“扩容0秒,缩容5分钟。”
我们将深入探讨Kubernetes HPA为何在缩容操作中故意设置延迟。
本文涵盖内容
- HPA为何将扩容(Scale Up)和缩容(Scale Down)设计为非对称
- 不设置延迟时间(Stabilization Window)会导致的实际问题 — 抖动、冷启动、残留请求
- 如何使用K8s HPA v2的behavior字段进行实际调优
- AWS Auto Scaling Group、GCP MIG等其他云服务也遵循相同理念的原因
引言 — “流量减少了,但Pod却没有减少?”
这可能是任何首次运营HPA的人都曾经历过的场景。
当流量瞬间飙升时,HPA会像闪电般增加Pod。不到10秒,新的Pod就会启动。然而,当流量平息后,Pod却长时间不减少。”CPU使用率已经下降了,为什么这家伙还不动?” 这样的疑问自然而然地浮现出来。
直接说结论,这不是一个bug。 Kubernetes的设计者们有意地给缩容速度踩了刹车。相反,这种“缓慢缩减”是保护服务免受众多故障影响的防线。
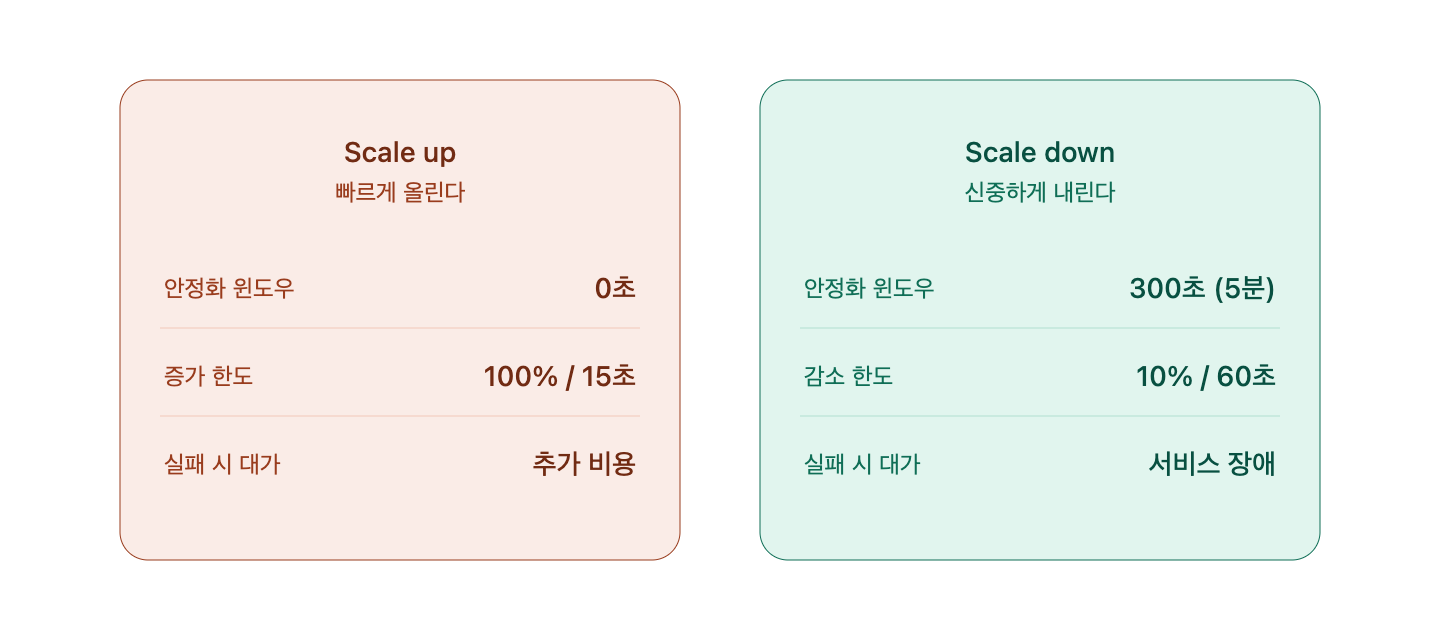
核心概念 — 非对称扩缩容 (Asymmetric Scaling)
自动扩缩容基本遵循“扩容要快,缩容要慢”的非对称原则。这并非Kubernetes独有。AWS Auto Scaling Group的冷却时间(cooldown)、GCP MIG的稳定期(stabilization period)、Azure VMSS的冷却时间都基于相同的理念。
扩容判断与缩容判断的权重
两种判断失败的成本截然不同。
- 扩容判断错误时: 多启动了几个Pod → 少量成本浪费
- 缩容判断错误时: 减少Pod后流量立即涌入 → 服务故障、客户流失、SLA违规
前者是钱包受损,后者是业务崩溃。这种非对称的风险正是非对称扩缩容的依据。
Kubernetes的默认设置
- –horizontal-pod-autoscaler-downscale-stabilization: 默认值 5分钟 (300秒)
- Scale Up stabilization window: 默认值 0秒 (立即)
足足300倍的差距。这个数字并非随意设定,而是从无数故障案例中积累的经验值。
为何设置延迟 — 5个结构性原因
1️⃣ 防止抖动 (Flapping)
流量像波浪一样波动。服务每隔30秒就出现请求高峰和低谷的情况很常见。如果缩容是即时的,就会发生以下情况:
- 流量减少 → 缩减2个Pod
- 30秒后流量再次增加 → 扩增3个Pod
- 再次减少 → 缩减…
这种无限循环被称为抖动(Flapping)或颠簸(Thrashing)。它不仅浪费集群资源,还会因为Pod的不断创建/删除而同时引发后续的“残留请求”问题。
2️⃣ 处理残留请求 (Graceful Shutdown)
下线Pod与删除文件不同。该Pod此刻仍在处理请求。
- 完成正在进行的HTTP请求响应
- 等待DB事务提交
- 接收外部API调用结果
- 从服务端点中移除该Pod的传播延迟
Kubernetes通过terminationGracePeriodSeconds(默认30秒)来保证这段时间。但是,如果HPA每5秒就决定缩容,Pod将始终在Terminating状态中结束生命。用户将看到5xx错误。
3️⃣ 冷启动 (Cold Start) 成本
你可能会想“启动一个Pod能花多少时间?”,但现实中却相当长。
- 镜像拉取(Pull):数秒至数十秒(取决于镜像大小)
- 容器启动:1-5秒
- 应用程序初始化:基于JVM的应用常见10秒以上
- Readiness Probe通过:额外数秒
- 总计:短则15秒,长则1分钟以上
要重新启动一个已下线的Pod,就必须支付这整个时间。在此期间,剩余的Pod能否承受住流量?冷启动期间,响应延迟很容易飙升或发生超时。
4️⃣ 保持预热状态
这是一个经常被忽视的重点。一个活着的Pod不仅仅是“内存中有一个进程”。
- JVM JIT编译:频繁调用的方法已被编译成本地代码
- DB连接池:已建立的TCP连接得到保障
- OS页面缓存:频繁读取的文件已加载到内存中
- 应用程序内部缓存:会话信息、查询结果等
下线Pod会丢失所有这些预热资产。新启动的Pod将在一段时间内以较慢的状态接收请求,这直接导致p99延迟飙升。
5️⃣ 过滤指标噪声
CPU使用率或请求数量很容易瞬间飙升。一次垃圾回收、一次批处理作业就能让数字大幅波动。
如果仅凭5秒的指标下降就立即缩容,实际上是在响应噪声。设置5分钟的观察窗口可以平均化这种瞬时波动,从而判断真实的流量下降趋势。
实际配置 — HPA v2 behavior 调优
从Kubernetes HPA v2开始,可以使用behavior字段精细调整这种非对称性。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 2
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
behavior:
scaleUp:
stabilizationWindowSeconds: 0 # 立即扩容
policies:
- type: Percent
value: 100 # 一次最多允许增加100%
periodSeconds: 15
scaleDown:
stabilizationWindowSeconds: 300 # 观察5分钟后缩容
policies:
- type: Percent
value: 10 # 一次最多减少10%
periodSeconds: 60我们来解读一下核心要点。
- scaleUp.stabilizationWindowSeconds: 0 — 扩容时不犹豫
- scaleDown.stabilizationWindowSeconds: 300 — 缩容时观察5分钟
- scaleDown.policies.value: 10 — 一次绝不超过10%的缩减
对于流量波动大的实时服务(如流媒体、游戏、广告竞价等),将stabilizationWindowSeconds增加到10分钟以上是常见的实际选择。
⚠️ 注意事项 / 常见错误
- 不要仅仅为了成本而缩短稳定窗口(stabilization window)。 一次故障的成本往往超过一周的实例费用。
- 不要忘记优雅停机(Graceful Shutdown)设置。 如果terminationGracePeriodSeconds和preStop钩子不合适,无论缩容多慢,请求丢失都会发生。
- 缩容策略基于百分比比基于Pod绝对值更安全。 当Pod数量较少时,基于百分比的策略会更保守地运行,从而保护最小可用性。
- KEDA、Karpenter等也遵循相同理念。 这不是特定工具的特性,而是“自动扩缩容的原理”。Cluster Autoscaler在缩容时也会等待默认10分钟的非使用时间。
- 与PodDisruptionBudget一起使用。 HPA打算缩减的Pod与PDB打算保护的Pod之间,策略必须保持一致,以避免冲突。
✅ 总结
| 轴 | 扩容 (Scale Up) | 缩容 (Scale Down) |
| 速度 | 快速 (0秒) | 缓慢 (300秒+) |
| 判断标准 | 敏感 | 保守 |
| 失败代价 | 成本 | 故障 |
| 基本理念 | 先活下来再说 | 只有确定时才缩减 |
自动扩缩器的非对称设计不仅仅是技术选择,更是反映了失败的非对称性的工程哲学。扩容的错误可以被原谅,但缩容的错误可能会导致整个服务崩溃,这是从惨痛经验中得出的设计。
下一步,建议您了解Cluster Autoscaler / Karpenter与HPA协同工作的方式,以及如何通过PodDisruptionBudget在缩容期间保证最小可用性的技术。
“快速扩展和谨慎收缩” — 这一句话是守护云运营稳定性的无形防波堤。
发表回复