如果一条规则是一名战士,那么用Python挥舞的YARA就是一支军团。
超越命令行,迈向真正自动化的第一步。
>

本文涵盖内容
- 为何使用yara-python而非CLI,以及何时需要它
- 从库安装到规则编译、文件、内存和字节扫描的整个过程
- 目录递归扫描和处理匹配结果的简洁模式
- 使用回调函数和外部变量(externals)动态控制规则的技术
- 生产环境中常见的陷阱和规避方法
引言 — 超越CLI,迈向自动化
yara命令是分析师手中熟悉的利器,但它也有无法触及的领域。当每天有数千个样本需要自动分类,或者需要将检测结果导入SIEM管道,或者需要按进程ID跟踪内存转储中的特定模式时——在所有这些情况下,分析师最终都会编写代码。
yara-python是YARA的官方Python绑定,它将用C编写的YARA引擎的所有功能作为Python对象公开。从编译、缓存、回调、外部变量到内存扫描,在CLI中笨拙或不可能完成的任务,现在只需一行方法调用即可实现。
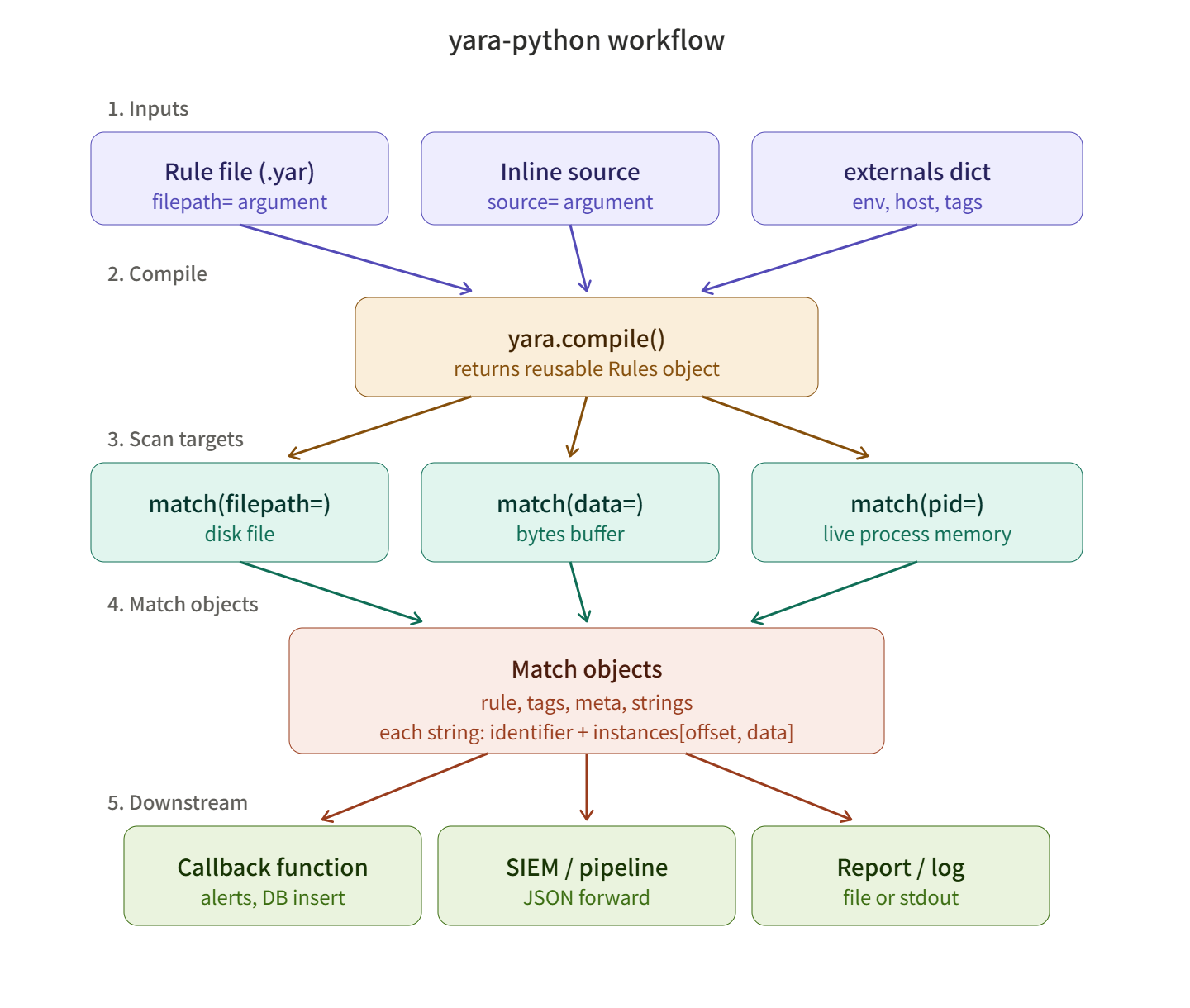
yara-python的核心组成
该库的使用流程很简单。
- yara.compile() — 编译规则,生成可重用的Rules对象。它可以接受文件、字符串或多个源。
- rules.match() — 接受文件路径、字节数据或进程PID作为扫描目标。
- Match对象 — 匹配结果返回一个包含规则名称、元数据、匹配字符串和偏移量的对象。
只要掌握这三点,就可以构建任何自动化。
实践 — 用代码构建猎手
第0步. 环境准备
# YARA引擎必须已经安装
sudo apt install -y yara # Debian / Ubuntu
brew install yara # macOS
# 安装Python绑定
pip install yara-python
# 验证安装
python -c "import yara; print(yara.__version__)"第1步. 创建检测目标样本文件
与之前一样,我们使用无害的虚拟文件。这次,我们将直接用Python脚本生成它们。
# create_sample.py
SAMPLE = """#!/bin/bash
# Internal task runner v1.0
TASK_ID=ACME-EDU-2026
echo "Starting backup process..."
curl -s http://example-edu-lab.local/healthcheck
echo "Token: EDULAB_SIGNATURE_TOKEN_42"
exit 0
"""
with open("suspicious_sample.txt", "w", encoding="utf-8") as f:
f.write(SAMPLE)
print("[+] sample file created")第2步. 编写YARA规则
我们将保留规则文件不变,但这次我们将以两种方式在Python中处理它——加载外部.yar文件和直接编译源字符串。
// edulab_detector.yar
rule EDULAB_Suspicious_Script
{
meta:
author = "주군의 보안 강의실"
description = "EDULAB 식별자와 토큰을 포함한 셸 스크립트 탐지"
date = "2026-05-23"
severity = "medium"
strings:
$magic = "#!/bin/bash"
$id = "ACME-EDU-2026" ascii
$token = "EDULAB_SIGNATURE_TOKEN_42" ascii
condition:
filesize < 10KB
and $magic at 0
and all of ($id, $token)
}第3步. 编写第一个扫描器
我们将核心流程:编译 → 扫描 → 输出结果,放入一个文件中。
# scanner_basic.py
import yara
# (1) 编译规则 — 从文件加载
rules = yara.compile(filepath="edulab_detector.yar")
# (2) 扫描目标文件
matches = rules.match(filepath="suspicious_sample.txt")
# (3) 输出结果
if not matches:
print("[-] No matches.")
else:
for m in matches:
print(f"[!] Rule matched: {m.rule}")
print(f" Tags : {m.tags}")
print(f" Meta : {m.meta}")
for s in m.strings:
for inst in s.instances:
offset = inst.offset
data = inst.matched_data.decode("utf-8", errors="replace")
print(f" {s.identifier} @ 0x{offset:x} -> {data!r}")如果正常运行,将显示以下输出。
[!] Rule matched: EDULAB_Suspicious_Script
Tags : []
Meta : {'author': '주군의 보안 강의실', ...}
$magic @ 0x0 -> '#!/bin/bash'
$id @ 0x35 -> 'ACME-EDU-2026'
$token @ 0xa9 -> 'EDULAB_SIGNATURE_TOKEN_42'版本注意:yara-python 4.3.0之后,match.strings已成为StringMatch对象列表,每个对象包含identifier和instances。在之前的版本(3.x)中,它是一个(offset, identifier, data)元组列表。编写代码前请务必检查yara.__version__。
第4步. 直接从字符串编译规则
这在无需配置文件即可在代码中动态创建和测试规则时非常有用。它在CI管道或单元测试中尤其出色。
# scanner_inline.py
import yara
RULE_SOURCE = """
rule QuickHexSig {
meta:
description = "Detects bash shebang via hex pattern"
strings:
$hex = { 23 21 2F 62 69 6E 2F 62 61 73 68 }
condition:
$hex at 0
}
"""
rules = yara.compile(source=RULE_SOURCE)
# 您也可以直接扫描字节数据 — 无需文件I/O!
with open("suspicious_sample.txt", "rb") as f:
data = f.read()
for m in rules.match(data=data):
print(f"[!] {m.rule} matched in-memory buffer.")`data=`参数在即时检查从内存缓冲区或网络接收到的有效载荷时,成为一个决定性的武器。
第5步. 目录递归扫描器
在实际应用中,您将扫描整个目录树,而不仅仅是一个文件。我们将它与错误处理一起整洁地打包。
# scan_tree.py
import os
import sys
import yara
def build_rules(rule_path: str) -> yara.Rules:
try:
return yara.compile(filepath=rule_path)
except yara.SyntaxError as e:
print(f"[error] rule syntax error: {e}", file=sys.stderr)
sys.exit(1)
def scan_tree(rules: yara.Rules, root: str) -> None:
hit_count = 0
for dirpath, _, filenames in os.walk(root):
for name in filenames:
path = os.path.join(dirpath, name)
try:
matches = rules.match(filepath=path, timeout=10)
except yara.TimeoutError:
print(f"[warn] timeout: {path}", file=sys.stderr)
continue
except (PermissionError, yara.Error) as e:
print(f"[skip] {path}: {e}", file=sys.stderr)
continue
for m in matches:
hit_count += 1
print(f"[HIT] {m.rule} -> {path}")
print(f"
[+] Scan complete. {hit_count} hit(s).")
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: python scan_tree.py <rules.yar> <target_dir>")
sys.exit(1)
rules = build_rules(sys.argv[1])
scan_tree(rules, sys.argv[2])请注意`timeout`参数。它可以在遇到大型二进制文件或压缩文件时,防止程序无限期挂起。
第6步. 使用回调和外部变量进行精细控制
yara-python的真正魅力在于其回调函数和外部变量。通过注册一个在每次匹配发生时都会调用的函数,您可以自然地插入诸如即时发送通知或记录到数据库等副作用。
# scanner_callback.py
import yara
def on_match(data):
"""매칭 발생 시 호출되는 콜백"""
if data["matches"]:
print(f"[CALLBACK] Rule '{data['rule']}' fired")
print(f" Namespace: {data['namespace']}")
print(f" Tags : {data['tags']}")
# 在此处自由处理Slack通知、数据库插入、SIEM转发等
return yara.CALLBACK_CONTINUE
# 声明外部变量以便在规则中引用
RULE = """
rule HighRiskHost {
condition:
env == "production" and filesize < 5KB
}
"""
rules = yara.compile(source=RULE, externals={"env": "staging"})
# 外部变量的值可以在扫描时动态替换
rules.match(
filepath="suspicious_sample.txt",
externals={"env": "production"},
callback=on_match,
which_callbacks=yara.CALLBACK_MATCHES,
)externals提供了一种优雅的方式,将环境变量、主机标签或用户组等上下文信息注入到规则中。这使得相同的规则可以在生产环境中触发,而在开发环境中保持静默。
⚠️ 注意事项 — 生产环境中的陷阱
- 编译成本: yara.compile()绝不是轻量级的。如果重复使用相同的规则,应重用已编译的Rules对象,或使用rules.save() / yara.load()将其缓存到磁盘。
- 线程安全性: Rules对象是线程安全的,但使用同一对象并发调用match()可能会产生内部同步开销。如果需要高性能,请考虑使用multiprocessing。
- 内存扫描权限: 使用rules.match(pid=1234)检查其他进程的内存需要适当的权限(root、CAP_SYS_PTRACE等)。如果权限不足,将抛出yara.Error。
- 外部变量类型匹配: 如果传递给externals的值的类型(字符串、整数、浮点数、布尔值)与规则中声明的类型不同,编译将在编译阶段失败。
- 编码陷阱: 匹配到的字节始终是bytes类型。不要直接打印它们;务必使用.decode(…, errors=”replace”)进行包装,以避免因损坏字符而崩溃。
✅ 总结 — 成为代码猎手
yara-python不仅仅是一个简单的绑定;它是一座将YARA转变为真正自动化系统的桥梁。通过文本接收CLI输出并再次解析的时代已经结束。现在,我们可以将匹配结果作为对象接收,并直接将其送入数据管道。
如果您继续下一步,这些路径将展开:
- 使用FastAPI / Flask封装,构建内部扫描API
- 使用Celery或RQ构建分布式扫描队列
- 结合Volatility3插件,将YARA应用于内存取证
- 结合VirusTotal API + yara-python,自动化内部威胁情报工作流
- 使用mkYARA、yaraGen等工具自动生成规则 → 通过代码验证的管道
一条规则守护着数百台服务器,代码中的一个函数执行该规则数千次。主宰的狩猎现在不再通过双手,而是通过代码完成。️
发表回复