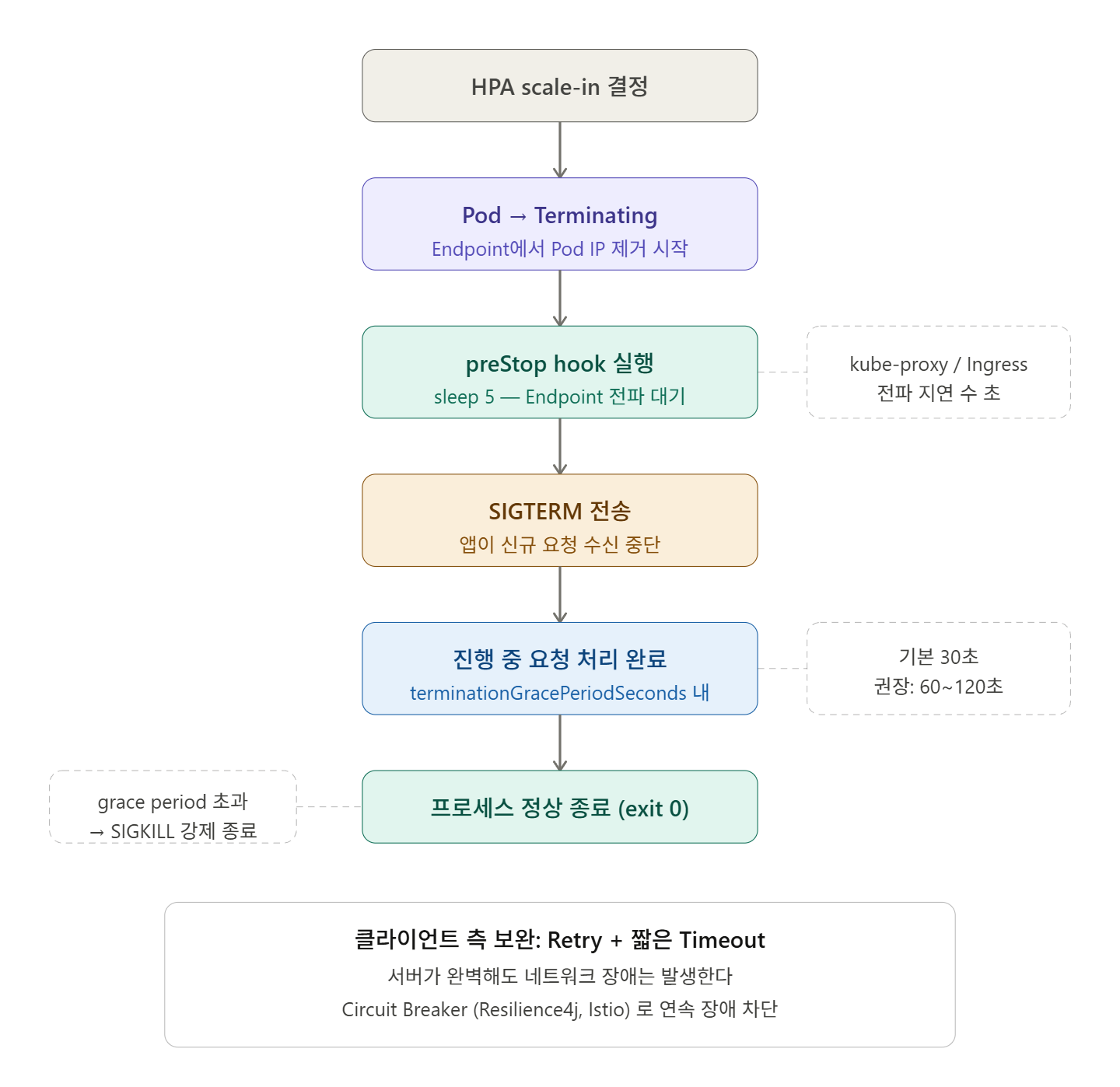
🔍 Kubernetes Pod終了フローの理解
Podが削除される際、Kubernetesは以下の順序で動作する。
1. kubectl delete pod / HPA scale-in 명령
2. Pod 상태 → Terminating
3. Endpoint에서 해당 Pod IP 제거 (더 이상 새 요청을 받지 않음)
4. Container에 SIGTERM 신호 전송
5. terminationGracePeriodSeconds 동안 대기 (기본 30초)
6. 기간 내 종료 안 되면 SIGKILL로 강제 종료ここで重要なのは、3番と4番が同時に発生しないという点だ。
kube-proxyとIngress ControllerがEndpointの変更を検知するまでに数秒の伝播遅延(propagation delay)がある。つまり、SIGTERMを受け取った瞬間でも新しいリクエストが入り込む可能性があるということだ。
💡 解決策 1 — SIGTERMハンドリング + terminationGracePeriodSeconds
最も根本的な解決策だ。アプリケーションがSIGTERMを受け取ったら、すぐに終了せず、処理中のリクエストを完了させてから終了するようにする。
アプリケーションレベル処理 (Node.jsの例)
const server = app.listen(3000);
process.on('SIGTERM', () => {
console.log('SIGTERM received. Closing server gracefully...');
// 新しい接続は受け付けず、既存の接続の処理完了を待機
server.close(() => {
console.log('All connections closed. Exiting.');
process.exit(0);
});
// 安全装置: 25秒後に強制終了 (gracePeriodより短く)
setTimeout(() => {
console.error('Forced exit after timeout');
process.exit(1);
}, 25000);
});Java Spring Bootの例
Spring Boot 2.3以降では、設定1行でGraceful Shutdownを有効にできる。
# application.yaml
server:
shutdown: graceful # デフォルトはimmediate
spring:
lifecycle:
timeout-per-shutdown-phase: 30sKubernetes Deployment設定
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-api
spec:
template:
spec:
# SIGKILLまでの猶予時間 (デフォルト30秒)
terminationGracePeriodSeconds: 60
containers:
- name: my-api
image: my-api:latest
lifecycle:
preStop:
exec:
# Endpoint伝播遅延をカバーするためのsleep
command: ["/bin/sh", "-c", "sleep 5"]💡 preStop hookの役割: SIGTERMが送信される直前に実行される。sleep 5を設定することで、kube-proxyがEndpointを削除する間に新しいリクエストが入り込むのを防ぐ。些細に見えるが、現場では非常に効果的なパターンだ。
💡 解決策 2 — MSA標準パターン: リトライ + 短いタイムアウト
MSA(マイクロサービスアーキテクチャ)環境で推奨されるもう一つのアプローチだ。
サーバーを完璧にすることも重要だが、クライアントも一時的な障害に自ら対応できるように設計する必要がある。
主要な原則は以下の通りだ。
- タイムアウトを短く: 長く待たずに素早く失敗を検知
- バックオフ付きリトライ: 失敗時に一定間隔で再試行
- サーキットブレーカー: 連続失敗時にリクエストを遮断 (Resilience4j, Istioなど)
// Resilience4j リトライ設定例
RetryConfig config = RetryConfig.custom()
.maxAttempts(3)
.waitDuration(Duration.ofMillis(500))
.retryOnException(e -> e instanceof ConnectException
|| e instanceof SocketTimeoutException)
.build();この方式の利点は、Pod終了以外にも、ネットワークの一時的な障害、再デプロイ、ノード障害など、様々な状況に対応できる点だ。
💻 実践推奨の組み合わせ
この2つを組み合わせると、最も安定した構成になる。
spec:
template:
spec:
terminationGracePeriodSeconds: 60 # サーバー側の猶予時間
containers:
- name: my-api
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 5"] # Endpoint伝播待機
# Readiness Probeでトラフィック受信を制御
readinessProbe:
httpGet:
path: /health/ready
port: 3000
initialDelaySeconds: 5
periodSeconds: 5そしてアプリケーションでは:
- /health/readyエンドポイントを作成し、SIGTERM受信時に503を返す
- 既存の処理中のリクエストは継続して処理
- すべてのリクエスト完了後にプロセスを終了
これにより、readinessProbeが失敗 → kube-proxyがEndpointを削除 → 新しいリクエストの流入を遮断 → 既存リクエストの処理完了 → Pod終了というクリーンなフローが作成される。
⚠️ 注意事項 / よくある間違い
🔴 terminationGracePeriodSecondsを長すぎに設定
600秒(10分)のように長く設定すると、デプロイ時間が極端に長くなる。一般的には60〜120秒が適切だ。
🔴 preStop sleepなしでSIGTERMだけを信頼
kube-proxyのEndpoint伝播遅延のため、SIGTERM直後でも新しいリクエストが入り込む。preStop: sleep 5程度は必ず入れるべきだ。
🔴 SIGTERMハンドラーのない言語/フレームワークに注意
一部の古いフレームワークやシェルスクリプトで実行されるコンテナは、SIGTERMをデフォルトで無視する。execコマンドでプロセスをPID 1として実行する必要がある。
# 悪い例 — SIGTERMがshに渡され、アプリに伝達されない
CMD ["sh", "-c", "node server.js"]
# 正しい例 — nodeがPID 1になり、SIGTERMを直接受信
CMD ["node", "server.js"]🔴 Long-polling / WebSocketは別途処理が必要
HTTPリクエストとは異なり、持続的な接続はgrace period内に自然終了しない場合がある。これらの接続タイプは、SIGTERM受信時に明示的に接続を閉じるロジックが必要だ。
✅ まとめ / 締めくくり
KubernetesでPodが終了する際に進行中のリクエストが失われる問題は、設計上の欠陥ではなく、設定の問題だ。以下の3つを適用すれば、ほとんどの状況をカバーできる。
| レイヤー | 設定 | 目的 |
| Kubernetes | terminationGracePeriodSeconds: 60 | SIGKILL猶予時間の確保 |
| Kubernetes | preStop: sleep 5 | Endpoint伝播遅延の待機 |
| アプリケーション | SIGTERMハンドラーの実装 | 既存リクエスト完了後に終了 |
| クライアント | リトライ + 短いタイムアウト | 一時的な障害からの自動復旧 |
これら4つすべてを備えたシステムであれば、スケールイン過程でクライアントがエラーを受け取る状況は事実上発生しない。
次のステップとしては、IstioやLinkerdのようなService Meshを導入すれば、これらのパターンすべてをアプリケーションコードの変更なしにインフラレベルで自動的に処理できる。
コメントを残す