如果每次缩容时客户端都收到错误,
那不是设计问题,而是终止策略问题。
>

>
优雅停机的叙事,在终止前完成所有任务并安全结束 — 就像水手在混乱中井然有序地收拾行囊,然后离开。
🎯 本文涵盖内容
- Pod 终止时正在处理的请求会发生什么
- SIGTERM 和优雅停机的工作原理
- 如何通过 terminationGracePeriodSeconds 设置安全终止
- preStop Hook 的使用方法
- MSA 环境中推荐的超时策略
📌 引入 / 背景
Kubernetes 的 HPA (Horizontal Pod Autoscaler) 会在流量减少时自动缩减 Pod 数量。这是一个非常出色的功能。
但这里出现了一个实际问题。
“Pod 缩减的那一刻,该 Pod 中正在处理的请求会怎样?”
如果不做任何处理,就会发生以下情况:
- HPA 决定终止 Pod
- Pod 正在努力处理 API 请求
- Pod 被强制 SIGKILL 并立即消失
- 客户端收不到响应,TCP 连接断开
- 客户端等待直到超时,然后收到 Connection reset 或 502/504 错误
本文将探讨如何通过优雅停机 (Graceful Shutdown) 策略解决此问题。
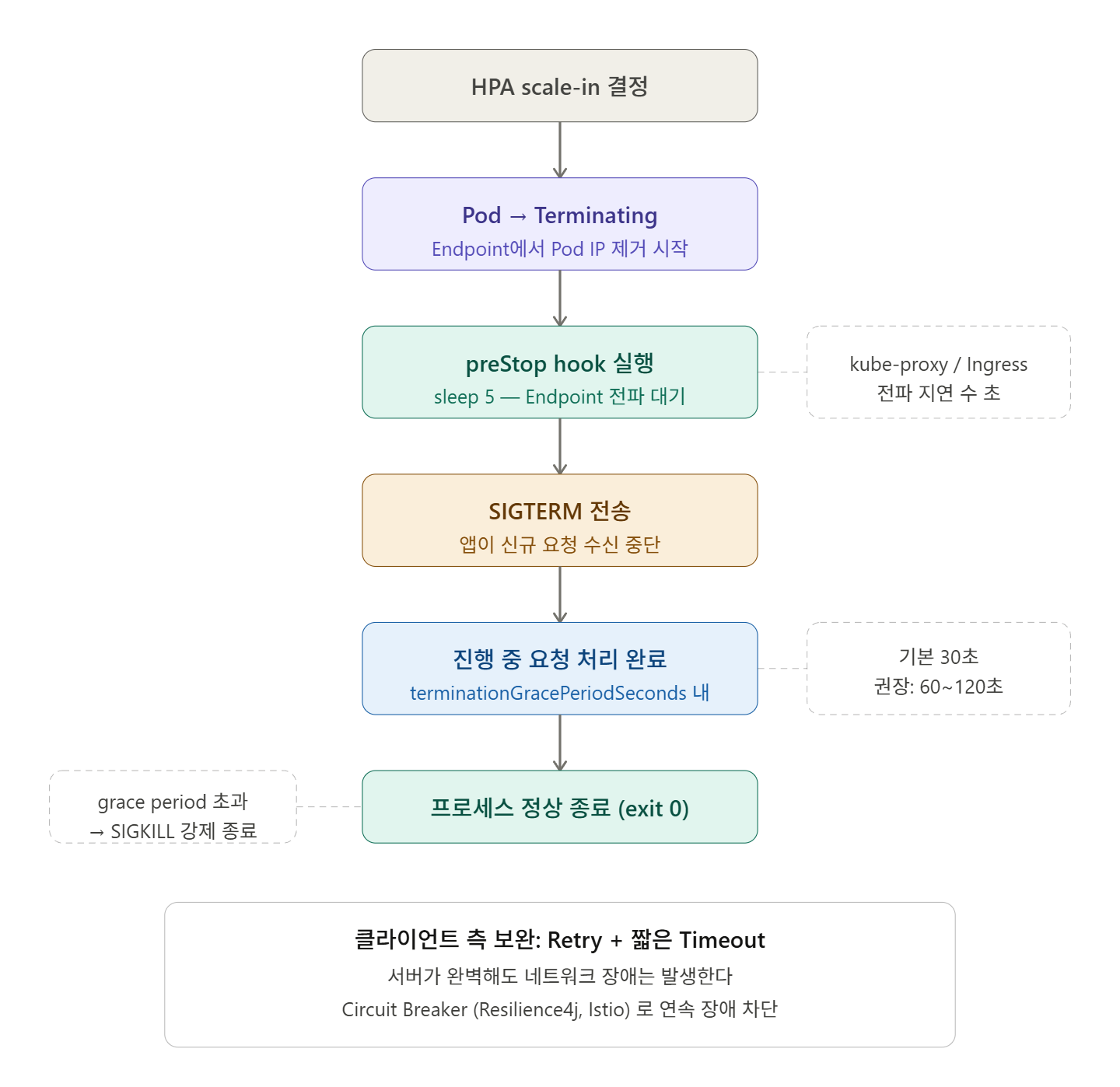
🔍 理解 Kubernetes Pod 终止流程
当 Pod 被删除时,Kubernetes 按以下顺序操作:
1. kubectl delete pod / HPA scale-in 명령
2. Pod 상태 → Terminating
3. Endpoint에서 해당 Pod IP 제거 (더 이상 새 요청을 받지 않음)
4. Container에 SIGTERM 신호 전송
5. terminationGracePeriodSeconds 동안 대기 (기본 30초)
6. 기간 내 종료 안 되면 SIGKILL로 강제 종료这里的核心是第 3 步和第 4 步不会同时发生。
kube-proxy 和 Ingress Controller 检测 Endpoint 变更存在数秒的传播延迟 (propagation delay)。这意味着即使在收到 SIGTERM 的那一刻,新的请求仍然可能进入。
💡 解决方案 1 — SIGTERM 处理 + terminationGracePeriodSeconds
这是最根本的解决方案。当应用程序收到 SIGTERM 时,它应该不要立即终止,而是完成正在处理的请求后再关闭。
应用程序级别处理 (Node.js 示例)
const server = app.listen(3000);
process.on('SIGTERM', () => {
console.log('SIGTERM received. Closing server gracefully...');
// 不接受新连接,等待现有连接处理完成
server.close(() => {
console.log('All connections closed. Exiting.');
process.exit(0);
});
// 安全措施:25秒后强制终止(短于gracePeriod)
setTimeout(() => {
console.error('Forced exit after timeout');
process.exit(1);
}, 25000);
});Java Spring Boot 示例
Spring Boot 2.3 及更高版本可以通过一行配置启用优雅停机。
# application.yaml
server:
shutdown: graceful # 默认值是 immediate
spring:
lifecycle:
timeout-per-shutdown-phase: 30sKubernetes Deployment 配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-api
spec:
template:
spec:
# SIGKILL之前的宽限期(默认30秒)
terminationGracePeriodSeconds: 60
containers:
- name: my-api
image: my-api:latest
lifecycle:
preStop:
exec:
# 睡眠以覆盖 Endpoint 传播延迟
command: ["/bin/sh", "-c", "sleep 5"]💡 preStop hook 的作用: 它在 SIGTERM 发送之前执行。设置 sleep 5 可以防止在 kube-proxy 移除 Endpoint 期间有新请求进入。这看起来微不足道,但在实际工作中是非常有效的模式。
💡 解决方案 2 — MSA 标准模式:重试 + 短超时
这是 MSA (微服务架构) 环境中推荐的另一种方法。
虽然完善服务器很重要,但客户端也应设计成能够自行应对临时故障。
核心原则如下:
- 短超时: 不长时间等待,快速检测失败
- 带退避的重试: 失败时以一定间隔重试
- 熔断器: 连续失败时阻止请求 (例如 Resilience4j, Istio 等)
// Resilience4j 重试配置示例
RetryConfig config = RetryConfig.custom()
.maxAttempts(3)
.waitDuration(Duration.ofMillis(500))
.retryOnException(e -> e instanceof ConnectException
|| e instanceof SocketTimeoutException)
.build();这种方法的优点是,它不仅可以应对 Pod 终止,还可以应对网络临时故障、重新部署、节点故障等各种情况。
💻 实践推荐组合
将这两种方法结合起来,可以形成最稳定的配置。
spec:
template:
spec:
terminationGracePeriodSeconds: 60 # 服务器端宽限期
containers:
- name: my-api
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 5"] # 等待 Endpoint 传播
# 使用 Readiness Probe 控制流量接收
readinessProbe:
httpGet:
path: /health/ready
port: 3000
initialDelaySeconds: 5
periodSeconds: 5在应用程序中:
- 创建 /health/ready 端点,在收到 SIGTERM 时返回 503
- 继续处理现有请求
- 所有请求完成后终止进程
这样就形成了一个清晰的流程:readinessProbe 失败 → kube-proxy 移除 Endpoint → 阻止新请求流入 → 现有请求处理完成 → Pod 终止。
⚠️ 注意事项 / 常见错误
🔴 terminationGracePeriodSeconds 设置过长
如果设置过长,例如 600 秒(10 分钟),部署时间会急剧增加。通常,60-120 秒是合适的。
🔴 仅依赖 SIGTERM 而不使用 preStop sleep
由于 kube-proxy 的 Endpoint 传播延迟,SIGTERM 之后仍可能有新请求进入。`preStop: sleep 5` 必须添加。
🔴 注意没有 SIGTERM 处理程序的语言/框架
一些旧框架或通过 shell 脚本运行的容器默认会忽略 SIGTERM。必须使用 `exec` 命令将进程作为 PID 1 运行,SIGTERM 才能被传递。
# 错误示例 — SIGTERM 发送给 sh,未传递给应用程序
CMD ["sh", "-c", "node server.js"]
# 正确示例 — node 成为 PID 1 并直接接收 SIGTERM
CMD ["node", "server.js"]🔴 长轮询 / WebSocket 需要特殊处理
与 HTTP 请求不同,持久连接可能无法在宽限期内自然终止。对于此类连接,需要在收到 SIGTERM 时明确关闭连接的逻辑。
✅ 总结 / 结束语
Kubernetes 中 Pod 终止时正在进行的请求丢失的问题,不是设计缺陷,而是配置问题。应用以下三点可以覆盖大多数情况。
| 层级 | 设置 | 目的 |
| Kubernetes | terminationGracePeriodSeconds: 60 | 确保 SIGKILL 宽限期 |
| Kubernetes | preStop: sleep 5 | 等待 Endpoint 传播延迟 |
| 应用程序 | 实现 SIGTERM 处理程序 | 完成现有请求后终止 |
| 客户端 | 重试 + 短超时 | 从临时故障中自动恢复 |
如果一个系统具备这四点,那么在缩容过程中客户端收到错误的情况实际上就不会发生。
下一步,引入 Istio 或 Linkerd 等服务网格 (Service Mesh) 可以在基础设施层面自动处理所有这些模式,而无需修改应用程序代码。
发表回复