「コンテナの上に載せれば、Kubernetesが全部自動でやってくれるんじゃないですか?」
多くの開発者が初めてKubernetesに触れるときに抱く誤解
>

🎯 この記事で扱うこと
- Kubernetes上にDBを載せても良い条件と、載せるべきではない理由
- ログ収集ツール(Fluent Bit、Lokiなど)をコンテナで構成しても問題ない理由
- プロダクションDBをKubernetes外部に分離する実際の理由
- ログデータの法的保存義務(韓国法令基準)
- 実務でよく使われる構成パターンと例
📌 導入 / 背景
Kubernetesが普及するにつれて、「すべてをコンテナで!」という流れが強くなりました。それに伴い、「DBもKubernetesの上に載せてはいけないのか?」という疑問が自然と生まれます。
短い答えは:「載せることはできる。しかし、プロダクション環境では慎重であるべきだ。」
Kubernetesはステートレス(stateless)ワークロードに最適化されたプラットフォームです。ウェブサーバー、APIサーバーのようにリクエストを受け取って応答するアプリケーションは、Podが死んで再起動しても大きな問題はありません。しかし、DBは異なります。データが消えれば終わりだからです。
では、ログはどうでしょうか?ログ収集エージェントとログ保存DBは、プロダクションDBとは性質が異なります。そして、ここには法的な考慮事項も絡んでいます。
これから一つずつ解説していきます。
🔍 Kubernetesの特性:なぜDBとの相性が難しいのか
Kubernetesは「使い捨て」の哲学を持つプラットフォーム
Kubernetesは、Podをいつでも終了して新しく作成できることを前提としています。これをEphemeral(一時的)な特性と呼びます。ノード障害、スケーリング、ローリングアップデート…あらゆる状況でPodはいつでも消滅する可能性があります。
DBはこの哲学と衝突します。DBの核心はデータの永続性(Persistence)です。
Kubernetesはこの問題を解決するためにPV/PVC(Persistent Volume / Persistent Volume Claim)を提供しますが、これが完璧な解決策ではありません。
プロダクションDBをKubernetes外部に分離する5つの理由
① データ永続性確保の難しさ
PVを使用しても、ノード全体がダウンしたり、ストレージバックエンドに問題が発生したりすると、データ損失のリスクがあります。クラウドマネージドDB(AWS RDS、Azure Databaseなど)は、マルチAZレプリケーション、自動バックアップ、ポイントインタイムリカバリ(PITR)を独自に提供します。
② StatefulSetの運用複雑性
KubernetesでDBを運用するにはStatefulSetを使用する必要があります。StatefulSetは各Podに固有のIDとストレージを付与し、順序のあるデプロイ/削除を保証します。しかし、MySQL InnoDB Cluster、PostgreSQL HA、MongoDB ReplicaSetのようなクラスタリング、フェイルオーバー、リーダー選出ロジックを直接管理するのは、かなりの運用負担です。
# StatefulSetの例 — K8sでDBを運用する場合
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: postgres
spec:
serviceName: "postgres"
replicas: 3
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:15
volumeMounts:
- name: pgdata
mountPath: /var/lib/postgresql/data
volumeClaimTemplates: # 各Podごとに個別のPVCを作成
- metadata:
name: pgdata
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 50Gi上記の構成だけでも複雑です。これにバックアップCronJob、モニタリングExporter、ネットワークポリシー、セキュリティコンテキストまで加わると、運用チームの負担は倍増します。
③ ネットワークレイテンシとストレージI/O性能
Kubernetesのネットワークはオーバーレイネットワーク(CNI)を介して動作します。DBは高速I/Oと低レイテンシが重要ですが、コンテナ化によるネットワークオーバーヘッドとストレージ抽象化レイヤーが性能に影響を与える可能性があります。特にNVMe SSDに直接アクセスするベアメタルDBと比較して性能差が生じることがあります。
④ セキュリティ隔離の難しさ
コンテナはOSカーネルを共有します。もし同じノード上の他のコンテナが脆弱性を介してノードにアクセスした場合、DBデータまで危険にさらされる可能性があります。マネージドDBサービスは専用インフラで隔離されて運用されます。
⑤ ライセンスおよび運用ツールの互換性
Oracle、MS SQL Serverのような商用DBは、コンテナ環境に対するライセンスポリシーが複雑で、公式サポートレベルがベアメタルよりも低い場合があります。
🪵 ではログ(Log)DBはKubernetesに載せても良いのか?
ログ収集アーキテクチャの特性
ログシステムは大きく3つの層に分かれます:
| 層 | 役割 | 例示ツール |
| 収集エージェント | 各Pod/Nodeからログを収集 | Fluent Bit, Filebeat |
| 集計/処理 | パース、フィルタリング、ルーティング | Fluentd, Logstash |
| 保存/検索 | ログの保存および検索 | Loki, Elasticsearch, ClickHouse |
収集エージェント — コンテナで運用するのが自然
Fluent Bitのようなログ収集エージェントは、DaemonSetとしてデプロイするのが標準パターンです。DaemonSetは各ノードに1つずつPodをデプロイします。これは、ノードレベルのログファイル(/var/log/containers/)にアクセスしてログを収集する役割だからです。
# Fluent Bit DaemonSetの主要部分
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluent-bit
namespace: logging
spec:
selector:
matchLabels:
app: fluent-bit
template:
spec:
containers:
- name: fluent-bit
image: fluent/fluent-bit:2.2
volumeMounts:
- name: varlog
mountPath: /var/log # ホストログディレクトリのマウント
readOnly: true
- name: containers
mountPath: /var/lib/docker/containers
readOnly: true
volumes:
- name: varlog
hostPath:
path: /var/log
- name: containers
hostPath:
path: /var/lib/docker/containersエージェント自体は状態を保存しません。Podが死んでも再起動すれば、その時点からログを収集すれば問題ありません(若干の収集空白は発生する可能性がありますが、致命的ではありません)。
ログ保存DB — どこに載せるかは要件次第
ログ保存DB(例:Loki、Elasticsearch)をKubernetesに載せることは、運用DBよりも許容範囲が広いです。
理由は以下の通りです:
- ✅ ログは一部が失われてもビジネスに致命的ではない場合が多い
- ✅ ログデータは再生成不可能なオリジナルデータではない(ソースはアプリケーションにある)
- ✅ Loki、ElasticsearchともにKubernetes環境を公式サポートするHelm Chartを提供
- ✅ Grafana + Loki + Fluent BitスタックはKubernetesネイティブロギングの事実上の標準
ただし、法的保存義務があるログの場合は話が変わります。次のセクションで詳しく説明します。
⚖️ 法的問題 — ログをどのように保存すべきか?
この部分は実務で軽視されがちですが、非常に重要です。
韓国主要法令におけるログ保存義務
| 法令 | 対象 | 保存項目 | 保存期間 |
| 個人情報保護法 | 個人情報取扱者全体 | 個人情報処理システム接続記録 | 最低6ヶ月(1万人以上または機微情報:2年) |
| 情報通信網法 | 情報通信サービス提供者 | 個人情報取扱者接続記録 | 最低6ヶ月 |
| 電子金融取引法 | 金融機関、電子金融業者 | 電子金融取引記録 | 5年 |
| 電子商取引法 | オンラインショッピングモールなど | 契約・申込記録、代金決済記録など | 5年(契約)、3年(苦情処理) |
| 医療法 | 医療機関 | 診療記録、診療関連電算記録 | 10年(診療記録簿基準) |
> 📌 個人情報保護法施行令第30条:接続記録の保存・点検義務。1万人以上の情報主体または固有識別情報・機微情報を処理する場合、最低2年間の保存および月1回以上の点検義務。
法的保存義務のあるログをKubernetesのみに置くべきではない理由
Kubernetes内のPVは、インフラ変更、クラスタ移行、運用ミスにより削除されるリスクがあります。法的保存義務のあるログは、必ず以下の条件を満たす必要があります:
- ✅ 削除・改ざん防止:アクセス制御 + 不変ストレージ(WORM, Write Once Read Many)
- ✅ 長期保存:義務期間中、安定的に保存
- ✅ 検索および監査:保存機関や調査機関の要請時に即座に提供可能
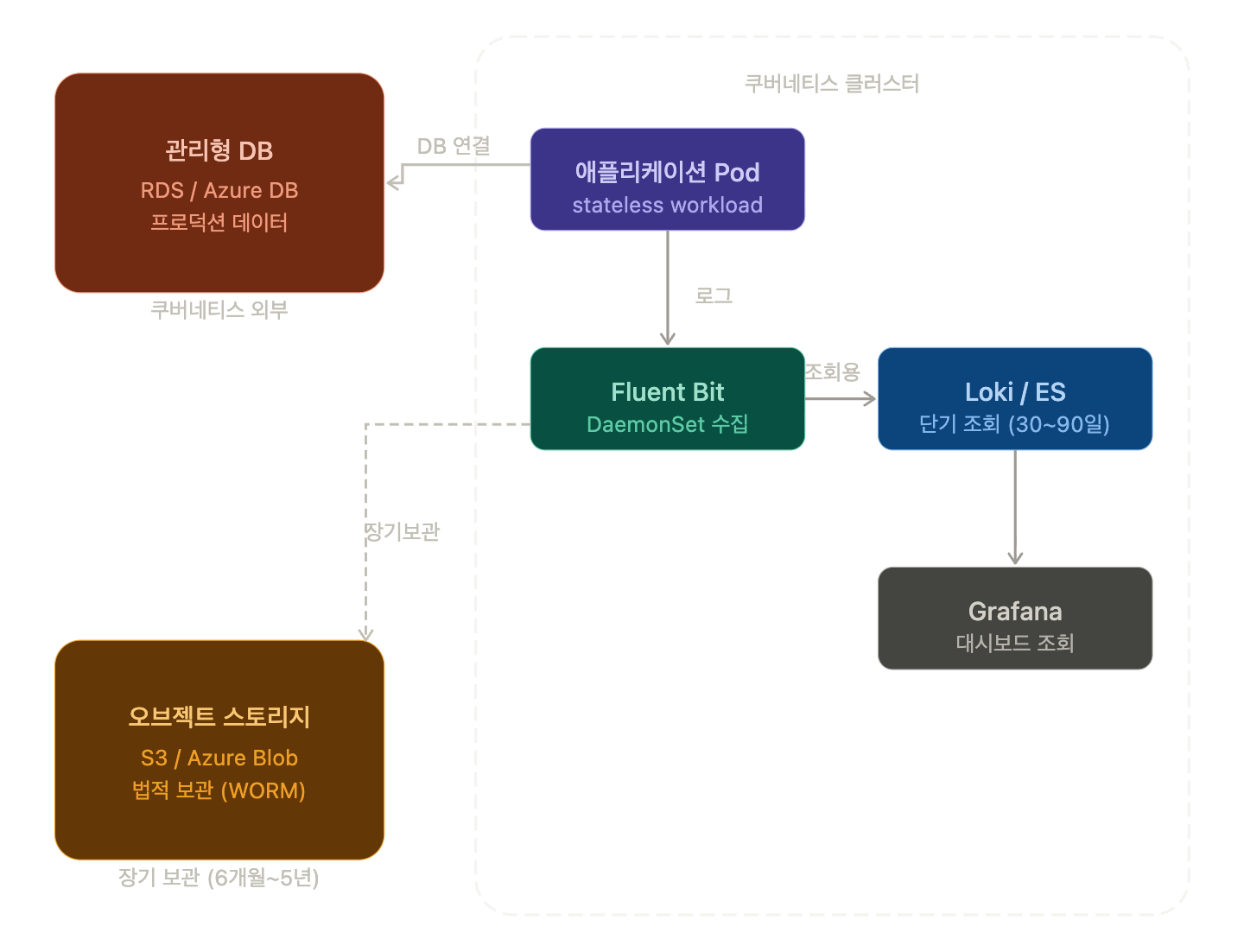
推奨アーキテクチャ:Kubernetesで収集されたログは、クラウドオブジェクトストレージ(AWS S3、Azure Blob Storage、NCP Object Storage)に長期保存し、Kubernetes内部のログDBは短期参照目的のみに使用する二重構造を推奨します。
[Pod 로그]
→ Fluent Bit (DaemonSet, K8s 내)
→ Loki or Elasticsearch (K8s 내, 단기 조회용: 30~90일)
→ S3 / Azure Blob (장기 보관용, WORM 설정: 법정 기간)💻 実践例:Fluent Bit → S3 二重出力設定
# fluent-bit.conf — ログをLoki(参照用)とS3(長期保存用)に同時送信
[SERVICE]
Flush 5
Daemon Off
Log_Level info
[INPUT]
Name tail
Path /var/log/containers/*.log
Parser docker
Tag kube.*
Refresh_Interval 5
# 出力1: Loki(短期参照用)
[OUTPUT]
Name loki
Match kube.*
Host loki.monitoring.svc.cluster.local
Port 3100
Labels job=fluentbit
# 出力2: S3(法的保存用、長期)
[OUTPUT]
Name s3
Match kube.*
bucket my-log-archive-bucket
region ap-northeast-2
s3_key_format /logs/%Y/%m/%d/$TAG[4].%H%M%S.gz
compression gzip
use_put_object On
total_file_size 100M # 100MB単位でまとめて保存
upload_timeout 600 # 10分ごとに強制アップロード⚠️ 注意事項 / よくある間違い
① PV削除ミス
kubectl delete pvc コマンド一つでDBボリュームが削除される可能性があります。reclaimPolicy: Retain設定を必ず確認してください。
apiVersion: v1
kind: PersistentVolume
spec:
persistentVolumeReclaimPolicy: Retain # ← 必ずRetainに設定② ログ収集エージェントへの過度な権限付与
Fluent Bitにcluster-admin権限を与えるケースがありますが、これはセキュリティリスクです。最小権限の原則に従い、必要なRBAC権限のみを付与してください。
③ 法的保存ログをK8sクラスタ内部のみに保存
クラスタを削除したりPVが失われたりすると、監査対応が不可能になります。前述の二重保存構造を必ず構成してください。
④ ログに個人情報が含まれているか未確認
APIリクエストログ、エラーログに氏名、メールアドレス、IPアドレスなどの個人情報が含まれる場合、そのログ自体が個人情報処理に該当します。個人情報保護法に基づき、処理目的、保存期間、破棄基準を明確に定義する必要があります。
✅ まとめ / 締めくくり
区分 Kubernetes上での運用 推奨代替案
| 区分 | Kubernetes上での運用 | 推奨代替案 |
| プロダクションDB | ⚠️ 可能だが運用負担大 | マネージドDBサービス(RDS, Azure DBなど) |
| ログ収集エージェント | ✅ 推奨(DaemonSetパターン) | — |
| ログ保存DB(短期) | ✅ 可能(Loki, ES) | — |
| 法的保存義務ログ | ❌ K8s単独保存は危険 | オブジェクトストレージ + WORM併用 |
核心要約:
- 🐳 プロダクションDB:Kubernetes外部に分離。マネージドサービスを活用。
- 🪵 ログエージェント:DaemonSetとしてKubernetesに載せるのが標準。
- 📦 ログ保存DB:短期参照用はK8s内、法的保存義務ログはオブジェクトストレージに別途保存。
- ⚖️ 法的義務:個人情報保護法・電子金融取引法など該当法令を確認し、保存期間・方式を遵守。
次のステップとして、Grafana + Loki + Fluent BitスタックをHelmで直接構築する実習をお勧めします。
コメントを残す