iptables couldn’t handle the scale to change the world. eBPF changed the kernel itself.
>

🎯 What this article covers
- The history of Kubernetes CNI: The generational shift from Flannel → Calico → Cilium
- The fundamental limitations of iptables and how eBPF overcame them
- The real reasons Google, AWS, Azure, and Alibaba chose Cilium
- How Cilium evolved from a simple CNI to a “networking platform”
- Decisive evidence that it has become the de facto standard as of 2026
📌 Introduction — “Why is CNI so important anyway?”
When first learning Kubernetes, CNI (Container Network Interface) often feels like “just something you install.”
A single line of `kubectl apply -f flannel.yml` makes pods communicate.
However, when a cluster scales to hundreds of nodes and thousands of services, the reality changes. Network latency inexplicably increases, policy changes become slow, and debugging becomes impossible. At this point, operations teams reach a common conclusion.
We chose the wrong CNI.
This is why countless companies migrated from Flannel to Calico, and then to Cilium. And now, Cilium has become the de facto standard, accounting for over 60% of CNI deployments according to the 2025 CNCF State of Kubernetes Networking report. How did it get here?
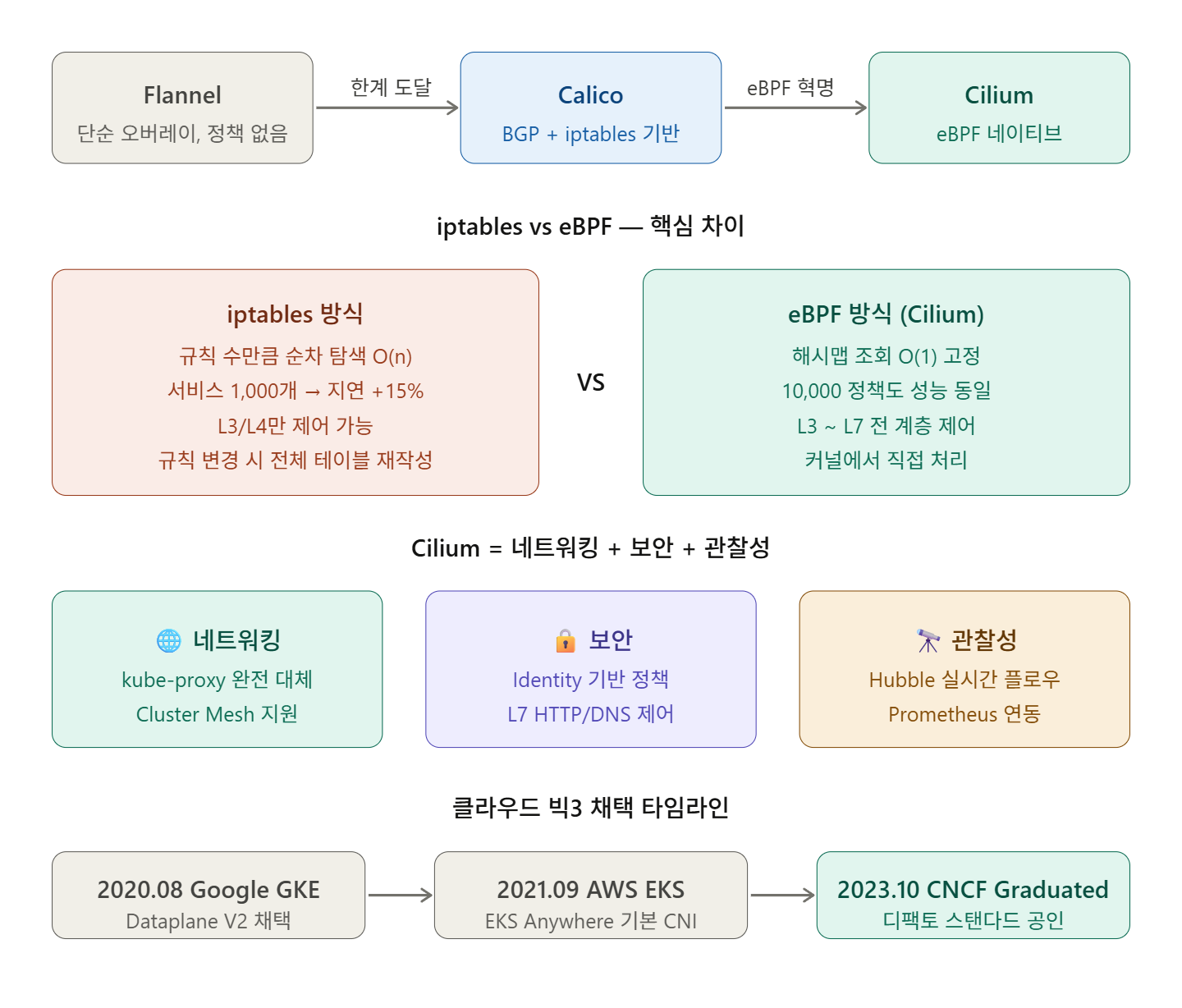
🔍 The Era of 1st Generation CNI — Flannel and Calico
Flannel: “Just get connected”
When building early Kubernetes platforms, Flannel was a natural choice. It was the most mature, had few dependencies, was simple to install, and showed high performance in benchmarks.
Flannel’s philosophy was simple: create a flat network where all pods can communicate with each other via VXLAN overlay. That’s it.
- Network policies? None.
- Observability? None.
- Security? Handle it yourself.
It was sufficient for small clusters. But as traffic increased, the limitations of iptables and netfilter began to emerge.
Calico: “Let’s get serious with BGP”
Calico used BGP, the same protocol that powers the internet backbone, for routing and became the default choice for enterprises starting in 2016.
Calico also supported network policies, enabling L3/L4 level traffic control desired by security teams. But there was a problem.
iptables operates linearly.
In the iptables approach, as policies increase, rules are evaluated sequentially, which can result in a 10-15% latency overhead in an environment with 1,000 policies.
When services exceed several hundred, the iptables rule table swells to tens of thousands of lines. Changing rules requires rewriting the entire table, which can cause temporary traffic disruption. In large-scale clusters, this is a disaster.
🔍 The Emergence of Cilium — The eBPF Gamble
2015~2016: “Let’s change the kernel”
Cilium was born in December 2015 by developers who would later found Isovalent, and was first unveiled at LinuxCon in 2016 as a fast IPv6 container networking project leveraging eBPF and XDP.
At the time, it was a gamble. While most CNIs operated on top of iptables, Cilium went all-in on eBPF from the start. Cilium bet that eBPF would be the future of cloud-native networking and built an eBPF-based data plane from the ground up.
What is eBPF?
eBPF (extended Berkeley Packet Filter) can be easily explained as follows.
Previously, to change kernel functionality, one had to modify the kernel source and recompile it, a process that could take months. eBPF is a technology that allows you to safely inject code into the kernel without modifying it. You can execute your desired logic at the exact point where network packets pass through the kernel.
Because eBPF operates within the kernel, it avoids expensive context switching between user space and kernel space, resulting in significant improvements in latency, throughput, and performance efficiency.
2018~2020: Full-scale Validation
Cilium 1.0 was released as its first stable version in April 2018, and in November 2019, Hubble, which provides eBPF-based network observability, was launched.
Then, a decisive event occurred.
In August 2020, Google chose Cilium as the new data plane for GKE.
Google Cloud adopted Cilium to create GKE Dataplane V2, leveraging eBPF to bypass traditional kernel networking paths, such as kube-proxy’s iptables-based service routing, thereby achieving high-efficiency packet processing.
Google’s choice was a strong signal to the entire industry.
🔍 Why all Big 3 Cloud Providers Chose Cilium
Google GKE
In 2024, GKE announced support for clusters up to 65,000 nodes, and this immense scalability was largely possible due to the robust and optimized architecture of GKE Dataplane V2. GKE Dataplane V2 is based on Cilium.
AWS EKS Anywhere
In September 2021, AWS chose Cilium for networking and security in EKS Anywhere.
Alibaba Cloud ACK
Alibaba recognized significant overhead during packet switching between namespaces in the existing veth-based container networking model, and high cost issues due to increasing rules in the default iptables-based service mode. Cilium helped solve these two core problems.
All three major global cloud providers reached the same conclusion: iptables had reached its limits, and eBPF was the only answer.
🔍 Why Cilium Transcended Being Just a CNI
Cilium should not be seen merely as a “fast CNI.” Cilium has integrated three areas into one.
1️⃣ Networking — Complete kube-proxy Replacement
Cilium completely replaces kube-proxy using eBPF’s efficient hash tables, rewriting service connections at the socket level to eliminate per-packet NAT overhead.
No kube-proxy? The iptables rule explosion disappears. A cluster with 10,000 network policies performs the same as one with 10. This is because of O(1) hashmap lookups.
2️⃣ Security — Identity-based, not IP-based
Traditional CNIs apply policies based on IP addresses. The problem is that pod IPs change frequently. Cilium uses Kubernetes labels as identities to apply policies.
Furthermore, Cilium supports L7 policies.
# L7 policy example controlling HTTP Method and Path
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: api-http-policy
namespace: production
spec:
endpointSelector:
matchLabels:
app: backend-api
ingress:
- fromEndpoints:
- matchLabels:
app: frontend
toPorts:
- ports:
- port: "8080"
protocol: TCP
rules:
http:
- method: GET
path: "/api/.*" # Allow only GET /api/*
- method: POST
path: "/api/data" # Allow only POST /api/data
# Block all other requestsThis is L7 level control impossible with traditional iptables. It’s possible without a service mesh.
3️⃣ Observability — Hubble
If you’ve experienced the hell of debugging network issues, you’ll know how powerful Hubble is.
Hubble observes individual network packet flows, verifies network policy decisions for traffic allowance/denial, and shows how Kubernetes services communicate via a service map. This data can be exported to Prometheus, OpenTelemetry, and Grafana.
Compared to the days of tracing why traffic was blocked with iptables, the world has changed.
💻 Cilium Installation and Basic Verification
# Install Cilium CLI
curl -L --remote-name-all
https://github.com/cilium/cilium-cli/releases/latest/download/cilium-linux-amd64.tar.gz
tar xzvf cilium-linux-amd64.tar.gz
sudo mv cilium /usr/local/bin/
# Install Cilium on the cluster (including kube-proxy replacement)
cilium install
--set kubeProxyReplacement=true
--set hubble.relay.enabled=true
--set hubble.ui.enabled=true
# Check installation status
cilium status
# Check if kube-proxy is replaced
kubectl exec -n kube-system ds/cilium -- cilium status | grep KubeProxyReplacement
# KubeProxyReplacement: True
# Observe real-time traffic with Hubble
hubble observe --follow --namespace production⚠️ Precautions / Common Mistakes
Kernel Version Check Required
Cilium installation requires Linux kernel 5.10 or higher (or 4.18 or higher for RHEL 8.10), and eBPF support must be enabled in the kernel configuration. If Cilium is deployed on an older OS, its functionality will be silently disabled.
Memory Overhead Planning
The Cilium agent consumes 150-250MB of memory per node, depending on the number of endpoints and policies. For a 100-node cluster, you should expect at least 15-25GB of additional memory. However, there are operational cases where Cilium’s improved throughput can reduce the total number of nodes by 10-15%.
Cost-effectiveness in Small Clusters
In clusters with fewer than 200 nodes and under 500 services, both CNIs perform sufficiently well, and performance differences are not a decisive factor. For a learning environment, starting with Flannel is not a bad idea.
✅ Summary — Why Cilium Became the Standard
Cilium’s rise was not merely because a “faster CNI” emerged. It was a fundamental architectural shift.
| Category | Traditional Method (iptables) | Cilium (eBPF) |
| Performance Characteristics | Linear degradation proportional to rule count | O(1) regardless of rule count |
| Policy Layer | L3/L4 | L3 ~ L7 |
| kube-proxy | Requires separate component | Completely replaced by eBPF |
| Observability | tcpdump, log files | Hubble (real-time flows) |
| Service Mesh | Requires sidecar | Possible without sidecar |
Cilium graduated as a CNCF Graduated project in October 2023, and its community, with over 21,000 GitHub stars and more than 900 contributors, is growing faster than any other CNI.
The eBPF-native characteristic is not a feature added later but fundamental to its architecture, and its performance and observability traits stem from the design itself, not as add-ons.
For the next steps, we recommend exploring service maps via Hubble UI, practicing L7 policies with CiliumNetworkPolicy, and investigating runtime security using Tetragon.
Leave a Reply