Kubernetesはある日突然現れたわけではない。
Googleが数十億個のコンテナを運用し、血と汗を流して築き上げた15年間の実戦ノウハウが溶け込んでいる。

🎯 この記事で扱うこと
- Google内部のクラスタ管理システム Borgの誕生背景と核心哲学
- Borgの限界を克服するために設計された Omegaの実験的試み
- オープンソースとして世に公開された Kubernetesがどのようにクラウド標準になったのか
- 3つのシステムの核心的な違いの比較
📌 導入 / 背景 — Googleはなぜこれを作ったのか?
今私たちが使っているGmail、YouTube、Google検索。これらのサービスが同時に数億人のリクエストを処理していることを考えたことがありますか?
2000年代初頭、Googleは途方もない問題に直面します。サービスが爆発的に増える中で、数千台のサーバーを手作業で一つ一つ管理することは物理的に不可能になったのです。誰かが誤ってサーバー設定を間違えれば障害が発生し、リソースは浪費され、エンジニアたちは夜通し障害対応に追われました。
この苦痛から誕生したのが、Borg → Omega → Kubernetesへと続くGoogleのクラスタ管理システム三部作です。
💡 クラスタ(Cluster)とは? 複数のサーバー(ノード)を一つのコンピューティングリソースプールとしてまとめたもの。個別のサーバーを管理するのではなく、クラスタ全体を一つの巨大なコンピュータのように扱う概念です。
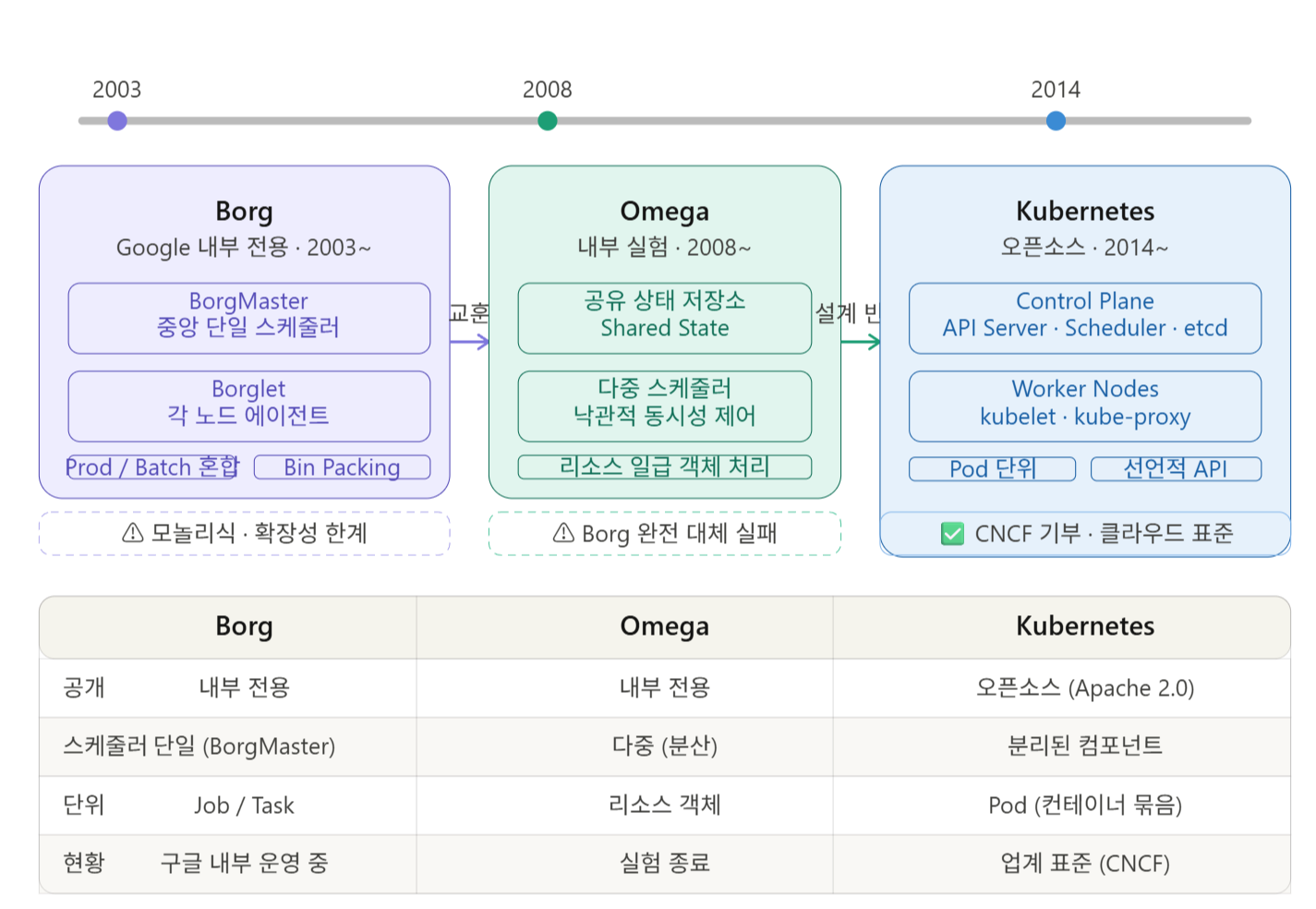
🔍 第1世代: Borg — “Googleの秘密兵器” (2003年~)
Borgとは何か?
BorgはGoogleが2003年から内部的に開発し、運用してきた大規模クラスタ管理システムです。なんと数十万個のジョブ(Job) を数千台のマシンに自動でデプロイし、管理しました。
名前の由来はスタートレックの異星種族「Borg」から来ています。個々の存在を集団(Collective)として吸収するBorgのように、数千台の個別サーバーを一つの巨大な集団として運用するという哲学が込められています。
Borgの核心概念Borgはジョブを二つのタイプに分類します:
- Prod (Production): 遅延に敏感なサービス。Gmail、検索のようなリアルタイムサービス。常に優先順位最上位。
- Non-Prod (Batch): 大容量データ処理のようなバッチジョブ。優先順位は低い。
この分類が核心でした。Borgは同じ物理サーバーにProdとNon-Prodジョブを一緒に配置(Bin Packing) することで、リソースの浪費を最小限に抑えました。Prodジョブが使わないCPUをBatchジョブが密かに使い、Prodが必要になればすぐに場所を空ける方式です。
Borgが解決したもの
| 問題 | Borgの解決策 |
| サーバー数千台の手動管理 | 中央スケジューラが自動配置 |
| サービス障害時の手動復旧 | 自動再起動、再配置 |
| リソースの浪費 | Prod/Batch混合配置で活用率を最大化 |
| デプロイ自動化の不在 | Job定義ファイルによる宣言的デプロイ |
### Borgのアーキテクチャ
BorgはBorgMaster(中央コントロールプレーン)とBorglet(各ノードのエージェント)で構成されます。
[BorgMaster] ─── 스케줄링 결정
│
├── [Borglet] ─ 서버 노드 1
├── [Borglet] ─ 서버 노드 2
└── [Borglet] ─ 서버 노드 NBorgMasterが「このジョブはあのサーバーで実行せよ」と指示すると、Borgletが実際に実行し、状態を報告します。
Borgの限界
しかし、Borgには構造的な問題がありました:
- モノリシックなBorgMaster: すべての決定をBorgMaster一つが下します。システムが大きくなるにつれてボトルネックが深刻化します。
- Job中心の設計: Borgの基本単位は「Job」で、その中に「Task」があります。ジョブ間の関係を表現するのが不自然でした。
- IPアドレスの共有: 同じサーバーのTaskがIPを共有するため、ポート衝突が頻繁に発生しました。
- レガシーの蓄積: 長期間内部でのみ使用されてきたため、下位互換性の問題で構造改善が困難でした。
🔍 第2世代: Omega — “白紙から再設計する” (2008年~)
Omega誕生の目的
Borgの限界を感じたGoogleのエンジニアたちは、2008年頃にOmegaという実験的なプロジェクトを開始します。「Borgを修正するのではなく、最初から正しく設計し直したらどうなるだろうか?」という問いから出発しました。
Omegaは実際にGoogle内部で運用されましたが、Borgを完全に置き換えることはできませんでした。BorgはGoogleのインフラにあまりにも深く根付いていたからです。
Omegaの革新: 共有状態(Shared State)アーキテクチャ
Borgの最大の問題は中央集権的なスケジューラでした。BorgMaster一つがすべての決定を下すため、拡張性に限界が生じたのです。
Omegaはこれを共有状態(Shared State)方式で解決しました:
기존 Borg:
[BorgMaster] → 모든 결정 → [Borglet들]
(병목 발생)
Omega:
[Scheduler A] ──┐
[Scheduler B] ──┼─→ [공유 상태 저장소] → [노드들]
[Scheduler C] ──┘
(낙관적 동시성 제어)複数のスケジューラが同時にクラスタの状態を監視し、独立してスケジューリングの決定を下します。衝突が発生した場合は、楽観的並行性制御(Optimistic Concurrency Control)で解決します。
💡 楽観的並行性制御: 「衝突は稀であると仮定して、まず作業を進め、後で衝突が確認されたら再試行する」方式。悲観的並行性制御(最初にロックをかけてから開始する)よりも処理量が高くなります。
###
Omegaが残した遺産
Omega自体はBorgを置き換えることはできませんでしたが、その核心的なアイデアは後のKubernetesに大きな影響を与えました:
- リソースを第一級オブジェクトとして扱う: CPU、メモリを具体的に明示し、追跡
- スケジューラの分離: 単一スケジューラへの依存からの脱却
- 宣言的APIの強化: 望ましい状態を宣言すればシステムがそれに合わせていく方式
🔍 第3世代: Kubernetes — “世界を変えたオープンソース” (2014年~)
なぜGoogleは公開したのか?
2013年にDockerが登場し、コンテナ技術が普及し始めました。Googleは気づきました。「私たちが10年以上かけて培ったノウハウをオープンソースとして公開すれば、クラウドエコシステムの標準を私たちが作れる。」
2014年6月、GoogleはKubernetes(クバネティス)をオープンソースとして公開します。ギリシャ語で「操舵手(船を操る人)」という意味です。ロゴが船の舵(Helm)であるのもこのためです。
Borgから学んだ教訓をKubernetesに反映する
Googleのエンジニアたちは2016年に発表した論文「Borg, Omega, Kubernetes」で、Borgの運用経験がKubernetesの設計にどのように反映されたかを詳細に明らかにしました:
🔴 Borgの失敗 → Kubernetesの解決策
| Borgの問題 | Kubernetesの解決 |
| Job/Task中心構造、関係表現の難しさ | Pod概念の導入。コンテナの束として単位を再定義 |
| TaskがIPを共有、ポート衝突 | Podごとに固有IPを付与 |
| モノリシックなBorgMaster | 分離されたコンポーネント (API Server, Scheduler, Controller Manager) |
| 内部専用設計 | オープンAPI中心、拡張可能なプラグイン構造 |
###
Kubernetesの核心アーキテクチャ
[Control Plane]
├── API Server ← 모든 요청의 관문
├── Scheduler ← Pod를 어느 노드에 배치할지 결정
├── Controller Mgr ← 현재 상태를 원하는 상태로 유지
└── etcd ← 클러스터 전체 상태 저장 (분산 KV 저장소)
[Worker Nodes]
├── kubelet ← Borglet과 동일한 역할, 컨테이너 실행·관리
├── kube-proxy ← 네트워크 규칙 관리
└── Container Runtime (Docker, containerd 등)###
宣言的API — Kubernetesの哲学Kubernetesの最も強力な哲学は宣言的(Declarative)管理です。
# 望ましい状態を宣言する
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-webserver
spec:
replicas: 3 # 常に3つ実行する
selector:
matchLabels:
app: webserver
template:
metadata:
labels:
app: webserver
spec:
containers:
- name: nginx
image: nginx:1.25
resources:
requests:
cpu: "250m" # 0.25 CPU要求
memory: "128Mi" # 128MBメモリ要求
limits:
cpu: "500m" # 最大0.5 CPU
memory: "256Mi" # 最大256MBこのYAMLを適用すると、Kubernetesは自動的に3つのnginx Podを実行し、一つが停止すれば自動的に復旧します。エンジニアは「どのように」ではなく、「何を」望むかだけを宣言すればよいのです。
Kubernetesが作ったエコシステム
Kubernetesが真に偉大な理由は、単に技術そのものではありません。エコシステムを創造したことです。
- 2015年: CNCF(Cloud Native Computing Foundation)設立。GoogleがKubernetesを寄付。
- 2016年: Helm(パッケージマネージャー)、各クラウドベンダーのマネージドサービス(GKE, AKS, EKS)が登場
- 2017年: Docker Swarm、Mesosなど競合がKubernetesを事実上の標準として認める
- 2018年以降: Service Mesh(Istio)、GitOps(ArgoCD)、サーバーレス(Knative)など数百のツールがKubernetes上で動作
⚠️ 注意事項 / よくある間違い
1. KubernetesはBorgのオープンソース版ではありません 🚫 KubernetesはBorgの教訓を基に、最初から再設計されたシステムです。Borgのコードをそのままオープンソース化したものではありません。
2. OmegaもBorgを置き換えることはできませんでした 🚫 Google内部ではBorgとOmega、Kubernetesが同時に運用されています。Borgは今もGoogleの核心インフラを支えています。
3. Kubernetes = コンテナオーケストレーション以上 ✅ 多くの人が「Dockerを複数管理するツール」とだけ理解していますが、Kubernetesはクラウドネイティブインフラ全体を宣言的に管理するプラットフォームです。ネットワーク、ストレージ、セキュリティポリシー、サービスディスカバリまでを網羅します。
✅ まとめ / 締めくくり
| システム | 時期 | 公開状況 | 核心的革新 | 限界 |
| Borg | 2003~ | 内部専用 | 大規模自動化、Prod/Batch混合 | モノリシック、拡張性限界 |
| Omega | 2008~ | 内部専用 | 共有状態、多重スケジューラ | Borg代替失敗 |
| Kubernetes | 2014~ | オープンソース | 宣言的API、プラグインエコシステム | 学習曲線が高い |
Googleの15年間の道のりは、単なる技術進化ではありません。数十億個のコンテナを運用しながら学んだ苦痛な教訓が、Kubernetesという形で世に公開されたものです。
今、皆さんがkubectl apply -f deployment.yamlの一行を実行する時、その裏にはGoogleのエンジニアたちが20年かけて積み上げてきた知恵が働いています。🚀
次のステップとしては、Kubernetesのスケジューリングメカニズム、etcdのRaft合意アルゴリズム、そしてService Mesh(Istio)を学ぶことで、このエコシステムの深さをよりよく理解できるでしょう。
コメントを残す