iptablesは世界を変えるスケールに対応できませんでした。eBPFはカーネルそのものを変えました。
>

🎯 この記事で扱うこと
- Kubernetes CNIの歴史: Flannel → Calico → Ciliumへと続く世代交代
- iptablesの根本的な限界とeBPFがそれをどのように克服したか
- Google、AWS、Azure、AlibabaがCiliumを選択した実際の理由
- Ciliumが単なるCNIを超えて「ネットワーキングプラットフォーム」になった過程
- 2026年現在、デファクトスタンダードとなった決定的な証拠
📌 導入 — 「CNIって一体何がそんなに重要なんだ?」
Kubernetesを初めて学ぶとき、CNI(Container Network Interface)は「ただインストールするもの」くらいに感じられます。
kubectl apply -f flannel.yml の一行で、Pod同士が通信できるようになります。
しかし、クラスター規模が数百ノード、数千サービスに拡大すると、現実は変わります。ネットワーク遅延が異常に増加し、ポリシー変更が遅くなり、デバッグができなくなります。この時点で、運用チームは共通の結論に達します。
CNIの選択を間違えた。
これが、多くの企業がFlannelからCalicoへ、そしてCiliumへと移行した理由です。そして現在、Ciliumは2025 CNCF State of Kubernetes Networkingレポートによると、CNIデプロイメントの60%以上を占めるデファクトスタンダードとなりました。どのようにしてここまで来たのでしょうか?
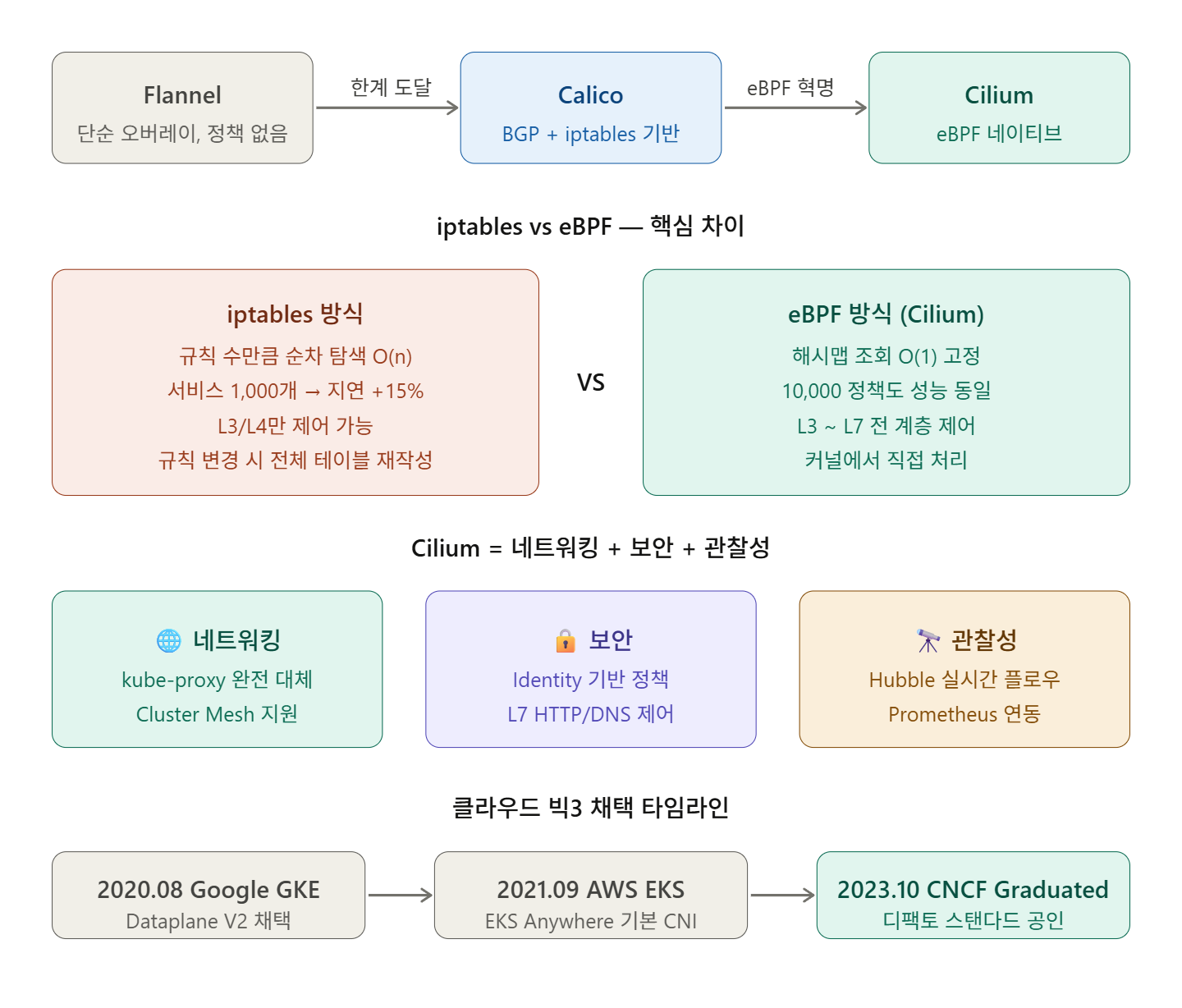
🔍 第1世代CNIの時代 — FlannelとCalico
Flannel: 「とにかく接続できればいい」
初期のKubernetesプラットフォームを構築する際、Flannelは自然な選択でした。最も成熟しており、依存関係が少なく、インストールが簡単で、ベンチマークでも高い性能を示しました。
Flannelの哲学は単純でした。VXLANオーバーレイですべてのPodが相互に通信できるフラットなネットワークを作成する。それだけです。
- ネットワークポリシー?ありません。
- 可観測性?ありません。
- セキュリティ?自分で対応してください。
小規模クラスターでは十分でした。しかし、トラフィックが増加するにつれて、iptablesとnetfilterの限界が露呈し始めました。
Calico: 「BGPで本格的にいこう」
Calicoはインターネットのバックボーンを動かすのと同じプロトコルであるBGPをルーティングに使用し、2016年からエンタープライズの標準的な選択肢となりました。
Calicoはネットワークポリシーもサポートしました。セキュリティチームが望むL3/L4レベルのトラフィック制御が可能になりました。しかし、問題がありました。
iptablesは線形に動作します。
iptables方式では、ポリシーが増えるにつれてルールが順次評価されるため、1,000個のポリシーがある環境では10〜15%のレイテンシーオーバーヘッドが発生する可能性があります。
サービスが数百を超えると、iptablesのルールテーブルは何万行にも膨れ上がります。ルール変更時にはテーブル全体を書き直す必要があり、この過程で一時的なトラフィック断絶が発生します。大規模クラスターでは、これは災害です。
🔍 Ciliumの登場 — eBPFという賭け
2015〜2016: 「カーネルを変えてしまおう」
Ciliumは2015年12月、後にIsovalentを設立する開発者たちによって誕生し、2016年のLinuxConでeBPFとXDPを活用した高速IPv6コンテナネットワーキングプロジェクトとして初めて公開されました。
当時は賭けでした。ほとんどのCNIがiptables上で動作するのが常識だった中、Ciliumは最初からeBPFに全力を注ぎました。CiliumはeBPFがクラウドネイティブネットワーキングの未来になると賭け、最初からeBPFベースのデータプレーンを構築しました。
eBPFとは何か?
eBPF(extended Berkeley Packet Filter)を簡単に説明するとこうなります。
従来、カーネル機能を変更するには、カーネルソースを修正して再コンパイルする必要があり、数ヶ月かかる作業でした。eBPFはカーネルを修正せずに、カーネル内にコードを安全に注入する技術です。ネットワークパケットがカーネルを通過するまさにその地点で、望むロジックを実行できます。
eBPFはカーネル内で動作するため、ユーザースペースとカーネルスペース間の高価なコンテキストスイッチングを回避でき、結果としてレイテンシー、スループット、性能効率が大幅に向上します。
2018〜22020: 本格的な検証
2018年4月にCilium 1.0が初の安定バージョンとしてリリースされ、2019年11月にはeBPFベースのネットワーク可観測性を提供するHubbleがローンチされました。
そして、決定的な出来事が起こりました。
2020年8月、GoogleがGKEの新しいデータプレーンとしてCiliumを選択しました。
Google CloudはCiliumを採用してGKE Dataplane V2を構築し、eBPFを活用してkube-proxyのiptablesベースのサービスルーティングのような従来のカーネルネットワーキングパスを迂回することで、高効率なパケット処理を実現しました。
Googleが選択したことは、業界全体に強力なシグナルとなりました。
🔍 なぜクラウドビッグ3がすべてCiliumを選択したのか
Google GKE
2024年、GKEは最大65,000ノードのクラスターをサポートすると発表しましたが、この途方もない拡張性は、GKE Dataplane V2の堅牢で最適化されたアーキテクチャのおかげで大部分が可能になりました。GKE Dataplane V2はCiliumベースです。
AWS EKS Anywhere
2021年9月、AWSはEKS AnywhereのネットワーキングとセキュリティのためにCiliumを選択しました。
Alibaba Cloud ACK
Alibabaは、既存のvethベースのコンテナネットワーキングモデルにおいて、名前空間間のパケット切り替え時にかなりのオーバーヘッドが発生すること、およびデフォルトのiptablesベースのサービスモードでルール増加に伴う高いコスト問題を認識していました。Ciliumを通じて、これら2つの主要な問題を解決することができました。
世界の3大クラウド事業者すべてが同じ結論に達しました。iptablesは限界に達し、eBPFだけが答えでした。
🔍 Ciliumが単なるCNIを超えた理由
Ciliumを単に「高速なCNI」と見てはいけません。Ciliumは3つの領域を一つに統合しました。
1️⃣ ネットワーキング — kube-proxyの完全代替
CiliumはeBPFの効率的なハッシュテーブルを使用してkube-proxyを完全に代替し、ソケットレベルでサービス接続を書き換えることで、パケットごとのNATオーバーヘッドを排除します。
kube-proxyがなければ?iptablesのルール爆発がなくなります。10,000個のネットワークポリシーがあるクラスターと10個のクラスターの性能は同じです。O(1)のハッシュマップ検索だからです。
2️⃣ セキュリティ — IPではなくIdentityベース
従来のCNIはIPアドレスに基づいてポリシーを適用します。問題はPodのIPが頻繁に変わることです。CiliumはKubernetesラベルをIdentityとしてポリシーを適用します。
さらに、CiliumはL7ポリシーをサポートします。
# HTTPメソッド、パスまで制御するL7ポリシーの例
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: api-http-policy
namespace: production
spec:
endpointSelector:
matchLabels:
app: backend-api
ingress:
- fromEndpoints:
- matchLabels:
app: frontend
toPorts:
- ports:
- port: "8080"
protocol: TCP
rules:
http:
- method: GET
path: "/api/.*" # GET /api/* のみ許可
- method: POST
path: "/api/data" # POST /api/data のみ許可
# その他すべてのリクエストはブロックこれは従来のiptablesでは不可能だったL7レベルの制御です。サービスメッシュなしでこれが可能です。
3️⃣ 可観測性 — Hubble
ネットワーク問題のデバッグ地獄を経験したことがあるなら、Hubbleがいかに強力であるかを知るでしょう。
Hubbleは個々のネットワークパケットフローを観察し、トラフィックの許可/拒否に関するネットワークポリシーの決定を確認し、Kubernetesサービスがどのように通信しているかをサービスマップで表示します。このデータはPrometheus、OpenTelemetry、Grafanaにエクスポートできます。
iptablesでトラフィックがなぜブロックされたのかを追跡していた時代と比較すると、世界は変わりました。
💻 Ciliumのインストールと基本確認
# Cilium CLIのインストール
curl -L --remote-name-all
https://github.com/cilium/cilium-cli/releases/latest/download/cilium-linux-amd64.tar.gz
tar xzvf cilium-linux-amd64.tar.gz
sudo mv cilium /usr/local/bin/
# クラスターにCiliumをインストール (kube-proxyの代替を含む)
cilium install
--set kubeProxyReplacement=true
--set hubble.relay.enabled=true
--set hubble.ui.enabled=true
# インストール状況の確認
cilium status
# kube-proxyの代替状況を確認
kubectl exec -n kube-system ds/cilium -- cilium status | grep KubeProxyReplacement
# KubeProxyReplacement: True
# Hubbleでリアルタイムトラフィックを観察
hubble observe --follow --namespace production⚠️ 注意事項 / よくある間違い
カーネルバージョンの確認必須
CiliumのインストールにはLinuxカーネル5.10以上(またはRHEL 8.10基準で4.18以上)が必要であり、eBPFサポートがカーネル設定で有効になっている必要があります。古いOSでCiliumをデプロイすると、機能が静かに無効化されます。
メモリオーバーヘッドの計画
Ciliumエージェントは、エンドポイントとポリシーの数に応じて、ノードあたり150〜250MBのメモリを消費します。100ノードのクラスターであれば、最低15〜25GBの追加メモリを想定する必要があります。ただし、Ciliumのスループット向上により、全体のノード数を10〜15%削減できるという運用事例もあります。
小規模クラスターでの費用対効果
200ノード未満、500サービス以下のクラスターでは、どちらのCNIも十分に機能し、性能差が決定的な要因にはなりません。学習環境であれば、Flannelから始めるのも悪くありません。
✅ まとめ — なぜCiliumが標準になったのか
Ciliumの台頭は、単に「より高速なCNI」が登場したからではありません。それは根本的なアーキテクチャの転換でした。
| 区分 | 従来の方式 (iptables) | Cilium (eBPF) |
| 性能特性 | ルール数に比例して線形に低下 | ルール数に関わらずO(1) |
| ポリシーレイヤー | L3/L4 | L3 ~ L7 |
| kube-proxy | 別途コンポーネントが必要 | eBPFで完全代替 |
| 可観測性 | tcpdump、ログファイル | Hubble (リアルタイムフロー) |
| サービスメッシュ | サイドカーが必要 | サイドカーなしで可能 |
Ciliumは2023年10月にCNCF Graduatedプロジェクトとして卒業し、21,000以上のGitHubスターと900人以上のコントリビューターを擁するコミュニティは、他のどのCNIよりも急速に成長しています。
eBPFネイティブの特性は後から追加された機能ではなく、アーキテクチャの根本であり、その性能と可観測性の特性はアドオンではなく設計自体から生まれています。
次のステップとしては、Hubble UIを通じたサービスマップの探索、CiliumNetworkPolicyによるL7ポリシーの実践、Tetragonを活用したランタイムセキュリティの探索をお勧めします。
コメントを残す