心電図にノイズが混じると、本当に見るべき不整脈が見えなくなります。
クラウド費用も同じです。
>

この記事で扱うこと
- クラウド費用予測が本質的に難しい理由
- 従来のIT予算モデル vs クラウド予算モデルの決定的な違い
- FinOpsの運用サイクル — Forecast → Observe → Adjust
- 主要指標がForecast AccuracyからAnomaly Detection Timeへ移行した理由
- 未削除リソースの本当の罪 — コスト漏洩ではなくシグナル隠蔽
±5%予測という幻想
従来のIT予算は、±5%の精度を基本とします。サーバーを100台購入すれば、その100台が5年間減価償却されるため、予測は実質的に一度の掛け算で済みます。CFOが扱いやすいモデルです。
しかし、クラウドはこのモデルを真っ向から否定します。
- トラフィックは毎週異なります
- 機能を一度リリースすると、コスト構造が変わります
- データパイプラインを一度実行すると、その月の請求書が2倍になります
- 誰かがGPUインスタンスを起動したまま忘れると、数日で数百万円が追加請求されます
このような環境で±5%の予測は嘘です。嘘で組まれた予算は最初の四半期で破綻し、2番目の四半期には誰もがその数字を無視し始めます。
クラウドは「変動性そのもの」です
FinOps Foundationが最も強く釘を刺す原則があります。
“Cloud is variable by nature. Manage variability — don’t try to eliminate it.”
クラウドの変動性は欠陥ではなく特性です。変動性をなくそうとすると、クラウドの最大の利点である弾力性(Elasticity) まで一緒に失われます。RIやSavings Planも結局「どこまで変動性を受け入れるか」を定めるツールに過ぎず、変動性自体をなくすことはできません。
そのため、実務におけるクラウド費用管理の最初の気づきはこれです。
「当てようとせず、範囲内に留まれ。」
目標指標自体が変わります。
| 項目 | 従来のIT | FinOps |
| 予測精度 | ±5% | ±12~15% (優秀), ±20% (合格) |
| 予算レビュー周期 | 四半期 | 日/週単位 |
| 主要KPI | 予算遵守率 | 異常検知時間(MTTD) |
—
真の運用モデル: Forecast → Observe → Adjust
クラウド費用管理は、次の短いサイクルで運用されます。
1. Forecast — ガードレールを設定する
月初に「この範囲内であれば正常」という許容範囲を定めます。正確な数字ではありません。この範囲が、Budget AlertとAnomaly Detectionの基準点となります。
2. Observe — 日次で実際の費用を確認する
Cost Explorer Daily Report、Cost Anomaly Detectionアラート、Slackボット — どのようなツールでも構いません。肝心なのは、「請求が1日以上気づかれずに過ぎることがないようにする」ことです。
3. Adjust — Varianceを分析し、モデルを更新する
予測と実際の差異(Variance)を毎週または毎月レビューします。大きな差異があった場合は原因を分類し、翌月の予測モデルに反映します。外れたことを認め、モデルを更新することがFinOpsの誠実さです。
このサイクルの本質は単純です。
間違えることは正常であり、早く気づくことが肝心である。
したがって、費用管理は会計問題ではなく「信号処理問題」です
ここで、本当に興味深い視点が登場します。クラウド費用管理は本質的に会計ではなく信号処理(Signal Processing) に近いのです。
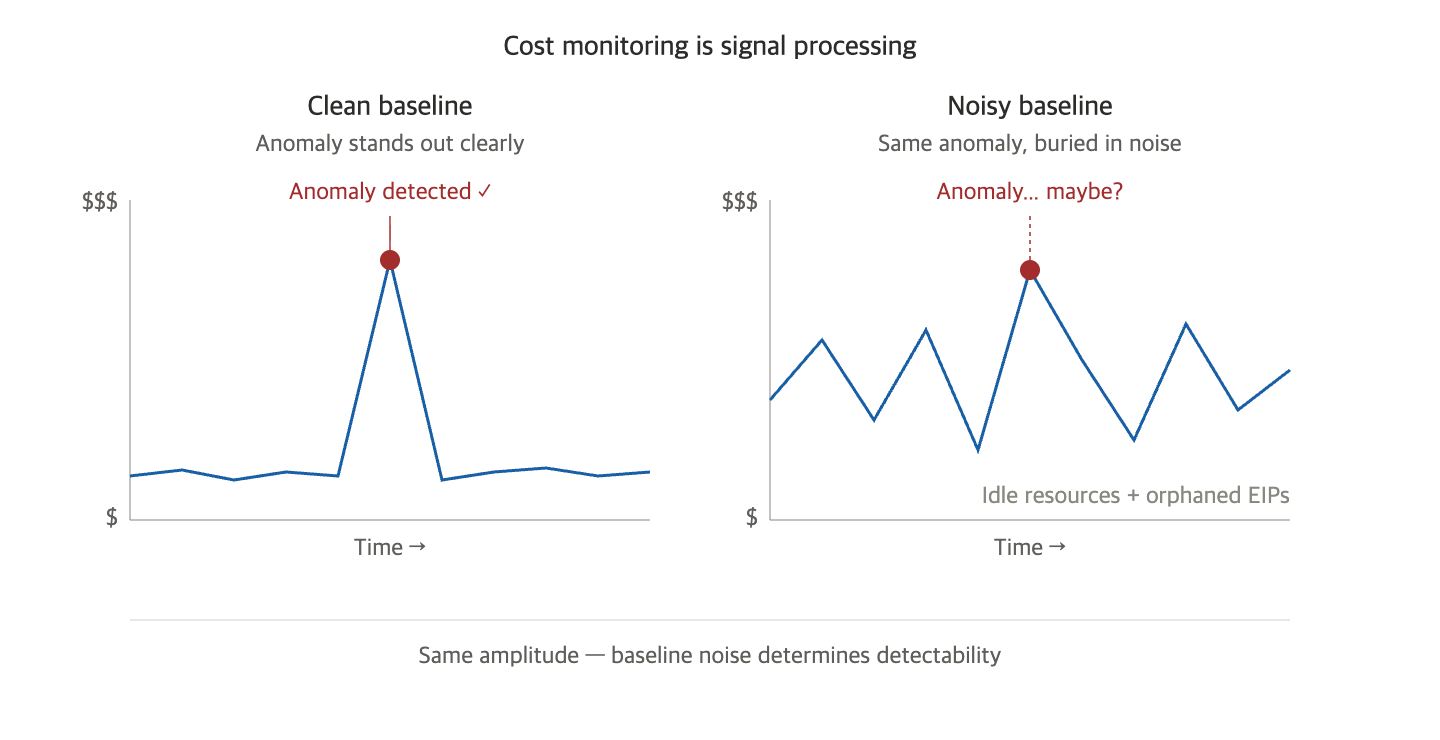
心電図を思い浮かべてみてください。正常な心拍は一定のベースラインの上に小さな振幅で流れます。その上に不整脈が発生すると、鋭いスパイクが明確に現れます。医師はこのスパイクを見て応急処置を行います。
しかし、もし機械自体がノイズを発しており、ベースラインが不安定だったらどうでしょうか? 同じ不整脈が発生しても、ノイズに埋もれて見えなくなります。 患者は危険に陥り、医師は異常の発見が遅れます。
クラウド費用も全く同じ構造です。
- ベースライン — 通常の運用にかかる正常な費用
- シグナル — 本当に捉えるべき異常 (トラフィック急増、誤ったデプロイ、セキュリティ事故によるリソース暴走)
- ノイズ — 未削除リソース、浮遊するEIP、忘れられたGPU、責任者不明な資産
異常検知は結局、信号対雑音比(SNR, Signal-to-Noise Ratio) が決定します。ノイズが大きいと、同じシグナルが埋もれてしまいます。そのため、未削除リソースをクリーンアップする本当の価値は、費用削減ではなく「異常を早く検知できるクリーンなベースラインを維持すること」なのです。
そのため、主要指標が移行しました
伝統的に「予算管理が上手な部署」は予測精度が高い部署でした。しかし、クラウド時代の「費用管理が上手な組織」は、異なる指標で測定されます。
- MTTD (Mean Time To Detect) — 費用異常発生から検知までにかかった時間
- Variance Explainability — 予測との差異をどの程度説明できるか
- Tagged Coverage Ratio — 全体費用の中で責任者が明確な割合
- Idle Resource Ratio — 使用されていないリソースが占める割合
±5%の精度は姿を消し、「24時間以内の検知」、「90%以上のタグカバレッジ」といった指標がその座を代替します。
実務でクリーンなベースラインを維持する4つのパターン
① 日次費用レビューの自動化
毎朝Slackに「昨日の費用 + 7日間平均 + 差異 %」が自動投稿されるようにします。人が毎日コンソールを覗き込む運用は決して持続しません。
# AWS CLI — 昨日の費用を取得する簡単な例
aws ce get-cost-and-usage
--time-period Start=$(date -d 'yesterday' +%Y-%m-%d),End=$(date +%Y-%m-%d)
--granularity DAILY
--metrics UnblendedCost② Cost Anomaly Detectionの有効化
AWS Cost Anomaly Detection、Azure Cost Management Anomaly、GCP Recommender — これらは数クリックで有効にできる無料機能です。しきい値は最初は保守的に(例: 日次平均の30%超過)設定し、アラート疲労度を見ながら調整します。
③ 週次Varianceレビュー
毎週30分、インフラチームと財務担当者が集まり、先週のVarianceを検討します。差異の原因を次の3つに分類します。
- 正常な事業変動 (トラフィック増加)
- 意図された変更 (新規機能リリース)
- 異常 (事故、未削除リソース、誤ったデプロイ)
3番目のみがアクションアイテムとなります。
④ ノイズクリーンアップの定例化
週次または隔週でアイドルリソースを整理します。この時重要なのは認識の転換です。
費用を減らすためにクリーンアップするのではなく、シグナルを見るためにクリーンアップするのだ。
このフレームワークをチーム全体で共有することで、クリーンアップ文化が持続します。
⚠️ よくある落とし穴
- 正確な予測への強迫観念 — 精度を強制すると、誰かが嘘をつき始めます
- 四半期単位のレビュー — クラウドでは四半期単位では遅すぎます。日/週単位が基本です
- アラームしきい値を保守的にしすぎる — アラート疲労が蓄積すると、本当のアラームも無視されます
- ノイズを放置したまま予測モデルだけを精緻化する — SNRが低いと、どんなモデルも機能しません
- Varianceを単純な誤差と見なす — Varianceは学習シグナルです。次のサイクルへの入力となるべきです
✅ まとめ
- クラウド費用は予算管理ではなく信号処理です
- 正確な予測は幻想であり、「狭い許容範囲 + 迅速な検知」が真の目標です
- 運用モデルはForecast → Observe → Adjustの短いサイクルです
- 主要指標はForecast AccuracyからMTTD、Tagged Coverage、Idle Ratioへ移行しました
- 未削除リソースの本当の罪は費用そのものではなく、シグナルを隠蔽するノイズとなることです
間違えることは正常です。知らないことが事故です。
コメントを残す