如果心电图出现噪音,真正需要观察的心律失常就会变得不可见。
云成本也是如此。
>

本文涵盖内容
- 云成本预测本质上困难的原因
- 传统IT预算模型与云预算模型的决定性差异
- FinOps的运营周期 — 预测 → 观察 → 调整
- 核心指标从预测准确性转向异常检测时间的原因
- 未删除资源的真正罪名 — 不是成本泄漏,而是信号遮蔽
±5%预测的幻想
传统IT预算通常以±5%的准确度为基础。如果购买100台服务器,这100台服务器将在5年内折旧,因此预测实际上只需一次乘法运算。这是一个CFO易于管理的模型。
然而,云服务正面否定了这种模型。
- 流量每周都不同
- 发布一个功能就会改变成本结构
- 运行一次数据管道,当月账单就会翻倍
- 如果有人启动GPU实例后忘记关闭,几天内就会产生数百万韩元的额外费用
在这种环境下,±5%的预测是谎言。用谎言制定的预算会在第一个季度崩溃,到第二个季度,所有人都会开始忽视这些数字。
云是“变动性本身”
FinOps基金会有一个强烈强调的原则:
“Cloud is variable by nature. Manage variability — don’t try to eliminate it.”
云的变动性不是缺陷,而是特性。试图消除变动性,也会扼杀云的最大优势:弹性(Elasticity)。RI(预留实例)或Savings Plan最终也只是定义“接受多少变动性”的工具,它们无法消除变动性本身。
因此,实际云成本管理的第一个领悟是:
“不要试图精确命中,而要保持在范围内。”
目标指标本身发生了变化。
| 项目 | 传统IT | FinOps |
| 预测准确性 | ±5% | ±12~15% (优秀), ±20% (合格) |
| 预算审查周期 | 季度 | 日/周 |
| 核心KPI | 预算遵守率 | 平均检测时间(MTTD) |
—
真正的运营模式:预测 → 观察 → 调整
云成本管理遵循以下短周期运行:
1. 预测 — 设置护栏
在月初,设定一个可接受的范围,即“在此范围内是正常的”。这不是一个精确的数字。这个范围将成为预算警报和异常检测的基准。
2. 观察 — 每日查看实际成本
Cost Explorer每日报告、成本异常检测警报、Slack机器人 — 任何工具都可以。核心是确保“账单不会超过一天未被发现”。
3. 调整 — 分析差异并更新模型
每周或每月审查预测与实际差异(Variance)。如果出现较大差异,则分类原因,并将其反映到下个月的预测模型中。承认偏差并更新模型是FinOps的诚信之处。
这个周期的本质很简单:
犯错是正常的,快速发现才是关键。
因此,成本管理不是会计问题,而是“信号处理问题”
这里出现了一个真正有趣的观点。云成本管理本质上更接近于信号处理(Signal Processing),而非会计。
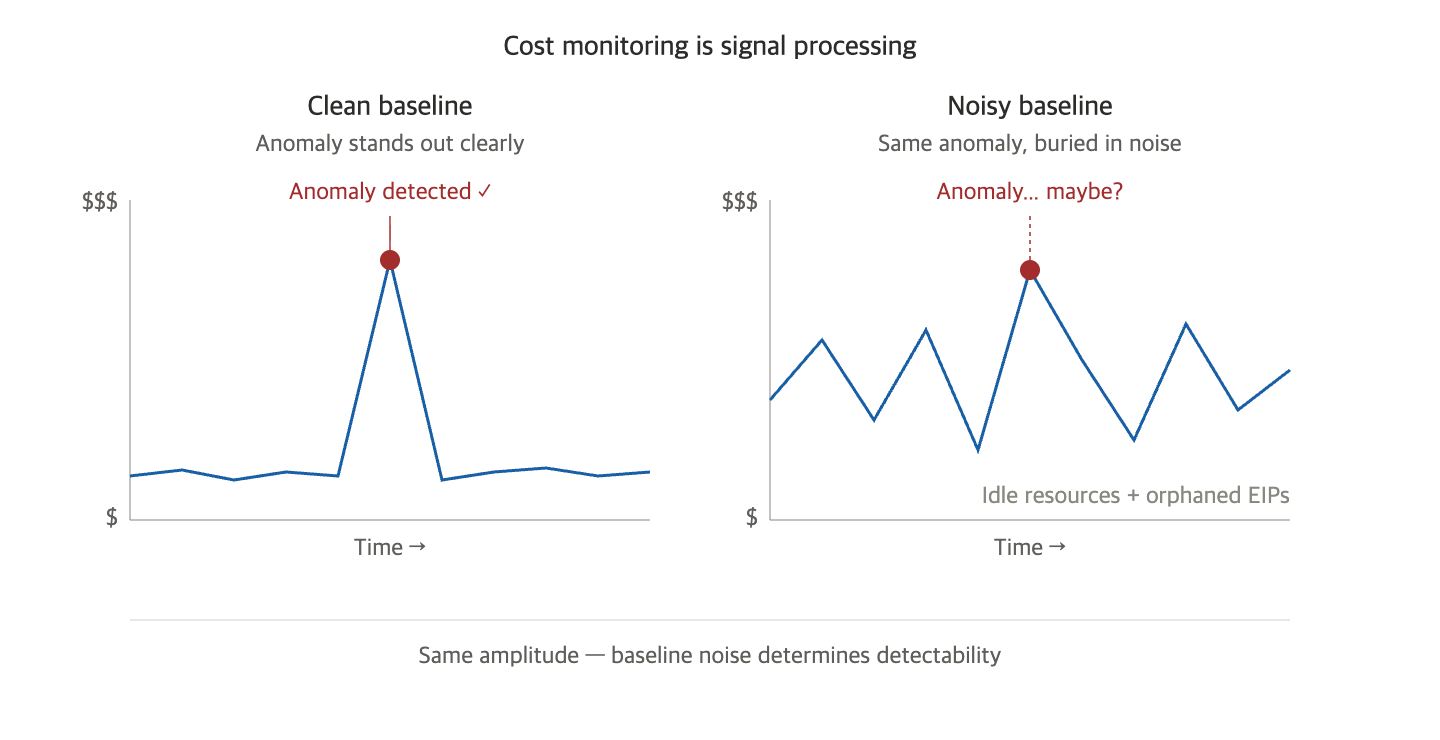
回想一下心电图。正常心跳在稳定的基线上以小振幅流动。如果发生心律失常,就会出现明显的尖峰。医生会根据这个尖峰进行紧急处理。
但是,如果机器本身产生噪音,导致基线波动不定呢? 即使发生同样的心律失常,也可能被噪音掩盖而看不见。 患者将面临危险,医生也会延迟发现异常。
云成本也具有完全相同的结构:
- 基线 — 日常运营中产生的正常成本
- 信号 — 真正需要捕获的异常(流量激增、错误部署、安全事件导致资源暴增)
- 噪音 — 未删除的资源、游离的EIP、被遗忘的GPU、无责任人的资产
异常检测最终由信噪比(SNR, Signal-to-Noise Ratio) 决定。如果噪音很大,相同的信号就会被掩盖。因此,清理未删除资源的真正价值不是节省成本,而是“保持干净的基线,以便快速检测异常”。
因此,核心指标发生了转变
传统上,“擅长预算管理的部门”是预测准确性高的部门。然而,在云时代,“擅长成本管理的组织”则通过不同的指标来衡量:
- MTTD (Mean Time To Detect) — 从成本异常发生到检测所需的时间
- Variance Explainability — 预测与实际差异能在多大程度上被解释
- Tagged Coverage Ratio — 总成本中责任人明确的比例
- Idle Resource Ratio — 未使用的资源所占的比例
±5%的准确性已不复存在,取而代之的是“24小时内检测”、“90%以上标签覆盖率”等指标。
实践中保持干净基线的4种模式
① 每日成本审查自动化
确保每天早上Slack自动发布“昨日成本 + 7天平均 + 差异 %”。人工每天查看控制台的运营方式绝不可持续。
# AWS CLI — 获取昨日成本的简单示例
aws ce get-cost-and-usage
--time-period Start=$(date -d 'yesterday' +%Y-%m-%d),End=$(date +%Y-%m-%d)
--granularity DAILY
--metrics UnblendedCost② 启用成本异常检测
AWS Cost Anomaly Detection、Azure Cost Management Anomaly、GCP Recommender — 这些都是只需点击几下即可开启的免费功能。阈值最初可以保守设置(例如:超过日均值的30%),然后根据警报疲劳度进行调整。
③ 每周差异审查
每周30分钟,基础设施团队和财务负责人会面,审查上一周的差异。将差异原因分为以下三类:
- 正常业务波动(流量增加)
- 有意变更(新功能发布)
- 异常(事故、未删除资源、错误部署)
只有第三类会成为行动项。
④ 噪音清理常态化
每周或每两周清理一次闲置资源。此时重要的是观念的转变:
清理不是为了降低成本,而是为了看到信号。
团队全体成员必须共享这一框架,才能使清理文化得以持续。
⚠️ 常见陷阱
- 对精确预测的执着 — 如果强制要求准确性,就会有人开始说谎。
- 季度审查 — 对于云来说,按季度审查太晚了。日/周是基本单位。
- 警报阈值设置过于保守 — 如果警报疲劳累积,即使是真正的警报也会被忽略。
- 在忽视噪音的情况下,只精细化预测模型 — 如果信噪比低,任何模型都无法奏效。
- 将差异视为简单误差 — 差异是学习信号。它应该成为下一个周期的输入。
✅ 总结
- 云成本是信号处理,而非预算管理。
- 精确预测是幻想,“狭窄的容许范围 + 快速检测”才是真正的目标。
- 运营模式是预测 → 观察 → 调整的短周期。
- 核心指标已从预测准确性转向MTTD、标签覆盖率和闲置资源率。
- 未删除资源的真正罪名不是成本本身,而是它们会成为遮蔽信号的噪音。
犯错是正常的。无知才是事故。
发表回复