最近のビッグデータとAIの発展によりデータ活用が増えていますが、同時に個人情報が漏洩しないか心配ではありませんか?😟単に名前と電話番号を削除するだけでは安全ではありません。
今日は、データを安全に公開するために使用されるプライバシー保護モデル(k, l, t, m)と、それらが防ぐ恐ろしい攻撃手法を15分でマスターしてみましょう!🚀
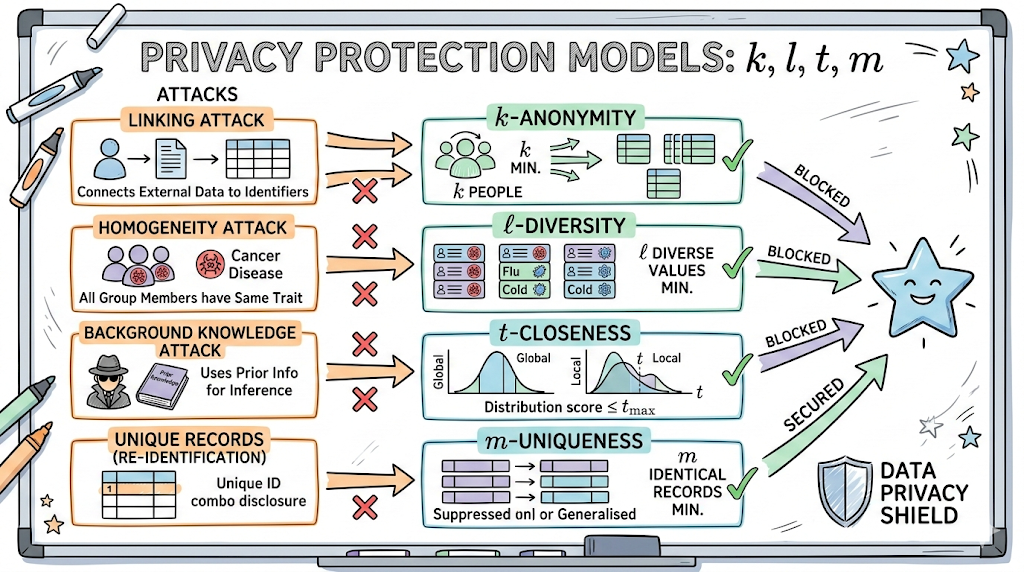
1. なぜ名前を削除するだけでは不十分なのですか?(データ攻撃の種類)
名前や住民登録番号のような直接的な識別子を削除しても、他の情報と組み合わせるとすぐに誰であるかが露見します。これを狙う代表的な3つの攻撃があります。😈
- 🔗 連結攻撃 (Linking Attack): 非識別化データと外部の公開データ(例:アドレス帳、SNS)を組み合わせて、特定の個人を特定する攻撃です。
- 👯 同質性攻撃 (Homogeneity Attack): 特定のグループにまとめられたが、そのグループの機密情報(病気など)がすべて同じであるため、誰であるかを推測する攻撃です。
- 🧠 背景知識攻撃 (Background Knowledge Attack): 「あの人は普段お酒が好きだから肝臓病だろう」といった攻撃者の事前知識を利用して情報を推論する攻撃です。
2. データを守る四銃士:プライバシー保護モデル
これらの攻撃を防ぐために数学的に設計されたモデルが、今日学ぶ主役たちです。
① k-匿名性 (k-anonymity): 「一人では危険、必ずk人以上!」
連結攻撃を防ぐための最も基本的なモデルです。
- 核心: 同じ属性を持つレコードが少なくともk個以上存在するようにデータを一般化します。
- 効果: 攻撃者がデータを見ても、少なくともk人の中から誰であるかを特定できなくします。(識別確率 1/k)
② l-多様性 (l-diversity): 「グループ内でも個性を守れ!」
k-匿名性だけでは同質性攻撃を防ぐことはできません。(例:3人がグループ化されたが、3人全員が癌患者である場合)
- 核心: 同じグループ内に、機密情報(病名など)が少なくともl種類以上の異なる種類で構成されている必要があります。
- 効果: グループ内の情報の多様性を確保し、特定の病名を確信できないようにします。
③ t-近接性 (t-closeness): 「偏った情報は疑いを招く!」
l-多様性も背景知識攻撃や偏り攻撃に対して脆弱である可能性があります。
- 核心: 特定のグループの機密情報分布が、データセット全体の分布と類似している(t以下の距離)必要があります。
- 効果: 特定のグループだけが特定の疾患の割合が異常に高い現象を防ぎ、推論を根本的に遮断します。
④ m-一意性 (m-uniqueness): 「ユニークなデータは削除対象!」
k-匿名性と似ていますが、「一意性」の除去にさらに焦点を当てたモデルです。
- 核心: データセット内に同じ属性の組み合わせが少なくともm個以上存在するように管理します。
- 効果: 孤立したデータ(Outlier)が発生しないようにし、再識別可能性を低減します。
3. 一目でわかる比較表 📊
| モデル名 | 防御する主な攻撃 | 核心アイデア |
|---|---|---|
| k-匿名性 | 連結攻撃 | 同一属性レコードをk個以上維持 |
| l-多様性 | 同質性攻撃、背景知識攻撃 | 機密情報の種類をl個以上含める |
| t-近接性 | 偏り攻撃、背景知識攻撃 | 全体とグループ間のデータ分布の差を最小化 |
| m-一意性 | 再識別攻撃 | ユニークなデータ組み合わせがないようにm個維持 |
—
4. コードで理解する非識別化の概念(Pythonの例)💻
データを簡単にグループ化してk-匿名性を適用する感覚をコードで見てみましょうか?
import pandas as pd
# 元データ:名前、年齢、地域、病気
data = {
'Name': ['주군', 'A', 'B', 'C'],
'Age': [25, 28, 41, 44],
'City': ['서울', '서울', '부산', '부산'],
'Disease': ['감기', '독감', '위암', '위암']
}
df = pd.DataFrame(data)
# 1. 識別子(名前)の削除
df_anon = df.drop('Name', axis=1)
# 2. 年齢の一般化(k-匿名性適用例:10歳単位でグループ化)
df_anon['Age'] = df_anon['Age'].apply(lambda x: f"{(x//10)*10}代")
# 結果確認
print(df_anon)
# 出力結果:年齢と地域が同じ「20代-ソウル」グループと「40代-釜山」グループが形成されました!🕵️ まとめと結び
データは「諸刃の剣」のようなものです。うまく使えば良薬ですが、管理を誤れば毒になります。今日学んだk, l, tモデルは、私たちが安心してデータを活用できるようにする頼もしい盾です。🛡️
皆さんが扱うデータはどのような盾を持っていますか?安全なデータ活用が競争力となる時代です!
コメントを残す