容器不是虚拟机。然而,它们却感觉像是被隔离的。这是为什么呢?

##
##
🎯 本文涵盖内容
- Docker(容器)实现隔离的两种Linux内核机制
- Namespace — 隔离可见内容
- cgroups — 限制可用资源
- 未隔离的内容 — 安全设计时必须了解的陷阱
- 虚拟机(VM)与容器隔离级别的比较
📌 引言 / 背景
初学Docker时,最常听到的一句话是:
容器是隔离的环境。
没错。但是,它们隔离到什么程度呢?
实际上,许多开发人员和运维人员误以为容器是像VM一样完全独立的环境。结果,他们对容器逃逸(Container Escape)漏洞毫无防备,或者遇到单个容器独占整个宿主机CPU的情况。
要正确理解Docker的隔离,需要了解Linux内核层面发生了什么。今天,我们将深入探讨其内部机制。
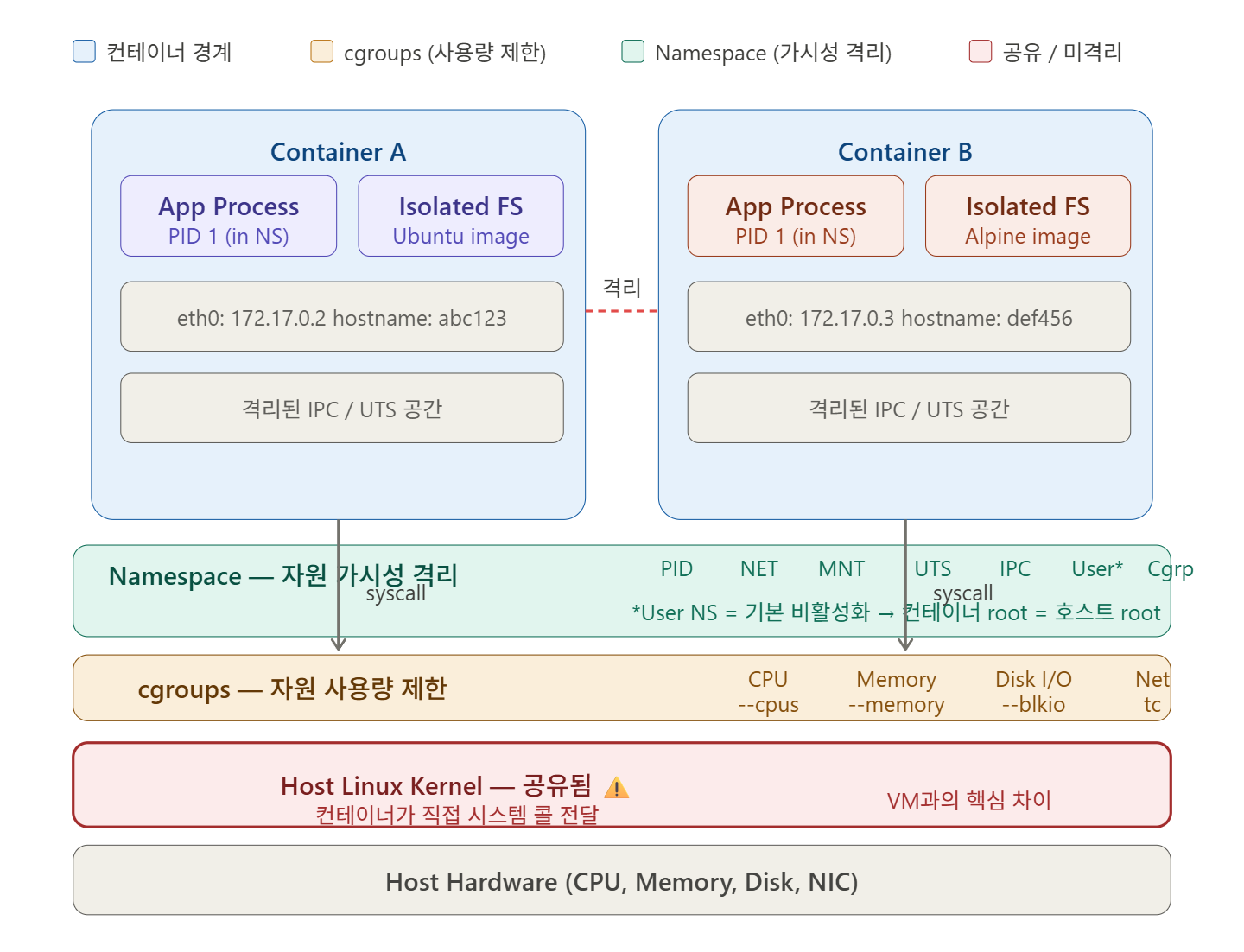
🔍 1. Namespace — 隔离“可见内容”
Linux Namespace是内核功能,用于限制进程可以看到的系统资源范围。尽管在同一个宿主机上,容器内的进程感觉就像拥有自己的独立世界。
Docker总共使用了7种Namespace。
###
🗂️ PID Namespace — 进程ID隔离
在容器内执行`ps aux`时,只能看到自己的进程。宿主机上运行的数百个进程是不可见的。
容器内的第一个进程总是显示为PID 1。但在宿主机上查看时,它拥有完全不同的PID号。
# 在宿主机上查看
$ docker run --rm ubuntu sleep 1000 &
$ ps aux | grep sleep
root 12345 ... sleep 1000 # 宿主机PID: 12345
# 在容器内查看
$ docker exec <container_id> ps aux
PID USER COMMAND
1 root sleep 1000 # 在容器内是PID 1###
🌐 Network Namespace — 网络隔离
每个容器都有自己的虚拟网络接口、IP地址和路由表。在容器A中执行`ifconfig`时,容器B的网络接口是不可见的。
Docker默认会创建一个名为`docker0`的桥接网络,并通过虚拟以太网对(veth pair)连接每个容器。
###
📁 Mount Namespace — 文件系统隔离
容器拥有自己的根文件系统(/)。这就是为什么运行Ubuntu镜像时`apt`能工作,运行Alpine镜像时`apk`能工作的原因。
宿主机的文件系统默认是不可见的,除非使用`-v`选项明确挂载。
###
👤 UTS Namespace — 主机名隔离
容器拥有自己的主机名(hostname)和域名。在容器内执行`hostname`时,显示的是容器ID,而不是宿主机的名称。
###
🔐 IPC Namespace — 进程间通信隔离
隔离System V IPC(共享内存、信号量、消息队列)。它阻止容器A中的进程访问容器B的共享内存。
###
👥 User Namespace — 用户ID隔离
容器内是`root`(UID 0)的用户,在宿主机上可以映射为普通用户。此功能是实现无根容器(Rootless containers)的关键,但在Docker的默认设置中并未启用。
###
🔗 Cgroup Namespace — cgroup视图隔离
限制容器只能看到自己的cgroup层次结构。(cgroup本身的说明将在下面立即介绍。)
🔍 2. cgroups — 限制“可用资源量”
cgroups (Control Groups)是内核功能,用于限制、测量和隔离进程组可以使用的系统资源量。
如果说Namespace处理的是“可见内容”,那么cgroups处理的就是“可用资源量”。
Docker控制的主要资源如下:
| 资源 | 选项示例 | 说明 |
| CPU | –cpus=”1.5″ | 最多使用1.5个核心 |
| 内存 | –memory=”512m” | 最大512MB RAM |
| 磁盘I/O | –blkio-weight=500 | 设置块I/O权重 |
| 网络 | (tc联动) | 带宽限制 |
# 运行一个CPU限制为1核、内存限制为512MB的容器
docker run --cpus="1.0" --memory="512m" nginx
# 查看实际的cgroup文件(在宿主机上)
cat /sys/fs/cgroup/memory/docker/<container_id>/memory.limit_in_bytes
# 536870912 (= 512MB)如果没有cgroups会发生什么?一个恶意或有bug的容器可能会占用宿主机100%的CPU或耗尽所有内存,导致整个系统崩溃。这被称为“吵闹的邻居”问题(Noisy Neighbor problem)。
⚠️ 未隔离的内容 — 安全漏洞由此产生
现在是最重要的部分。Docker容器无法隔离的内容。如果不知道这些,在云基础设施设计或安全审计中会犯致命错误。
❌ 内核本身是共享的
这是容器与VM最大的区别。
[VM] [컨테이너]
┌─────────────────────┐ ┌───────────────────────────┐
│ Guest OS Kernel A │ │ Container A Container B │
├─────────────────────┤ │ (Ubuntu) (Alpine) │
│ Guest OS Kernel B │ ├───────────────────────────┤
├─────────────────────┤ │ ← 커널 공유 → │
│ Hypervisor │ │ Host Linux Kernel │
├─────────────────────┤ ├───────────────────────────┤
│ Host OS Kernel │ │ Host Hardware │
└─────────────────────┘ └───────────────────────────┘容器直接使用宿主机的Linux内核。因此,如果容器内的进程利用内核漏洞,整个宿主机都将面临风险。这就是容器逃逸(Container Escape)攻击的原理。
❌ 系统调用直接传递给宿主内核
容器内的进程调用`read()`、`write()`、`socket()`等系统调用时,这些请求会直接传递给宿主内核,没有中间层。不像VM那样有管理程序拦截和验证的层。
因此,Docker默认应用了Seccomp (Secure Computing Mode)配置文件来阻止危险的系统调用。但并非所有系统调用都能被阻止。
# 查看默认的Seccomp配置文件
docker inspect <container_id> | grep -i seccomp###
❌ /proc, /sys 的部分内容是共享的
如果像`–pid=host`选项那样错误地与宿主机共享命名空间,通过`/proc`文件系统可能会暴露宿主机的进程信息。
###
❌ User Namespace 默认禁用
前面提到的User Namespace在Docker的默认设置中是禁用的。这意味着容器内的`root`在宿主机上也是`root`。如果与卷挂载结合,可能会导致对宿主机文件的`root`访问。
# 危险模式 — 将宿主机的根文件系统挂载到容器
docker run -v /:/host --rm -it ubuntu chroot /host
# 这样容器内就可以访问整个宿主机##
💻 实践:直接查看 Namespace
# 查看容器的Namespace列表(在宿主机上)
CONTAINER_PID=$(docker inspect --format '{{.State.Pid}}' <container_id>)
ls -la /proc/$CONTAINER_PID/ns/
# 输出示例
lrwxrwxrwx 1 root root 0 ... cgroup -> cgroup:[4026531835]
lrwxrwxrwx 1 root root 0 ... ipc -> ipc:[4026532456]
lrwxrwxrwx 1 root root 0 ... mnt -> mnt:[4026532454]
lrwxrwxrwx 1 root root 0 ... net -> net:[4026532459]
lrwxrwxrwx 1 root root 0 ... pid -> pid:[4026532457]
lrwxrwxrwx 1 root root 0 ... uts -> uts:[4026532455]
# 如果user Namespace与宿主机相同?→ User Namespace 未使用状态# 比较宿主机和容器的user namespace
ls -la /proc/1/ns/user # 宿主机init进程
ls -la /proc/$CONTAINER_PID/ns/user # 容器进程
# 如果符号链接的数字相同 → 相同的User Namespace = 危险✅ 总结 / 结束语
| 分类 | 功能 | 隔离对象 |
| Namespace | PID, Network, Mount, UTS, IPC, User, Cgroup | 资源的可见性 |
| cgroups | CPU, 内存, I/O, 网络 | 资源的使用量 |
| 未隔离 | 内核, 系统调用, User NS(默认) | 安全边界的局限性 |
Docker的隔离功能强大但并非完美。核心总结如下:
- 🟢 Namespace: 隔离进程、网络、文件系统等资源的可见性
- 🟢 cgroups: 限制CPU、内存等资源的使用量
- 🔴 内核共享: 容器使用相同的Linux内核,这是与VM的根本区别
- 🔴 User Namespace默认禁用: 容器内的root = 宿主机的root
如果工作负载对安全性要求很高,请考虑以下几点:
- 无根容器(Rootless containers)或启用User Namespace
- 应用Seccomp / AppArmor / SELinux配置文件
- 禁止使用`–privileged`选项
- 对于敏感工作负载,考虑使用gVisor或Kata Containers等增强型运行时
发表回复