With the recent advancements in big data and AI, data utilization is increasing, but at the same time, are you worried about your personal information being leaked? 😟 Simply deleting names and phone numbers is not enough for safety.
Today, we’ll master the privacy protection models (k, l, t, m) used to safely disclose data and the frightening attack techniques they defend against, all in just 15 minutes! 🚀
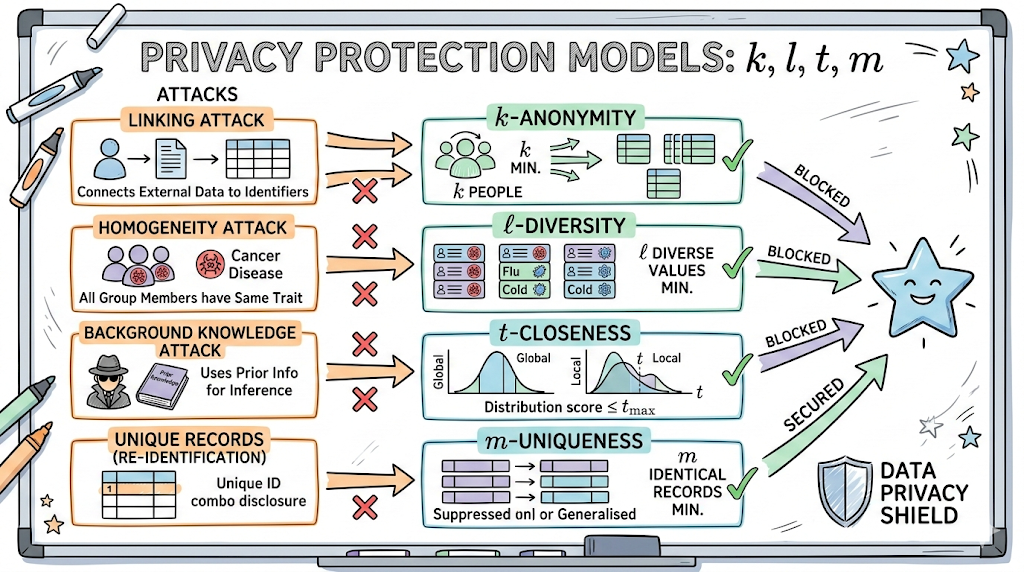
1. Why is simply deleting names not enough? (Types of Data Attacks)
Even if direct identifiers like names and resident registration numbers are removed, combining them with other information can quickly reveal someone’s identity. There are three major types of attacks that exploit this. 😈
- 🔗 Linking Attack: An attack that combines de-identified data with external public data (e.g., address books, social media) to identify a specific individual.
- 👯 Homogeneity Attack: An attack where individuals are grouped, but all sensitive information (e.g., disease) within that group is identical, allowing an attacker to guess who someone is.
- 🧠 Background Knowledge Attack: An attack that uses an attacker’s prior knowledge, such as “that person usually likes alcohol, so they must have a liver disease,” to infer information.
2. The Four Musketeers Protecting Data: Privacy Protection Models
The mathematically designed models to prevent these attacks are the main topics we’ll study today.
① k-anonymity: “Alone is dangerous, always k or more people!”
This is the most basic model for defending against linking attacks.
- Core Idea: Generalizes data so that there are at least k records with the same attributes.
- Effect: Even if an attacker views the data, they cannot identify who among at least k individuals it belongs to. (Identification probability 1/k)
② l-diversity: “Maintain individuality even within a group!”
k-anonymity alone cannot prevent homogeneity attacks. (e.g., if 3 people are grouped, and all three are cancer patients)
- Core Idea: Within the same group, sensitive information (e.g., disease names) must consist of at least l different types.
- Effect: Ensures diversity of information within a group, preventing certainty about a specific diagnosis.
③ t-closeness: “Biased information raises suspicion!”
l-diversity can also be vulnerable to background knowledge attacks or skewness attacks.
- Core Idea: The distribution of sensitive information within a specific group must be similar to the distribution of the entire dataset (distance less than or equal to t).
- Effect: Prevents situations where a specific group disproportionately has a high rate of a particular disease, thereby fundamentally blocking inference.
④ m-uniqueness: “Unique data is subject to deletion!”
Similar to k-anonymity, but this model focuses more on removing ‘uniqueness’.
- Core Idea: Manages the dataset so that there are at least m identical attribute combinations.
- Effect: Prevents the creation of isolated data (Outliers), thereby reducing the possibility of re-identification.
3. Comparison Table at a Glance 📊
| Model Name | Main Attack Defended | Core Idea |
|---|---|---|
| k-anonymity | Linking Attack | Maintain k or more records with identical attributes |
| l-diversity | Homogeneity Attack, Background Knowledge Attack | Include l or more types of sensitive information |
| t-closeness | Skewness Attack, Background Knowledge Attack | Minimize data distribution difference between overall and group |
| m-uniqueness | Re-identification Attack | Maintain m identical data combinations to avoid unique ones |
—
4. Understanding De-identification Concepts with Code (Python Example) 💻
Shall we look at the code to get a feel for how to group data and apply k-anonymity?
import pandas as pd
# Original data: Name, Age, Region, Disease
data = {
'Name': ['주군', 'A', 'B', 'C'],
'Age': [25, 28, 41, 44],
'City': ['서울', '서울', '부산', '부산'],
'Disease': ['감기', '독감', '위암', '위암']
}
df = pd.DataFrame(data)
# 1. Remove identifier (Name)
df_anon = df.drop('Name', axis=1)
# 2. Generalize age (k-anonymity example: group by 10s)
df_anon['Age'] = df_anon['Age'].apply(lambda x: f"{(x//10)*10}s")
# Check results
print(df_anon)
# Output result: '20s-Seoul' group and '40s-Busan' group with the same age and region are formed!🕵️ Summary and Conclusion
Data is like a ‘double-edged sword’. Used well, it’s a tonic; managed poorly, it’s poison. The k, l, t models we learned today are robust shields that allow us to use data with confidence. 🛡️
What kind of shield does the data you handle have? In an era where secure data utilization is competitiveness itself!
Leave a Reply