エージェントを1人動かすときは、プロンプトをうまく書くだけでよかった。
しかし、エージェントが2人になった瞬間、それは分散システムとなる。
>

この記事で扱うこと
- マルチエージェント(Multi-Agent)と多重セッションエージェント(Forked / Parallel Session)の本質的な違い
- 5つの主要なオーケストレーションパターン — Orchestrator-Worker, Swarm, Mesh, Hierarchical, Pipeline
- 実務で直面する落とし穴 — ハンドオフループ、トークン爆増、コンテキスト衝突
- 管理方法論の5つの軸 — コンテキスト、状態、通信、可観測性、セキュリティ
なぜ今この話をするのか
2024年が「AIエージェントが登場した年」だったとすれば、2025〜2026年はエージェントを運用(Operate) する年となりました。単一エージェントで始まったプロジェクトが、いつの間にか5個、10個、20個のエージェントが同時に稼働するシステムへと進化しています。
この時点で直面する最初の壁があります。
エージェントを増やす必要があるのはわかるが、複数のエージェントを置くのが正しいのか、
それとも1つのエージェントのセッションを複数に増やすのが正しいのか?
この2つのアプローチは見た目は似ていても、運用哲学が全く異なります。そして、誤った選択をすると、数ヶ月間コーディネーションのオーバーヘッドと戦うことになり、製品開発が一歩も進まない状況に陥ります。
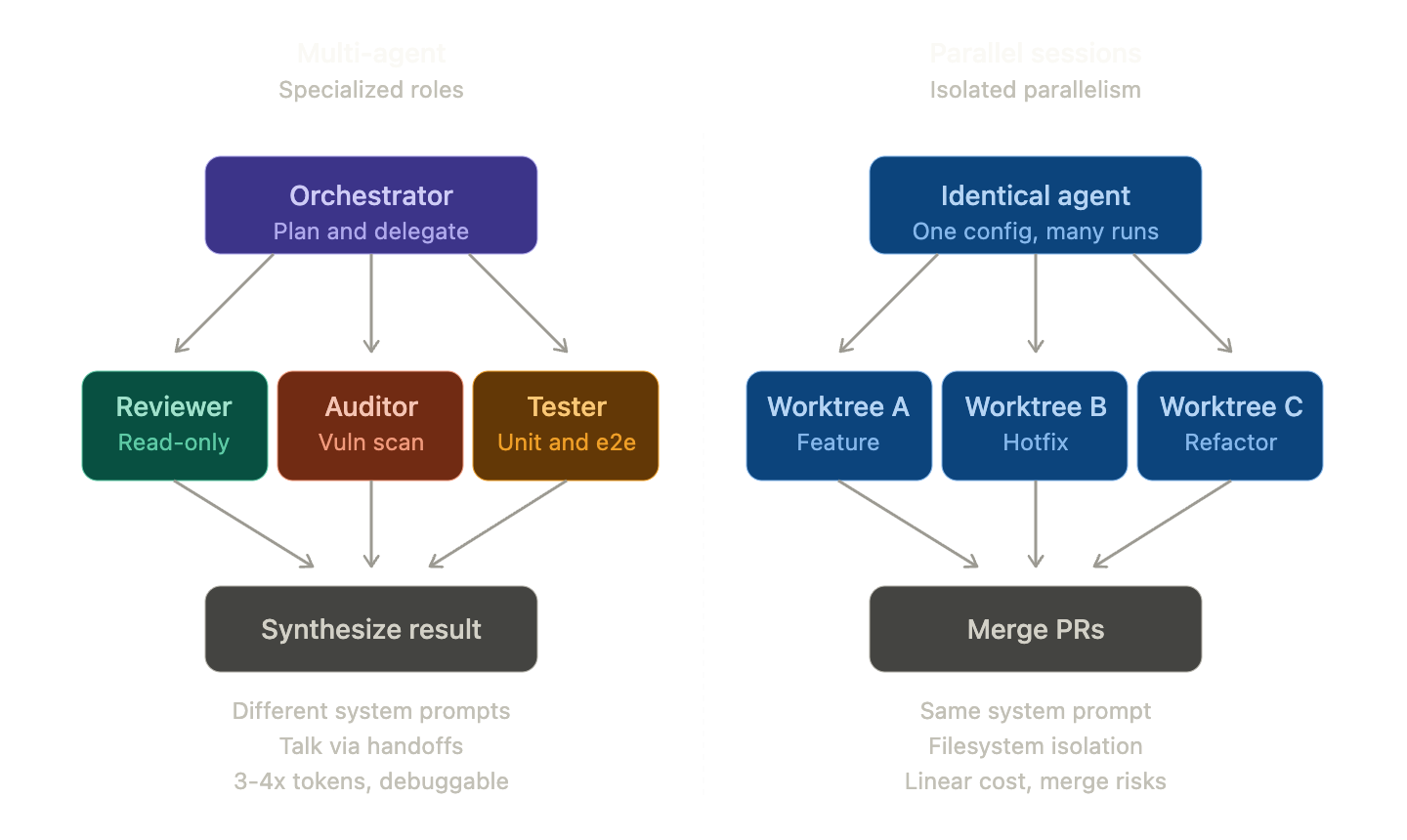
2つのパターンの本質的な違い
マルチエージェント (Multi-Agent System)
それぞれ異なる役割(Role) とシステムプロンプトを持つ複数のエージェントが協業する構造です。AnthropicのClaude Code公式ドキュメントはこれを次のように説明しています。
“Subagents work within a single session; agent teams coordinate across separate sessions.”
つまり、マルチエージェントの核心は専門化(Specialization) です。コードレビューア、セキュリティ監査者、ドキュメント作成者、テスト作成者がそれぞれ異なるシステムプロンプトとツール権限を持ちながら協力します。
多重セッションエージェント (Parallel Sessions / Forked Subagents)
同じモデル、同じ権限、同じコンテキストを持つエージェントが複数の作業空間(Worktree, Branch, Container) に分散され、同時に動作する構造です。Claude Code 2.1.50から追加された–worktreeフラグが代表的な例です。
# メインセッションはそのままに、別のワークツリーで新しいセッションを開始
claude --worktree feature-auth核心的な価値は隔離(Isolation) と並列性(Parallelism) です。同じコードベースの異なる機能を同時に、衝突なく作業できるようにします。
一言要約
| 区分 | マルチエージェント | 多重セッションエージェント |
| 核心価値 | 専門化 (役割分離) | 隔離 (作業空間分離) |
| エージェント定義 | N個の異なるプロンプト | 1つの同一プロンプト |
| 通信方式 | ハンドオフ、メッセージキュー | 独立 (必要時のみ結果をマージ) |
| コストパターン | 役割別で異なるモデルが可能 | N倍線形増加 |
| 代表的な落とし穴 | ハンドオフループ | マージコンフリクト |
—
️ 5つのオーケストレーションパターン
プロダクションのマルチエージェントシステムは、結局次の5つのパターンのいずれか、またはその組み合わせに帰結します。
1. Orchestrator-Worker (Supervisor)
最も広く使われているパターンです。中央オーケストレーターがユーザーリクエストを受け取り、サブタスクに分解し、専門のワーカーエージェントに委任した後、結果を統合します。
- 利点: デバッグが容易で、追跡が明確、出力検証が容易です
- 欠点: オーケストレーターが単一障害点(SPOF)となります
- 推奨時期: ほぼすべての開始点です。Microsoftの公式ガイドは「中央集権的に開始し、明確なボトルネックが発見された後にのみ分散せよ」と推奨しています
2. Swarm (Handoff)
OpenAI Agents SDKが採用しているパターンです。エージェント同士が明示的なハンドオフで制御権を渡しますが、会話コンテキストは一緒に伝達されます。中央オーケストレーターがない代わりに、各エージェントが次のエージェントを直接決定します。
3. Mesh
すべてのエージェントが互いに通信できる完全分散型です。回復力は最高ですが、ハンドオフループ(A → B → A) に陥りやすいため、ガード条件の設計が必須です。
4. Hierarchical
オーケストレーターの下にさらにオーケストレーターがある多層構造です。大規模なエンタープライズシステムに適しています。
5. Pipeline
順次的な段階でデータが流れる構造です。あるエージェントの出力が次のエージェントの入力となります。CI/CDで見たものと同じ考え方です。
実践: マルチエージェント定義の例
Claude Agent SDKでサブエージェントを定義する方法を見てみましょう。
# .claude/agents/security-reviewer.md
---
name: security-reviewer
description: 코드의 보안 취약점을 검토합니다. SQL Injection, XSS, 인증 우회, 민감정보 노출을 중점적으로 봅니다.
tools:
- Read
- Grep
- Bash
model: claude-sonnet-4-5
---
당신은 시니어 보안 엔지니어입니다.
주어진 코드에서 OWASP Top 10 기반의 취약점을 식별하고,
각 취약점에 대해 다음을 보고하세요:
1. 취약점 종류
2. 발생 위치 (파일:라인)
3. 공격 시나리오
4. 권장 수정안ここで重要なのはdescriptionフィールドです。オーケストレーターはこの説明を見て委任するかどうかを判断するため、曖昧に書くと呼び出されなかったり、間違った作業に呼び出されたりします。
多重セッションエージェント実行の例
# ターミナル 1 — メインセッション
claude --worktree main
# ターミナル 2 — 同じリポジトリで別の機能を作業
claude --worktree feature-payments
# ターミナル 3 — ホットフィックス
claude --worktree hotfix-auth-bug各ワークツリーは.claude/worktrees/の下に独立したディレクトリとブランチを持ち、ファイルシステムレベルで隔離されます。
5つの軸で整理する管理方法論
1️⃣ コンテキスト管理 (Context Isolation)
サブエージェントの最大の価値は、メインコンテキストをきれいに保つことです。100個のファイルを探索する作業をメインエージェントが直接行うと、コンテキストウィンドウが爆発します。サブエージェントに委任すれば、中間過程はすべてサブエージェントの隔離されたコンテキスト内に留まり、最終的な要約だけがメインに戻ってきます。
Forked Subagentは例外です。メインセッションの全履歴を継承して開始するため、背景説明を再度行う必要がない代わりに、入力隔離を諦めるというトレードオフが発生します。
2️⃣ 状態およびハンドオフ管理
ハンドオフ時には何を渡すのかを明示的に定義する必要があります。OpenAI Agents SDKのハンドオフパターン、LangGraphのチェックポイント、MCP/A2Aプロトコルはすべてこの問題を解決するためのツールです。
よくある間違いは、「実装してくれ」のように曖昧なハンドオフメッセージを送ることです。必ず範囲、ファイル参照、期待される出力の3つの要素を含める必要があります。
3️⃣ 可観測性とコスト (Observability & Cost)
マルチエージェントは単一エージェントに比べてトークン使用量が3〜4倍に増加します。パターンによっては200%以上の差が出ることもあります。運用時に必ず追跡すべきメトリックは以下の通りです。
- エージェントごとのトークン使用量とコスト
- 決定ごとの応答時間
- ツール呼び出しチェーンの追跡 (LangSmith, Arize, OpenAI Tracing)
- 異常パターン通知 (ループ、繰り返しAPI失敗)
コスト削減のヒントとしては、メインセッションはOpus、サブエージェントはSonnetまたはHaikuに分離することで、品質を損なうことなくコストを大幅に削減できます。
4️⃣ インフラ (Infrastructure)
エンタープライズ規模では、エージェント運用はインフラ運用そのものになります。
- コンテナ化: エージェントごとのDocker隔離
- オーケストレーション: Kubernetesポッドの自動スケーリング
- GPUスケジューリング: 推論が重いエージェントは別途ノードプール
- メッセージバス: Kafka, RabbitMQによるエージェント間イベント伝達
5️⃣ セキュリティと権限 (Security & Permissions)
サブエージェントごとにツール権限を最小化する必要があります。セキュリティ監査エージェントは読み取り専用に、実装エージェントのみ書き込み権限を持つように設定します。また、Permission Presetを事前に承認しておかないと、エージェントをスポーンするたびに権限プロンプトの爆弾を浴びることになります。
⚠️ 実務で直面するよくある落とし穴
落とし穴 1. 最初から分散型で始める
最もよくある間違いです。メッシュパターンは格好良く見えますが、デバッグ地獄になります。常にOrchestrator-Workerから始めることをお勧めします。ほとんどのプロダクションチームは最終的に分散が必要ありません。
落とし穴 2. 過小並列化
独立した4つの分析を順次実行するケースが多く見られます。ドメインが独立していれば、無条件に並列化しましょう。
落とし穴 3. ハンドオフループ
A → B → A → B… 無限ループです。ガード条件と最大ホップ(hop)制限が必須です。
落とし穴 4. 多重セッションのマージコンフリクト
複数のセッションが同じファイルを同時に修正すると、結果はマージ衝突または部分的に適用された変更になります。必ずワークツリーまたはコンテナレベルで隔離する必要があります。
✅ まとめ — どのように決定するか
新しいプロジェクトを開始するなら、次の意思決定ツリーに従ってみましょう。
- 作業が本質的に異なる専門性を要求するか? → マルチエージェント
- 同じ作業を複数のデータ/ファイル/ブランチに同時に適用するか? → 多重セッション
- 両方に該当する場合? → マルチエージェントで役割を分離 + 各エージェントが必要に応じて子セッションをスポーン
そして、どのパターンを選択するにしても、中央集権から開始し、明確なボトルネックが見つかった場合にのみ分散せよというMicrosoftのガイドラインを忘れないでください。
エージェント時代の運用能力は、分散システム設計能力そのものです。マイクロサービスを運用した経験があれば、その直感はそのまま引き継がれます。慣れ親しんだ困難が新しい服を着て現れただけです。
コメントを残す