コンテナは仮想マシンではありません。しかし、隔離されているように感じられます。なぜでしょうか?

##
##
🎯 この記事で扱うこと
- Docker(コンテナ)が隔離を実現する2つのLinuxカーネルメカニズム
- Namespace — 何が見えるかを隔離
- cgroups — どれだけ使えるかを制限
- 隔離されないもの — セキュリティ設計時に必ず知っておくべき落とし穴
- 仮想マシン(VM)とコンテナの隔離レベル比較
📌 はじめに / 背景
Dockerを初めて学ぶとき、最もよく聞く言葉があります。
コンテナは隔離された環境です。
その通りです。しかし、どこまで隔離されるのでしょうか?
実際、多くの開発者や運用者は、コンテナをVMのように完全に独立した環境だと誤解しています。その結果、コンテナエスケープ(Container Escape)の脆弱性に対して無防備になったり、1つのコンテナがホスト全体のCPUを独占する状況に直面したりすることもあります。
Dockerの隔離を正しく理解するには、Linuxカーネルレベルで何が起こっているのかを知る必要があります。今日はその内部を掘り下げてみましょう。
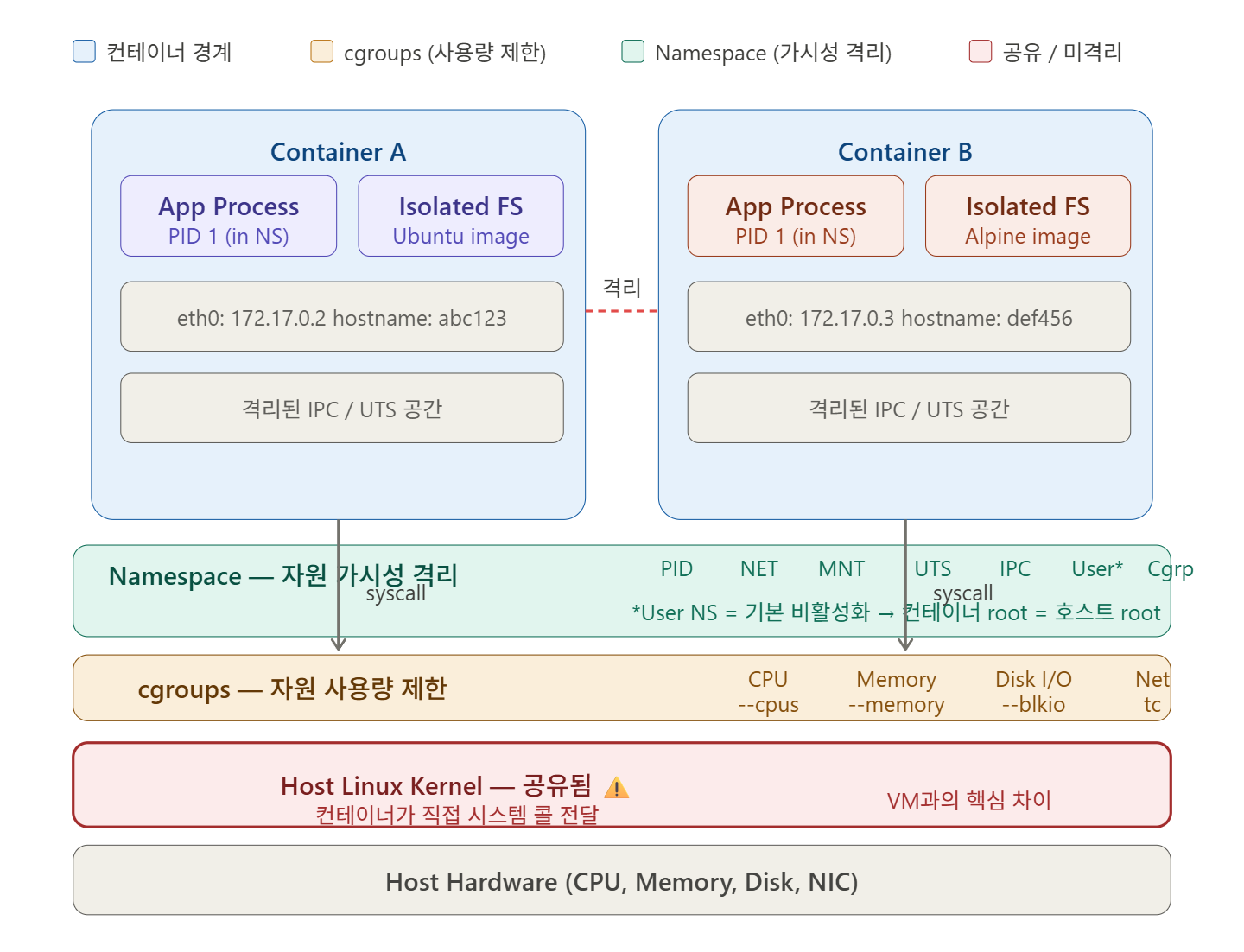
🔍 1. Namespace — 「何が見えるか」を隔離する
Linux Namespaceは、プロセスが見ることができるシステムリソースの範囲を制限するカーネル機能です。同じホスト上にありますが、コンテナ内のプロセスはまるで自分だけの世界があるかのように感じます。
Dockerが使用するNamespaceは合計で7種類です。
###
🗂️ PID Namespace — プロセスIDの隔離
コンテナ内で`ps aux`を実行すると、自分のプロセスだけが見えます。ホストで実行中の数百のプロセスは見えません。
コンテナ内の最初のプロセスは常にPID 1として表示されます。しかし、ホストから見ると、まったく異なるPID番号を持っています。
# ホストで確認
$ docker run --rm ubuntu sleep 1000 &
$ ps aux | grep sleep
root 12345 ... sleep 1000 # ホストPID: 12345
# コンテナ内で確認
$ docker exec <container_id> ps aux
PID USER COMMAND
1 root sleep 1000 # コンテナ内ではPID 1###
🌐 Network Namespace — ネットワークの隔離
各コンテナは、独自の仮想ネットワークインターフェース、IPアドレス、ルーティングテーブルを持ちます。コンテナAで`ifconfig`を実行しても、コンテナBのネットワークインターフェースは見えません。
Dockerはデフォルトで`docker0`というブリッジネットワークを作成し、各コンテナを仮想イーサネットペア(veth pair)で接続します。
###
📁 Mount Namespace — ファイルシステムの隔離
コンテナは独自のルートファイルシステム(/)を持ちます。これが、Ubuntuイメージを実行すると`apt`が動作し、Alpineイメージを実行すると`apk`が動作する理由です。
ホストのファイルシステムは、`-v`オプションで明示的にマウントしない限り、デフォルトでは見えません。
###
👤 UTS Namespace — ホスト名の隔離
コンテナは独自のホスト名(hostname)とドメイン名を持ちます。コンテナ内で`hostname`を実行すると、ホストの名前ではなくコンテナIDが表示されます。
###
🔐 IPC Namespace — プロセス間通信の隔離
System V IPC(共有メモリ、セマフォ、メッセージキュー)を隔離します。コンテナAのプロセスがコンテナBの共有メモリにアクセスするのをブロックします。
###
👥 User Namespace — ユーザーIDの隔離
コンテナ内で`root`(UID 0)であるユーザーが、ホストでは一般ユーザーにマッピングされることがあります。この機能はRootlessコンテナを可能にする核心ですが、Dockerのデフォルト設定では有効になっていません。
###
🔗 Cgroup Namespace — cgroupビューの隔離
コンテナが自身のcgroup階層のみを見ることができるように制限します。(cgroup自体の説明はすぐ下で扱います。)
🔍 2. cgroups — 「どれだけ使えるか」を制限する
cgroups(Control Groups)は、プロセスグループが使用できるシステムリソースの量を制限、測定、隔離するカーネル機能です。
Namespaceが「何が見えるか」を扱うのに対し、cgroupsは「どれだけ使えるか」を扱います。
Dockerが制御する主なリソースは以下の通りです。
| リソース | オプション例 | 説明 |
| CPU | –cpus=”1.5″ | 最大1.5コア使用 |
| メモリ | –memory=”512m” | 最大512MB RAM |
| ディスクI/O | –blkio-weight=500 | ブロックI/O重み設定 |
| ネットワーク | (tc連携) | 帯域幅制限 |
# CPU 1コア、メモリ 512MBに制限されたコンテナを実行
docker run --cpus="1.0" --memory="512m" nginx
# 実際のcgroupファイルを確認 (ホストで)
cat /sys/fs/cgroup/memory/docker/<container_id>/memory.limit_in_bytes
# 536870912 (= 512MB)cgroupsがなければ何が起こるでしょうか?悪意のある、またはバグのある1つのコンテナがホストのCPUを100%占有したり、メモリをすべて使い果たしたりして、システム全体をダウンさせる可能性があります。これをNoisy Neighbor問題と呼びます。
⚠️ 隔離されないもの — ここからセキュリティホールが生まれる
さて、最も重要な部分です。Dockerコンテナが隔離できないものです。これを知らないと、クラウドインフラの設計やセキュリティ監査で致命的な間違いを犯します。
❌ カーネル自体は共有される
これがコンテナとVMの最大の違いです。
[VM] [컨테이너]
┌─────────────────────┐ ┌───────────────────────────┐
│ Guest OS Kernel A │ │ Container A Container B │
├─────────────────────┤ │ (Ubuntu) (Alpine) │
│ Guest OS Kernel B │ ├───────────────────────────┤
├─────────────────────┤ │ ← 커널 공유 → │
│ Hypervisor │ │ Host Linux Kernel │
├─────────────────────┤ ├───────────────────────────┤
│ Host OS Kernel │ │ Host Hardware │
└─────────────────────┘ └───────────────────────────┘コンテナはホストのLinuxカーネルをそのまま使用します。したがって、コンテナ内のプロセスがカーネルの脆弱性を悪用すると、ホスト全体が危険にさらされます。これがコンテナエスケープ(Container Escape)攻撃の原理です。
❌ システムコール(System Call)は直接ホストカーネルに渡される
コンテナ内のプロセスが`read()`、`write()`、`socket()`などのシステムコールを呼び出すと、この要求は中間層なしにホストカーネルに直接伝達されます。VMのようにハイパーバイザーが傍受して検証するレイヤーはありません。
このため、DockerはSeccomp(Secure Computing Mode)プロファイルをデフォルトで適用し、危険なシステムコールをブロックします。しかし、すべてのシステムコールをブロックすることはできません。
# デフォルトのSeccompプロファイルを確認
docker inspect <container_id> | grep -i seccomp###
❌ /proc, /sys の一部は共有される
`–pid=host`オプションのように誤ってネームスペースをホストと共有すると、`/proc`ファイルシステムを通じてホストのプロセス情報が露出します。
###
❌ User Namespaceはデフォルトで無効
前述のUser Namespaceは、Dockerのデフォルト設定では無効になっています。つまり、コンテナ内の`root`はホストでも`root`です。ボリュームマウントと組み合わせると、ホストファイルへの`root`アクセスが可能になる可能性があります。
# 危険なパターン — ホストのルートファイルシステムをコンテナにマウント
docker run -v /:/host --rm -it ubuntu chroot /host
# これにより、コンテナ内からホスト全体にアクセス可能になる##
💻 実践: Namespaceを直接確認する
# コンテナのNamespaceリストを確認 (ホストで)
CONTAINER_PID=$(docker inspect --format '{{.State.Pid}}' <container_id>)
ls -la /proc/$CONTAINER_PID/ns/
# 出力例
lrwxrwxrwx 1 root root 0 ... cgroup -> cgroup:[4026531835]
lrwxrwxrwx 1 root root 0 ... ipc -> ipc:[4026532456]
lrwxrwxrwx 1 root root 0 ... mnt -> mnt:[4026532454]
lrwxrwxrwx 1 root root 0 ... net -> net:[4026532459]
lrwxrwxrwx 1 root root 0 ... pid -> pid:[4026532457]
lrwxrwxrwx 1 root root 0 ... uts -> uts:[4026532455]
# user Namespaceがホストと同じなら? → User Namespace未使用状態# ホストとコンテナのuser namespaceを比較
ls -la /proc/1/ns/user # ホストのinitプロセス
ls -la /proc/$CONTAINER_PID/ns/user # コンテナプロセス
# シンボリックリンクの数字が同じなら → 同じUser Namespace = 危険✅ まとめ / 終わりに
| 区分 | 機能 | 隔離対象 |
| Namespace | PID, Network, Mount, UTS, IPC, User, Cgroup | リソースの可視性 |
| cgroups | CPU, メモリ, I/O, ネットワーク | リソースの使用量 |
| 隔離されない | カーネル, システムコール, User NS(デフォルト) | セキュリティ境界の限界 |
Dockerの隔離は強力ですが、完全ではありません。核心をまとめると以下の通りです。
- 🟢 Namespace: プロセス、ネットワーク、ファイルシステムなどリソースの可視性を隔離
- 🟢 cgroups: CPU、メモリなどリソースの使用量を制限
- 🔴 カーネルは共有: コンテナは同じLinuxカーネルを使用し、これがVMとの根本的な違い
- 🔴 User Namespaceデフォルト無効: コンテナのroot = ホストのroot
セキュリティが重要なワークロードであれば、以下を考慮してください。
- RootlessコンテナまたはUser Namespaceの有効化
- Seccomp / AppArmor / SELinuxプロファイルの適用
- `–privileged`オプションの使用禁止
- 機密性の高いワークロードにはgVisorまたはKata Containersのような強化されたランタイムの検討
コメントを残す