Kubernetes didn’t just appear overnight.
It embodies 15 years of Google’s hard-earned practical know-how, accumulated while running billions of containers.

🎯 What this article covers
- The background and core philosophy behind Google’s internal cluster management system, Borg
- The experimental attempts of Omega, designed to overcome Borg’s limitations
- How Kubernetes, released to the world as open source, became the cloud standard
- A comparison of the key differences between the three systems
📌 Introduction / Background — Why did Google create this?
Have you ever considered that the services we use today—Gmail, YouTube, Google Search—handle hundreds of millions of requests simultaneously?
In the early 2000s, Google faced an enormous problem. As services exploded, manually managing thousands of servers became physically impossible. A single mistake in server configuration could cause outages, resources were wasted, and engineers suffered through sleepless nights responding to failures.
From this pain emerged Google’s trilogy of cluster management systems: Borg → Omega → Kubernetes.
💡 What is a Cluster? A collection of multiple servers (nodes) grouped into a single pool of computing resources. The concept is to treat the entire cluster as one giant computer, rather than managing individual servers.
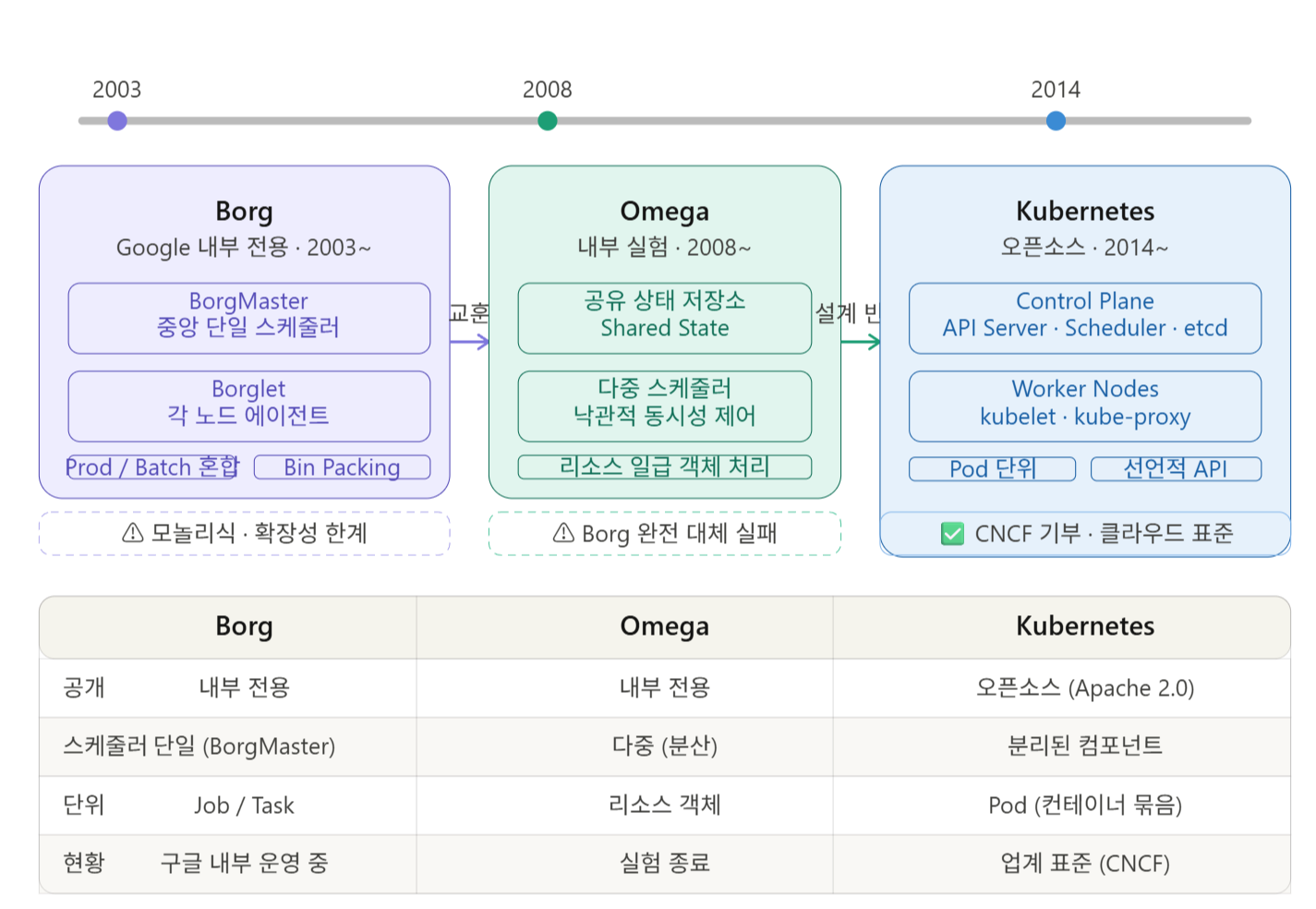
🔍 1st Generation: Borg — “Google’s Secret Weapon” (2003~)
What is Borg?
Borg is a large-scale cluster management system that Google developed and operated internally since 2003. It automatically deployed and managed hundreds of thousands of jobs across thousands of machines.
Its name comes from the alien species ‘Borg’ in Star Trek. Just as the Borg assimilate individual beings into a Collective, the philosophy was to operate thousands of individual servers as one giant collective.
Borg’s Core Concepts
Borg classifies jobs into two types:
- Prod (Production): Latency-sensitive services. Real-time services like Gmail and Search. Always top priority.
- Non-Prod (Batch): Batch jobs like large-scale data processing. Lower priority.
This classification was key. Borg minimized resource waste by bin packing Prod and Non-Prod jobs together on the same physical server. Batch jobs would secretly use CPU not utilized by Prod jobs, and immediately vacate resources when Prod jobs needed them.
What Borg solved
| Problem | Borg’s Solution |
| Manual management of thousands of servers | Central scheduler for automatic placement |
| Manual recovery during service failures | Automatic restart, rescheduling |
| Resource waste | Maximized utilization with mixed Prod/Batch placement |
| Lack of deployment automation | Declarative deployment with Job definition files |
### Borg’s Architecture
Borg consists of a BorgMaster (central control plane) and Borglet (agent on each node).
[BorgMaster] ─── 스케줄링 결정
│
├── [Borglet] ─ 서버 노드 1
├── [Borglet] ─ 서버 노드 2
└── [Borglet] ─ 서버 노드 NWhen BorgMaster instructs “run this job on that server,” Borglet actually executes it and reports its status.
Borg’s Limitations
However, Borg had structural problems:
- Monolithic BorgMaster: All decisions are made by a single BorgMaster. As the system grew, bottlenecks became severe.
- Job-centric design: Borg’s basic unit is a ‘Job’ containing ‘Tasks’. Expressing relationships between jobs was awkward.
- IP address sharing: Tasks on the same server shared IP addresses, leading to frequent port conflicts.
- Legacy accumulation: Having been used internally for a long time, structural improvements were difficult due to backward compatibility.
🔍 2nd Generation: Omega — “Redesigning from Scratch” (2008~)
Purpose of Omega’s Birth
Feeling Borg’s limitations, Google engineers began an experimental project called Omega around 2008. It started with the question, “What if we designed it correctly from the beginning, instead of fixing Borg?”
Omega was indeed operated internally at Google, but it couldn’t completely replace Borg. Borg was too deeply rooted in Google’s infrastructure.
Omega’s Innovation: Shared State Architecture
Borg’s biggest problem was its centralized scheduler. A single BorgMaster making all decisions limited scalability.
Omega solved this with a Shared State approach:
기존 Borg:
[BorgMaster] → 모든 결정 → [Borglet들]
(병목 발생)
Omega:
[Scheduler A] ──┐
[Scheduler B] ──┼─→ [공유 상태 저장소] → [노드들]
[Scheduler C] ──┘
(낙관적 동시성 제어)Multiple schedulers simultaneously observe the cluster state and make scheduling decisions independently. Conflicts are resolved using Optimistic Concurrency Control.
💡 Optimistic Concurrency Control: A method that “assumes conflicts are rare and proceeds with operations, retrying if a conflict is later detected.” It offers higher throughput than pessimistic methods (which acquire locks first).
###
Omega’s Legacy
While Omega itself didn’t replace Borg, its core ideas significantly influenced Kubernetes:
- Treating resources as first-class objects: Explicitly specifying and tracking CPU, memory
- Scheduler decoupling: Breaking away from single-scheduler dependency
- Enhanced Declarative API: A system that adjusts to the desired state declared by the user
🔍 3rd Generation: Kubernetes — “The Open Source that Changed the World” (2014~)
Why did Google open source it?
With the emergence of Docker in 2013, container technology began to gain widespread adoption. Google realized, “If we open source the know-how we’ve accumulated over a decade, we can establish the standard for the cloud ecosystem.”
In June 2014, Google released Kubernetes as open source. It means ‘helmsman’ (the person who steers a ship) in Greek. This is why its logo is a ship’s wheel (Helm).
Applying Lessons from Borg to Kubernetes
In their 2016 paper “Borg, Omega, Kubernetes,” Google engineers detailed how Borg’s operational experience influenced Kubernetes’ design:
🔴 Borg’s Mistakes → Kubernetes’ Solutions
| Borg’s Problem | Kubernetes’ Solution |
| Job/Task-centric structure, difficulty expressing relationships | Introduction of the Pod concept. Redefining the unit as a container group |
| Tasks sharing IPs, port conflicts | Assigning a unique IP to each Pod |
| Monolithic BorgMaster | Decoupled components (API Server, Scheduler, Controller Manager) |
| Internal-only design | Open API centric, extensible plugin structure |
###
Kubernetes’ Core Architecture
[Control Plane]
├── API Server ← 모든 요청의 관문
├── Scheduler ← Pod를 어느 노드에 배치할지 결정
├── Controller Mgr ← 현재 상태를 원하는 상태로 유지
└── etcd ← 클러스터 전체 상태 저장 (분산 KV 저장소)
[Worker Nodes]
├── kubelet ← Borglet과 동일한 역할, 컨테이너 실행·관리
├── kube-proxy ← 네트워크 규칙 관리
└── Container Runtime (Docker, containerd 등)###
Declarative API — Kubernetes’ Philosophy
Kubernetes’ most powerful philosophy is Declarative Management.
# Declare the desired state
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-webserver
spec:
replicas: 3 # Always run 3 instances
selector:
matchLabels:
app: webserver
template:
metadata:
labels:
app: webserver
spec:
containers:
- name: nginx
image: nginx:1.25
resources:
requests:
cpu: "250m" # 0.25 CPU request
memory: "128Mi" # 128MB memory request
limits:
cpu: "500m" # Max 0.5 CPU
memory: "256Mi" # Max 256MBWhen this YAML is applied, Kubernetes automatically runs 3 nginx Pods and automatically recovers if one dies. Engineers only need to declare “what” they want, not “how.”
The Ecosystem Created by Kubernetes
What makes Kubernetes truly great is not just the technology itself. It created an ecosystem.
- 2015: CNCF (Cloud Native Computing Foundation) established. Google donated Kubernetes.
- 2016: Helm (package manager), managed services from various cloud vendors (GKE, AKS, EKS) emerged.
- 2017: Competitors like Docker Swarm and Mesos virtually recognized Kubernetes as the de facto standard.
- 2018 onwards: Hundreds of tools like Service Mesh (Istio), GitOps (ArgoCD), Serverless (Knative) operate on top of Kubernetes.
⚠️ Cautions / Common Mistakes
1. Kubernetes is not an open-source version of Borg 🚫 Kubernetes is a system redesigned from scratch based on lessons learned from Borg. It’s not Borg’s code open-sourced as-is.
2. Omega also failed to replace Borg 🚫 Borg, Omega, and Kubernetes are operated simultaneously within Google. Borg still underpins Google’s core infrastructure.
3. Kubernetes = More than just container orchestration ✅ Many people understand it only as a “tool for managing multiple Docker containers,” but Kubernetes is a platform for declaratively managing the entire cloud-native infrastructure. It encompasses networking, storage, security policies, and service discovery.
✅ Summary / Conclusion
| System | Period | Public Status | Key Innovation | Limitation |
| Borg | 2003~ | Internal Only | Large-scale automation, mixed Prod/Batch | Monolithic, scalability limits |
| Omega | 2008~ | Internal Only | Shared state, multiple schedulers | Failed to replace Borg |
| Kubernetes | 2014~ | Open Source | Declarative API, plugin ecosystem | High learning curve |
Google’s 15-year journey is not just a simple technological evolution. It is the release of painful lessons learned from operating billions of containers to the world in the form of Kubernetes.
When you execute a single line of `kubectl apply -f deployment.yaml`, the wisdom accumulated by Google engineers over 20 years is at work behind it. 🚀
For the next steps, studying Kubernetes’ scheduling mechanisms, etcd’s Raft consensus algorithm, and Service Mesh (Istio) will help you better understand the depth of this ecosystem.
Leave a Reply