iptables无法承载改变世界的规模。eBPF改变了内核本身。
>

🎯 本文涵盖内容
- Kubernetes CNI的历史:从Flannel → Calico → Cilium的世代更迭
- iptables的根本局限性以及eBPF如何克服这些局限
- Google、AWS、Azure、阿里巴巴选择Cilium的真实原因
- Cilium如何从一个简单的CNI演变为“网络平台”
- 截至2026年,Cilium成为事实标准的决定性证据
📌 引言 — “CNI到底有多重要?”
初学Kubernetes时,CNI(Container Network Interface)感觉“只是一个需要安装的东西”。
一行 kubectl apply -f flannel.yml 就能让Pod之间进行通信。
然而,当集群规模扩大到数百个节点、数千个服务时,现实就不同了。网络延迟莫名增加,策略变更缓慢,并且无法进行调试。此时,运维团队会得出一个共同的结论。
我们选错了CNI。
这就是无数企业从Flannel迁移到Calico,再到Cilium的原因。而现在,根据2025年CNCF Kubernetes网络状况报告,Cilium已成为事实标准,占据了CNI部署的60%以上。它是如何走到这一步的?
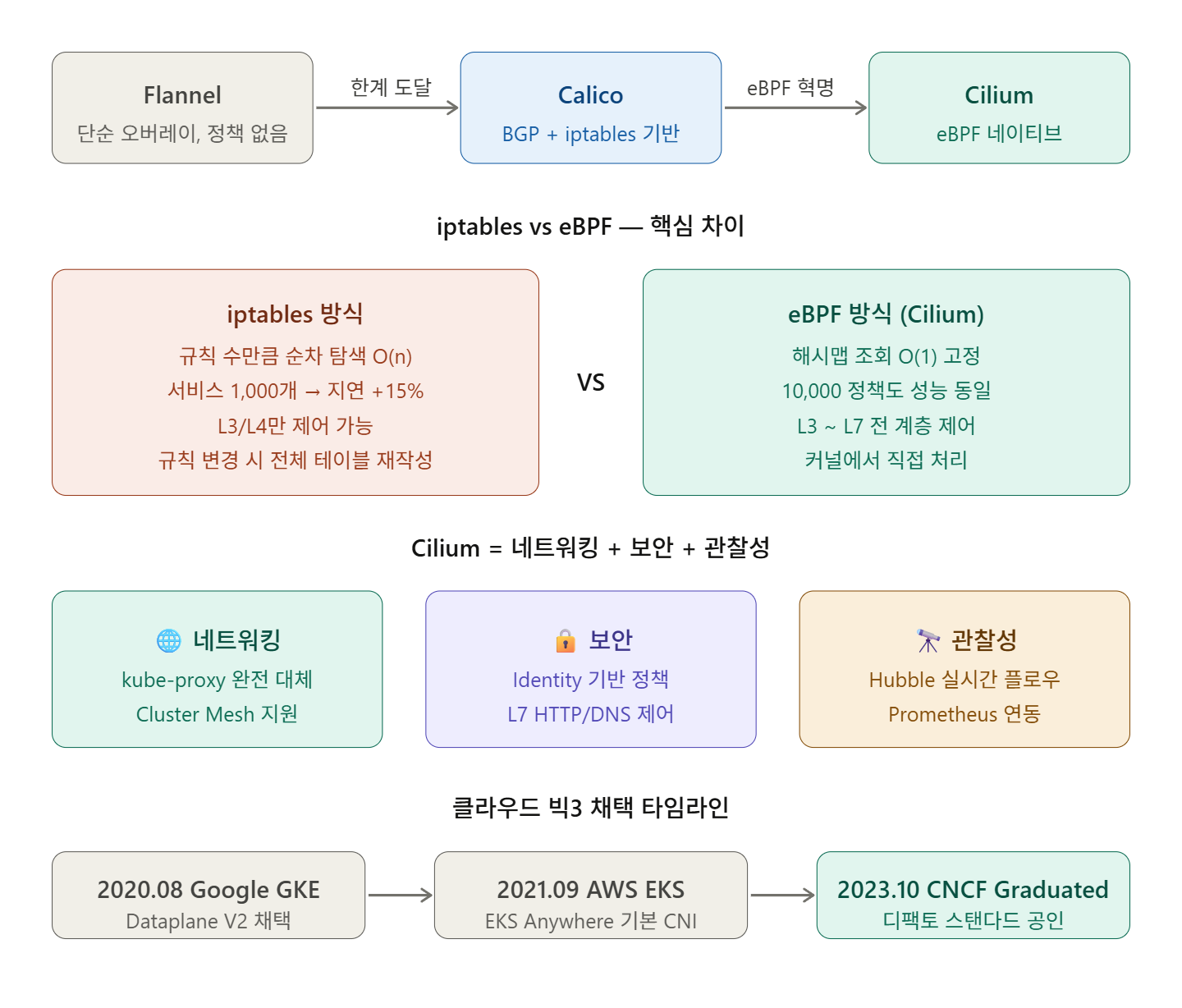
🔍 第一代CNI时代 — Flannel与Calico
Flannel:“先能连上就行”
在构建早期Kubernetes平台时,Flannel是一个自然的选择。它最成熟,依赖性少,安装简单,并且在基准测试中表现出高性能。
Flannel的理念很简单:通过VXLAN覆盖网络创建一个扁平网络,让所有Pod都能相互通信。仅此而已。
- 网络策略?没有。
- 可观测性?没有。
- 安全性?自行处理。
对于小型集群来说,这已经足够了。但随着流量的增加,iptables和netfilter的局限性开始显现。
Calico:“让我们认真对待BGP”
Calico使用BGP(与驱动互联网骨干网相同的协议)进行路由,并从2016年开始成为企业级的默认选择。
Calico也支持网络策略。安全团队可以实现所需的L3/L4级别的流量控制。但存在一个问题。
iptables是线性(linear)操作的。
在iptables方式中,随着策略的增加,规则是顺序评估的,因此在1000个策略的环境中,可能会产生10-15%的延迟开销。
当服务数量超过数百个时,iptables规则表会膨胀到数万行。更改规则时需要重写整个表,这个过程会导致短暂的流量中断。在大型集群中,这是一场灾难。
🔍 Cilium的出现 — eBPF的赌注
2015~2016:“让我们改变内核”
Cilium于2015年12月由后来创立Isovalent的开发者们创建,并于2016年在LinuxCon上首次作为利用eBPF和XDP的快速IPv6容器网络项目公开。
当时,这是一个赌注。大多数CNI都在iptables之上运行是常识,但Cilium从一开始就全力投入eBPF。Cilium押注eBPF将成为云原生网络的未来,并从头开始构建了基于eBPF的数据平面。
什么是eBPF?
eBPF(extended Berkeley Packet Filter)可以简单解释如下。
以前,要改变内核功能,需要修改内核源代码并重新编译,这是一个耗时数月的工作。eBPF是一种无需修改内核,即可安全地将代码注入内核的技术。你可以在网络数据包通过内核的精确位置执行你想要的逻辑。
eBPF在内核内部运行,因此可以避免用户空间和内核空间之间昂贵的上下文切换,从而显著提高延迟、吞吐量和性能效率。
2018~2020:全面验证
2018年4月,Cilium 1.0作为第一个稳定版本发布;2019年11月,提供基于eBPF的网络可观测性的Hubble发布。
随后,一个决定性事件发生了。
2020年8月,Google选择Cilium作为GKE的新数据平面。
Google Cloud采用Cilium创建了GKE Dataplane V2,利用eBPF绕过传统的内核网络路径(例如kube-proxy基于iptables的服务路由),从而实现了高效的数据包处理。
Google的选择对整个行业发出了强烈的信号。
🔍 为何三大云巨头都选择了Cilium
Google GKE
2024年,GKE宣布支持高达65,000个节点的集群,这一巨大的可扩展性在很大程度上得益于GKE Dataplane V2的健壮和优化架构。GKE Dataplane V2基于Cilium。
AWS EKS Anywhere
2021年9月,AWS选择Cilium作为EKS Anywhere的网络和安全解决方案。
Alibaba Cloud ACK
阿里巴巴认识到,在现有的基于veth的容器网络模型中,命名空间之间的D数据包切换会产生显著的开销,并且在默认的基于iptables的服务模式下,规则增加会导致高昂的成本问题。Cilium帮助解决了这两个核心问题。
全球三大云服务提供商都得出了相同的结论:iptables已达到极限,eBPF是唯一的答案。
🔍 Cilium超越单纯CNI的原因
不应将Cilium仅仅视为一个“快速的CNI”。Cilium将三个领域整合为一体。
1️⃣ 网络 — 完全替代kube-proxy
Cilium利用eBPF高效的哈希表完全替代kube-proxy,并在套接字级别重写服务连接,从而消除了每个数据包的NAT开销。
没有kube-proxy?iptables规则爆炸的问题消失了。一个拥有10,000个网络策略的集群与一个拥有10个策略的集群性能相同。这是因为它是O(1)哈希映射查找。
2️⃣ 安全 — 基于身份而非IP
传统的CNI基于IP地址应用策略。问题是Pod的IP地址会频繁变化。Cilium以Kubernetes标签作为身份来应用策略。
更进一步,Cilium支持L7策略。
# 控制HTTP方法和路径的L7策略示例
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: api-http-policy
namespace: production
spec:
endpointSelector:
matchLabels:
app: backend-api
ingress:
- fromEndpoints:
- matchLabels:
app: frontend
toPorts:
- ports:
- port: "8080"
protocol: TCP
rules:
http:
- method: GET
path: "/api/.*" # 仅允许 GET /api/*
- method: POST
path: "/api/data" # 仅允许 POST /api/data
# 阻止所有其他请求这是传统iptables无法实现的L7级别控制。无需服务网格即可实现。
3️⃣ 可观测性 — Hubble
如果你经历过网络问题调试的炼狱,你就会知道Hubble有多么强大。
Hubble观察单个网络数据包流,验证流量允许/拒绝的网络策略决策,并通过服务图显示Kubernetes服务如何通信。这些数据可以导出到Prometheus、OpenTelemetry和Grafana。
与过去使用iptables追踪流量为何被阻止的时代相比,世界已经改变了。
💻 Cilium安装与基本验证
# 安装Cilium CLI
curl -L --remote-name-all
https://github.com/cilium/cilium-cli/releases/latest/download/cilium-linux-amd64.tar.gz
tar xzvf cilium-linux-amd64.tar.gz
sudo mv cilium /usr/local/bin/
# 在集群上安装Cilium(包括替换kube-proxy)
cilium install
--set kubeProxyReplacement=true
--set hubble.relay.enabled=true
--set hubble.ui.enabled=true
# 检查安装状态
cilium status
# 检查kube-proxy是否被替换
kubectl exec -n kube-system ds/cilium -- cilium status | grep KubeProxyReplacement
# KubeProxyReplacement: True
# 使用Hubble观察实时流量
hubble observe --follow --namespace production⚠️ 注意事项 / 常见错误
必须检查内核版本
Cilium安装要求Linux内核版本5.10或更高(或RHEL 8.10基准为4.18或更高),并且eBPF支持必须在内核配置中启用。在旧版操作系统上部署Cilium,其功能将悄无声息地被禁用。
内存开销规划
Cilium代理根据端点和策略的数量,每个节点会消耗150-250MB的内存。对于一个100节点的集群,应至少预留15-25GB的额外内存。然而,有运营案例表明,Cilium的吞吐量提升可以使总节点数减少10-15%。
小型集群的性价比
在200个节点以下、500个服务以下的集群中,两种CNI都能运行良好,性能差异并非决定性因素。如果是学习环境,从Flannel开始也无妨。
✅ 总结 — Cilium为何成为标准
Cilium的崛起不仅仅是因为出现了“更快的CNI”。这是一场根本性的架构转变。
| 类别 | 传统方法 (iptables) | Cilium (eBPF) |
| 性能特点 | 随规则数量线性下降 | 与规则数量无关的O(1) |
| 策略层 | L3/L4 | L3 ~ L7 |
| kube-proxy | 需要独立组件 | eBPF完全替代 |
| 可观测性 | tcpdump、日志文件 | Hubble (实时流) |
| 服务网格 | 需要Sidecar | 无需Sidecar即可实现 |
Cilium于2023年10月从CNCF毕业项目毕业,其社区拥有超过21,000个GitHub星标和900多名贡献者,增长速度超过任何其他CNI。
eBPF原生特性并非后来添加的功能,而是其架构的根本,其性能和可观测性特点源于设计本身,而非附加组件。
下一步,建议通过Hubble UI探索服务图,使用CiliumNetworkPolicy实践L7策略,并利用Tetragon探索运行时安全。
发表回复