“Tell the server ‘what it should be’, not ‘what to do’.”
— This single sentence has transformed the landscape of API design over the past decade.
>

>
Numerous API design approaches (rivers) that once diverged are now converging into one massive standard (ocean).
What this article covers
- Fundamental differences between traditional REST and k8s-style APIs
- The power of the five core components: apiVersion / kind / metadata / spec / status
- Principles of the Declarative model and Reconciliation Loop
- Why Crossplane, ArgoCD, Istio, and Knative have all adopted the k8s style
- Practical tips you must consider when designing your API in this style
Introduction — The long-standing dilemma of REST designers
Anyone who has designed a REST API has probably faced these dilemmas at some point:
- User creation is clean with POST /users, but where should we put user activation?
- POST /users/{id}/activate? This is a verb, doesn’t it go against REST philosophy?
- When adding roles, should it be POST /users/{id}/roles or PUT /users/{id}?
The reason this dilemma repeats endlessly is simple: traditional REST started with “CRUD for resources,” but actual business logic is mostly a series of “state transitions.” Activation, approval, cancellation, retry — all of these have been forcibly squeezed into REST’s grammar.
However, since 2015, as the cloud-native ecosystem has exploded, a quiet but powerful change has occurred. The API design approach demonstrated by Kubernetes has become the de facto standard. Crossplane, ArgoCD, Istio, Knative, Tekton, KubeVirt — well-known projects all use the same API pattern. Even cloud providers like AWS Controllers for Kubernetes (ACK) and GCP Config Connector have started wrapping their own resources with k8s-style APIs.
Why?
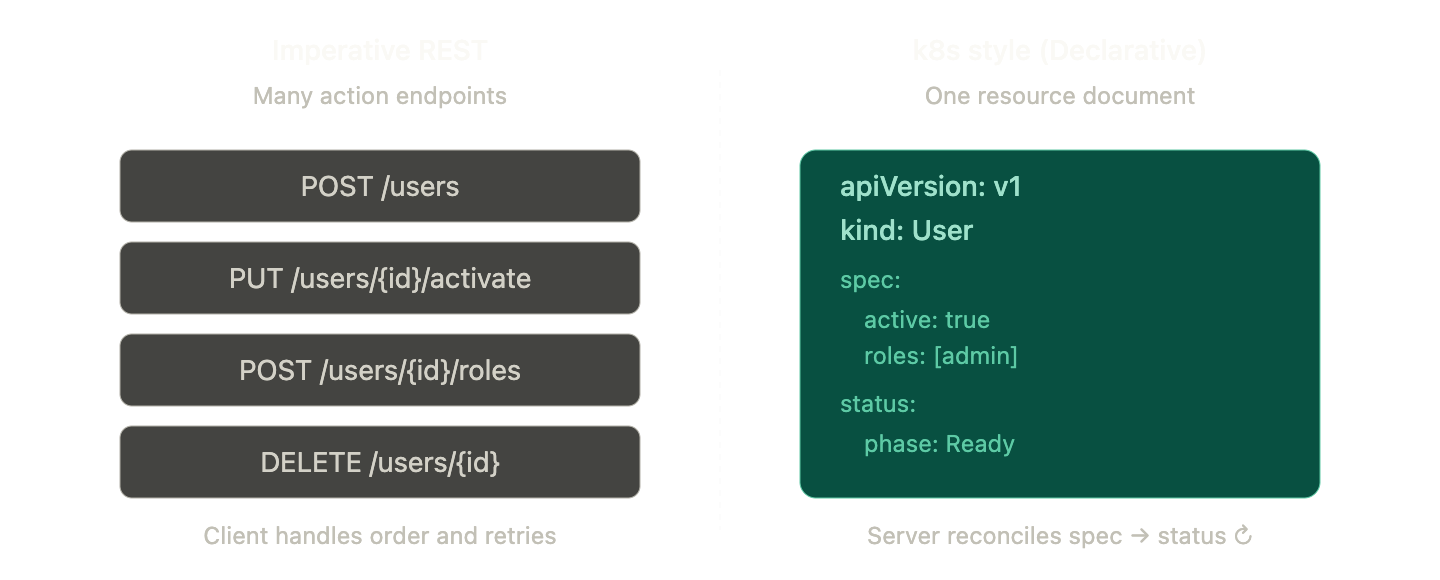
Imperative vs. Declarative — The biggest paradigm shift
Traditional REST is “Imperative”
POST /users → 생성해라
PUT /users/{id}/activate → 활성화해라
POST /users/{id}/roles → 역할을 추가해라
DELETE /users/{id} → 삭제해라The client instructs the server “what to do.” Each request is an action, and if it fails, the client must implement retry logic directly. Calling it twice might execute it twice (idempotency issue).
k8s style is “Declarative”
apiVersion: v1
kind: User
metadata:
name: dohyeon
spec:
active: true
roles:
- admin
- developerThis YAML is sent once via PUT /apis/v1/users/dohyeon. The server compares the current state (status) with the desired state (spec) and reconciles the differences itself. This is the Reconciliation Loop.
The client only needs to declare “what it should be.” Activation, role addition, deletion — all of these are integrated into a single endpoint, a single resource document.
Why is this important?
The most difficult problem in distributed systems is partial failure. Networks break, requests are duplicated, and order is scrambled. To handle this with imperative APIs, the client must manage complex state machines directly. However, declarative APIs are designed with convergence in mind, so sending the same request multiple times yields the same result. This is why GitOps, Infrastructure as Code, and k8s-style APIs are a perfect match.
The 5 Pillars of k8s API
k8s-style resources always have the following five fields:
apiVersion: apps/v1 # (1) Which API group/version (GVK)
kind: Deployment # (2) What kind of resource is it
metadata: # (3) Common metadata
name: web-server
namespace: production
labels:
app: frontend
annotations:
team: platform
spec: # (4) Desired state (written by user)
replicas: 3
selector:
matchLabels:
app: frontend
status: # (5) Actual state (written by controller)
replicas: 3
availableReplicas: 3
conditions:
- type: Available
status: "True"This structure embodies a deep philosophy.
- apiVersion + kind — Uniquely identifies resources by Group/Version/Kind (GVK). Existing APIs are not broken when versions are updated.
- metadata — Name, namespace, labels, and annotations are shared by all resources. This enables unified searching, filtering, and ownership tracking.
- Separation of spec / status — Physically separates the user-defined area (spec) from the system-managed area (status). This clarifies who is responsible for what.
Following these five pillars allows existing tools like kubectl, Helm, ArgoCD, and Crossplane to work out of the box. This is the compounding effect of standardization.
Reconciliation Loop — Simple yet the most powerful idea
The heart of k8s is the Controller. A controller continuously runs this loop:
- Observes the current state (status).
- Compares it with the desired state (spec).
- If there’s a difference, it takes action to reduce that difference.
- Returns to step 1.
Thanks to this loop, three incredible properties come for free:
- Self-healing — If a Pod dies, the controller automatically recreates it. The client doesn’t need to retry.
- Event-driven — Receives real-time streams of changes via the Watch API (GET /apis/…/pods?watch=true). Frees you from polling hell.
- Idempotency — Even if the same spec is sent 100 times, the loop converges it only once.
Why it became the standard — 5 decisive reasons
1. CRDs allow anyone to create APIs with the same structure
Custom Resource Definition (CRD) solves the problem of “I want to use my company’s resources like k8s resources” with a single YAML file. OpenAPI schema, validation, versioning, Watch — all come for free.
2. kubectl, a unified client
kubectl get, kubectl apply, kubectl describe, kubectl logs. The command system is the same regardless of the resource. The cost of learning new tools converges to almost zero.
3. Perfect synergy with GitOps
Because it’s declarative, you can upload YAML to a Git repository, and ArgoCD/Flux will sync the “desired state” directly to the cluster. Git becomes the Single Source of Truth.
4. Operator pattern for codifying operational know-how
Operational know-how such as database backup, Kafka rebalancing, and Redis cluster failover can be embedded within the controller. No need for humans to wake up at 3 AM to SSH.
5. Compounding effect of the ecosystem
When Crossplane abstracted AWS resources in a k8s style, it became possible to manage AWS S3 buckets with GitOps using ArgoCD. A network effect where tools call other tools. This trend is irreversible.
Building your own k8s-style API
Even without Kubernetes, this style can be adopted in general backend systems. Let’s look at a simple example with FastAPI.
from fastapi import FastAPI
from pydantic import BaseModel
from typing import Optional, List
app = FastAPI()
class Metadata(BaseModel):
name: str
labels: Optional[dict] = {}
class UserSpec(BaseModel):
active: bool = True
roles: List[str] = []
class UserStatus(BaseModel):
phase: str = "Pending" # Pending | Ready | Failed
observed_generation: int = 0
class User(BaseModel):
apiVersion: str = "v1"
kind: str = "User"
metadata: Metadata
spec: UserSpec
status: Optional[UserStatus] = None
# The user only sends the spec. The controller fills in the status.
@app.put("/apis/v1/users/{name}")
def apply_user(name: str, user: User):
# 1) Save spec
# 2) A separate worker (controller) observes the actual state and updates the status
return {"applied": user.metadata.name}
# Watch provides a stream of changes via SSE/WebSocket.The key is to maintain the boundary: “users write only the spec, and the system writes the status.” Just by adhering to this boundary, the responsibilities of the API become much clearer.
⚠️ Cautions / Common Mistakes
- Do not let users write to status. If the spec/status separation principle is broken, the basis of the reconciliation loop is undermined. Server-side writing to status must be blocked.
- Do not mix imperative endpoints. Adding something like POST /users/{id}/activate halves the benefits of the declarative approach. First, consider if activation can be expressed as spec.active: true.
- Manage version compatibility with GVK. Plan for the v1beta1 → v1 transition from the outset, and design a conversion webhook or equivalent mechanism.
- Reconciliation is not free. Poorly designed loop cycles, backoffs, and error handling can lead to an infinite retry bomb. Exponential backoff and dead-letter queues are essential.
- Not all APIs need to be k8s-style. Simple read-only CRUD (e.g., blog post lists) is still better suited for traditional REST. k8s-style shines when there are state transitions and long-running operations.
✅ Summary / Conclusion
The reason k8s-style APIs became the standard can be summarized in one sentence:
“It solved the inherent difficulties of distributed systems at the API design level using a declarative approach.”
- The imperative → declarative shift is not just a matter of preference, but an engineering advantage in handling partial failures and convergence.
- The five pillars (apiVersion / kind / metadata / spec / status) are the foundation for extensibility and compatibility.
- The network effects of CRD, kubectl, GitOps, and the Operator pattern have led the ecosystem to a self-reinforcing stage.
- If you’re building a new cloud platform or tool, the free compatibility gained by following this style is enormous.
For the next step, I recommend trying to build your own CRD and Controller with Operator SDK / Kubebuilder, or managing cloud resources declaratively with Crossplane. Once you get used to this model, you’ll find it hard to go back to traditional REST.
Leave a Reply