“スケールアップは0秒、スケールダウンは5分。”
Kubernetes HPAがスケールダウンに意図的に遅延時間を設ける理由を掘り下げていきます。
この記事で扱うこと
- HPAがScale UpとScale Downをなぜ非対称に設計したのか
- 遅延時間(Stabilization Window)を設けないと発生する実際の問題 — フラッピング、コールドスタート、残存リクエスト
- K8s HPA v2のbehaviorフィールドで実務でチューニングする方法
- AWS Auto Scaling Group、GCP MIGなど他のクラウドも同じ哲学に従う理由
導入 — “トラフィックが減ったのにPodが減らない?”
初めてHPAを運用した方なら一度は経験したことがある場面でしょう。
トラフィックが瞬間的に急増すると、HPAは稲妻のようにPodを増やします。10秒もかからずに新しいPodが起動します。しかし、いざトラフィックが落ち着いた後も、Podはしばらくの間減少しません。「CPU使用率はすでに下がっているのに、なぜこいつは微動だにしないんだ?」という疑問が自然と湧いてきます。
結論から言うと、これはバグではありません。 Kubernetesの設計者たちが意図的にスケールダウンの速度にブレーキをかけているのです。むしろ、この「遅い縮小」が数多くの障害からサービスを守る防衛線となっています。
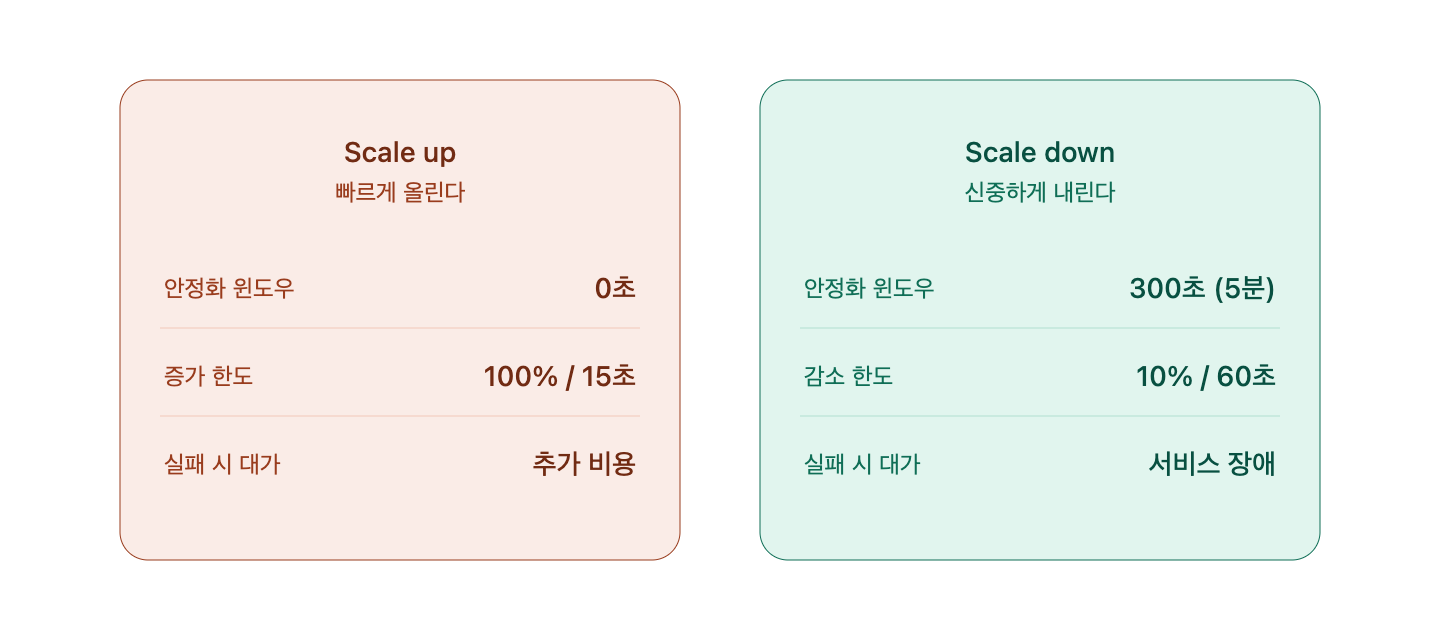
核心概念 — 非対称スケーリング (Asymmetric Scaling)
自動スケーリングは基本的に「スケールアップは素早く、スケールダウンはゆっくりと」という非対称の原則に従います。これはKubernetesだけの話ではありません。AWS Auto Scaling Groupのcooldown、GCP MIGのstabilization period、Azure VMSSのcooldownもすべて同じ哲学に基づいています。
スケールアップ判断 vs スケールダウン判断の重み
二つの判断の失敗コストは全く異なります。
- スケールアップ判断が間違っていた場合: Podがいくつか余分に起動している → わずかなコストの無駄
- スケールダウン判断が間違っていた場合: Podを減らした直後にトラフィックが集中 → サービス障害、顧客離脱、SLA違反
前者は財布が痛む程度ですが、後者はビジネスが崩壊します。この非対称なリスクこそが、非対称スケーリングの根拠です。
Kubernetesの基本設定
- –horizontal-pod-autoscaler-downscale-stabilization: デフォルト値 5分 (300秒)
- Scale Up stabilization window: デフォルト値 0秒 (即時)
なんと300倍もの差があります。この数字は軽々しく決められたものではなく、数多くの障害事例から得られた経験値です。
なぜ遅延を設けるのか — 5つの構造的理由
1️⃣ フラッピング(Flapping)防止
トラフィックは波のように動きます。30秒間隔でリクエストが集中したり引いたりするサービスは珍しくありません。もしスケールダウンが即座に行われると、このような事態が発生します。
- トラフィック減少 → Pod 2個縮小
- 30秒後トラフィック再増加 → Pod 3個増設
- 再び減少 → 縮小…
この無限ループをフラッピング(Flapping)またはスラッシング(Thrashing)と呼びます。クラスターリソースを浪費するだけでなく、Podが継続的に生成/削除されることで、後に続く「残存リクエスト」問題まで同時に発生します。
2️⃣ 残存リクエスト処理 (Graceful Shutdown)
Podを停止させることは、ファイルを削除することとは異なります。そのPodは今この瞬間もリクエストを処理しているからです。
- すでに進行中のHTTPリクエストの応答完了
- DBトランザクションコミット待機
- 外部APIコールの結果受信
- サービスエンドポイントから該当Podが外れるまでの伝播遅延
KubernetesはterminationGracePeriodSeconds(デフォルト30秒)を通じてこの時間を保証します。しかし、HPAが5秒ごとにスケールダウンを決定すると、Podは常にTerminating状態のまま生涯を終えることになります。ユーザーは5xxエラーを目にすることになるでしょう。
3️⃣ コールドスタート(Cold Start)コスト
「Pod一つ起動するのにどれくらいかかる?」と思うかもしれませんが、現実はかなり長いです。
- イメージプル(Pull):数秒〜数十秒(イメージサイズによる)
- コンテナ起動:1〜5秒
- アプリケーション初期化:JVMベースは10秒以上も珍しくない
- Readiness Probe通過:追加で数秒
- 合計:短い場合は15秒、長い場合は1分以上
停止させたPodを再び起動するには、この時間を丸ごと支払う必要があります。その間に残りのPodがトラフィックに耐えられるでしょうか?コールドスタート中に応答遅延が急増したり、タイムアウトが発生しやすくなります。
4️⃣ ウォームアップされた状態の維持
これはしばしば見過ごされるポイントです。稼働中のPodは単に「メモリにプロセスがある状態」ではありません。
- JVM JITコンパイル:頻繁に呼び出されるメソッドがネイティブコードにコンパイルされている
- DB Connection Pool:すでに開いているTCP接続が確保されている
- OS Page Cache:頻繁に読み込まれるファイルがメモリにロードされている
- アプリケーション内部キャッシュ:セッション情報、検索結果など
Podを停止させると、このウォームアップされた資産がすべて失われます。新しく起動したPodはしばらくの間、遅い状態でリクエストを受け取ることになり、これはp99レイテンシースパイクに直結します。
5️⃣ メトリックのノイズフィルタリング
CPU使用率やリクエスト数は瞬間的に跳ね上がりやすいものです。ガベージコレクションが一度、バッチ処理が一度行われるだけでも数値は大きく変動します。
もし5秒間のメトリック減少だけを見てすぐにスケールダウンすると、実際にはノイズに反応していることになります。5分間の観測ウィンドウを設けることで、このような瞬間的な変動を平均化し、真のトラフィック減少傾向を判断できます。
実際の構成 — HPA v2 behaviorチューニング
Kubernetes HPA v2からは、behaviorフィールドでこの非対称性を細かく調整できます。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 2
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
behavior:
scaleUp:
stabilizationWindowSeconds: 0 # 即時スケールアップ
policies:
- type: Percent
value: 100 # 一度に最大100%の増加を許可
periodSeconds: 15
scaleDown:
stabilizationWindowSeconds: 300 # 5分間監視後にスケールダウン
policies:
- type: Percent
value: 10 # 一度に最大10%のみ減少
periodSeconds: 60主要なポイントを解説します。
- scaleUp.stabilizationWindowSeconds: 0 — スケールアップ時はためらわない
- scaleDown.stabilizationWindowSeconds: 300 — スケールダウン時は5分間監視する
- scaleDown.policies.value: 10 — 一度に10%以上は絶対にスケールダウンしない
トラフィック変動が大きいリアルタイムサービス(ストリーミング、ゲーム、広告入札など)の場合、stabilizationWindowSecondsを10分以上に増やすのが一般的な実務上の選択です。
⚠️ 注意事項 / よくある間違い
- コストだけを見てstabilization windowを短くしないこと。 一度の障害コストが1週間分のインスタンスコストを超えることは珍しくありません。
- Graceful Shutdown設定を忘れないこと。 terminationGracePeriodSecondsとpreStopフックが適切でない場合、いくらゆっくりスケールダウンしてもリクエスト損失は発生します。
- スケールダウンポリシーはPodの絶対値よりもPercentベースが安全。 Podが少ない場合、割合ベースはより保守的に動作し、最小限の可用性を守ります。
- KEDA、Karpenterなども同じ哲学に従う。 特定のツールではなく、「自動スケーリングの原理」です。Cluster Autoscalerもスケールダウン時にデフォルトで10分の非使用時間を待ちます。
- PodDisruptionBudgetと併用すること。 HPAが停止させようとするPodとPDBが保護しようとするPodが衝突しないようにポリシーを一致させる必要があります。
✅ まとめ
| 軸 | スケールアップ | スケールダウン |
| 速度 | 速く (0秒) | ゆっくり (300秒以上) |
| 判断基準 | 敏感に | 保守的に |
| 失敗時の代償 | コスト | 障害 |
| 基本哲学 | まずは生き残る | 確実な時だけ減らす |
オートスケーラーの非対称設計は、単なる技術的選択ではなく、失敗の非対称性を反映したエンジニアリング哲学です。スケールアップの失敗は許容されますが、スケールダウンの失敗はサービス全体を崩壊させる可能性があるという苦い経験から生まれた設計なのです。
次のステップとしては、Cluster Autoscaler / KarpenterがHPAと連携する仕組み、そしてPodDisruptionBudgetでスケールダウン中も最小限の可用性を保証する手法を検討することをお勧めします。
「迅速な拡張と慎重な縮小」 — この一文がクラウド運用の安定性を守る見えない防波堤です。
コメントを残す