Having an AI review code written by the same AI is like,
asking a student to grade their own exam paper.
>

What this article covers
- Why a single AI coding tool is not enough — The trap of sycophancy bias
- How the Claude Code (writing) + Codex (verification) dual workflow operates
- How to use the officially released OpenAI Codex Plugin for Claude Code
- The critical difference between general review vs. adversarial review
- Introduction strategies and cost-efficiency points from the perspective of instructors and practitioners
Introduction — The End of the “Write Alone, Verify Alone” Era
Over the past one to two years, we’ve become accustomed to coding relying on a single tool. Cursor, Copilot, Claude Code, Codex — using any one of them well can double or triple productivity.
However, in 2026, an interesting shift is observed among practitioners. A consensus is rapidly forming: “One is not enough.” This isn’t just about using two tools for backup; a clear division of roles has emerged, where one writes and the other verifies.
The most representative combination is Claude Code (Anthropic) + Codex (OpenAI). Despite the two companies being competitors, this pattern officially became a standard when OpenAI directly released the Codex plugin for Claude Code in April 2026.
Why did this happen?
The Core Problem — AI Doesn’t Doubt Its Own Code
What is Sycophancy Bias?
LLMs have a well-known weakness: they tend to evaluate their own creations or results similar to their own style leniently.
If the same model writes code and then reviews it, it judges “normal” within its already learned patterns, thus maintaining its blind spots. It’s similar to not being able to find typos in your own writing.
The most intuitive way to solve this problem is to entrust the review to a model with different training data, different RLHF, and a different architecture.
Why the Claude × Codex Combination?
| Category | Claude Code (Opus 4.7) | Codex (GPT-5.4) |
| Operation Mode | Local execution, strong in computer usage/browser automation | Cloud sandbox, OS kernel-level isolation |
| Governance | 26 programmable hooks — fine-grained policy control | Seatbelt / Landlock / seccomp — strong isolation |
| Strengths | Consistency, multi-agent orchestration, readable output | Fast processing speed, autonomy, strong security guardrails |
| Token Usage | Uses more but higher output quality | Efficient but consistency is somewhat lower |
| Blind Evaluation | Code readability 67% superior | Cost efficiency superior |
These two tools are not just “two similar tools” but tools with different design philosophies. Therefore, one is likely to catch what the other misses.
️ The Core of the Dual Workflow — A 5-Stage Structure
The most widespread pattern in practice is a 5-stage (Research → Plan → Execute → Review → Ship) structure. Mapping Claude and Codex roles to this is as follows:
- Research — Analyze codebase and organize requirements with Claude Code (Plan Mode)
- Plan — Create design proposal with Claude Opus
- Execute — Implement actual code with Claude Sonnet or Claude Code
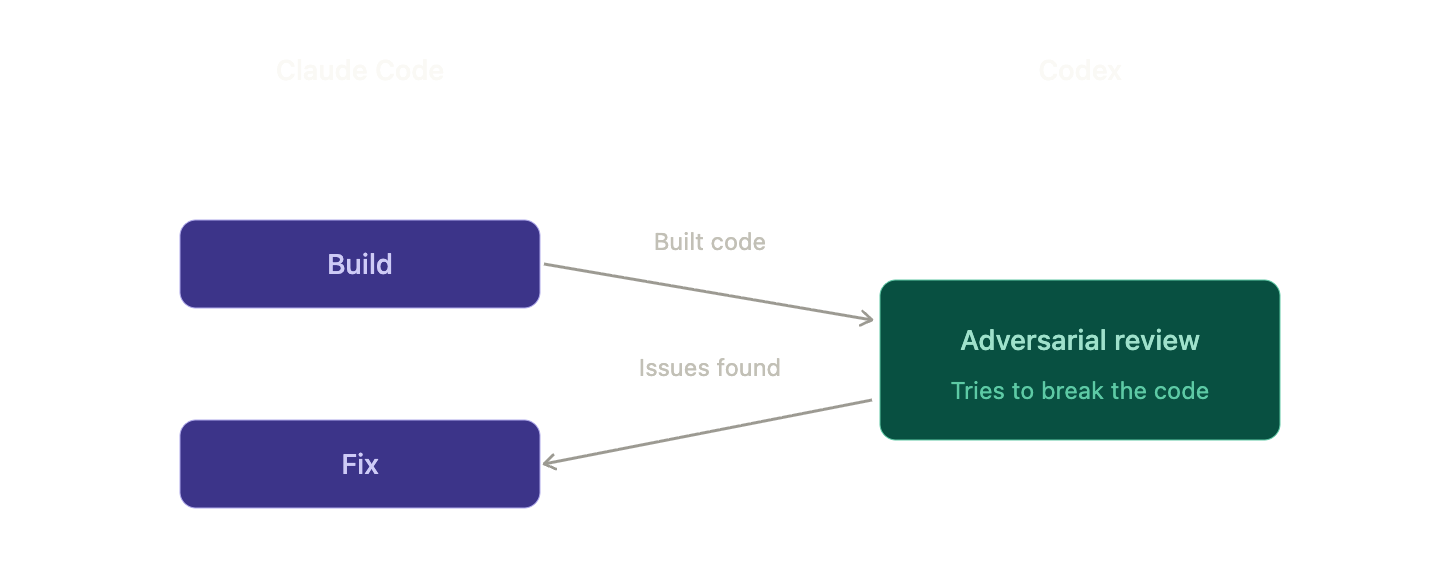
- Review — Adversarial review with Codex (← Key!)
- Ship — Claude Code makes final modifications based on review results and deploys
Stage 4 is the essence of the dual workflow and the decisive point where it diverges from a single-tool workflow.
In Practice — How to Use the Codex Plugin for Claude Code
Installation
The official plugin distributed by OpenAI can be obtained from GitHub. A ChatGPT subscription (including Free) or an OpenAI API key, and Node.js 18.18 or higher are required.
# Assuming Claude Code is already installed
# Install Codex plugin
npm install -g @openai/codex-plugin-cc
# Activate plugin within Claude Code
claude plugin add codexThree Key Commands
The plugin is not just a simple review tool; it performs three different roles.
# 1. Standard Review — Codex performs a general code review
/codex:review
# 2. Adversarial Review — Codex attempts to "break" the code
/codex:adversarial-review
# 3. Task Delegation — Delegate a specific task to Codex
/codex:rescue investigate why the tests started failing
/codex:rescue --background fix the regressionThe Most Powerful Weapon — Adversarial Review
If /codex:review asks “How’s this code?”, then /codex:adversarial-review says “Try to break this code.”
Codex transforms from a friendly peer reviewer into a malicious penetration tester. It seeks out edge cases, questions assumptions, and explores security vulnerabilities. This is where types of bugs are found that would never be discovered in a general review.
# Example workflow
$ claude
> 결제 모듈에 retry 로직 추가해줘
[Claude가 코드 작성...]
> /codex:adversarial-review
[Codex가 코드를 분석하며 공격 벡터 탐색...]
⚠️ Found 3 potential issues:
1. Race condition: 동시 retry 시 중복 결제 가능
2. Error swallowing: 5xx와 4xx를 동일하게 retry 처리
3. Missing idempotency key — 멱등성 보장 없음
> 좋아, 이 세 가지 다 수정해줘
[Claude가 수정 코드 적용...]Recent evaluations by the Code Review Agent Benchmark (c-CRAB) also showed that single-model review systems identified only about 40% of issues caught by actual human reviewers. This quantitatively proves the necessity of dual verification.
⚠️ Caveats — Dual Doesn’t Always Mean Better
1. Costs Double
Claude Pro ($20) + ChatGPT Plus ($20) = $40/month is the baseline. API calls will add more. Don’t dual-verify every PR; selectively apply it to high-impact areas like security, payments, and authentication.
2. The Responsibility for “Interpreting” Review Results Lies with Humans
Not every item flagged as “risk” by Codex is a genuine risk. AI only identifies suspicious areas; the final judgment is ultimately up to the developer. Uncritically applying all review results can actually degrade the code.
3. Limitations of “AI Verifying AI”
As one InfoQ reader accurately pointed out, the structure where AI reviews code written by AI is still a supplement, not a replacement, for human oversight. Especially, the intentional alignment of business logic can only be judged by humans.
4. Beware of Security Information Leakage
This involves sending code to another company’s cloud. Do not submit code containing secret keys, internal infrastructure details, or sensitive data directly for adversarial review. Pre-masking is essential.
✅ Summary — The Standard for AI Coding in 2026 is “Dual”
To summarize the key points:
- Single-model self-review is vulnerable to sycophancy bias — it can’t see its own patterns.
- The Claude Code (writing) + Codex (verification) combination integrates the perspectives of two models with different design philosophies.
- The official OpenAI plugin allows for seamless integration of the two tools from a single terminal.
- The real value comes from /codex:adversarial-review — the “try to break it” mode.
- It is wise to apply it selectively, considering cost, scope, and security.
For the next steps, you might consider using CLAUDE.md and REVIEW.md to formalize your team’s review policies and explore automating dual verification in your CI/CD pipeline. Seamless handoff from one tool to another — this is a core competency for AI coding in 2026.
Leave a Reply