随着大数据和人工智能的最新发展,数据利用率不断提高,但同时,您是否担心您的个人信息会被泄露?😟仅仅删除姓名和电话号码并不安全。
今天,我们将用15分钟掌握用于安全披露数据的隐私保护模型(k, l, t, m)以及它们所抵御的可怕攻击技术!🚀
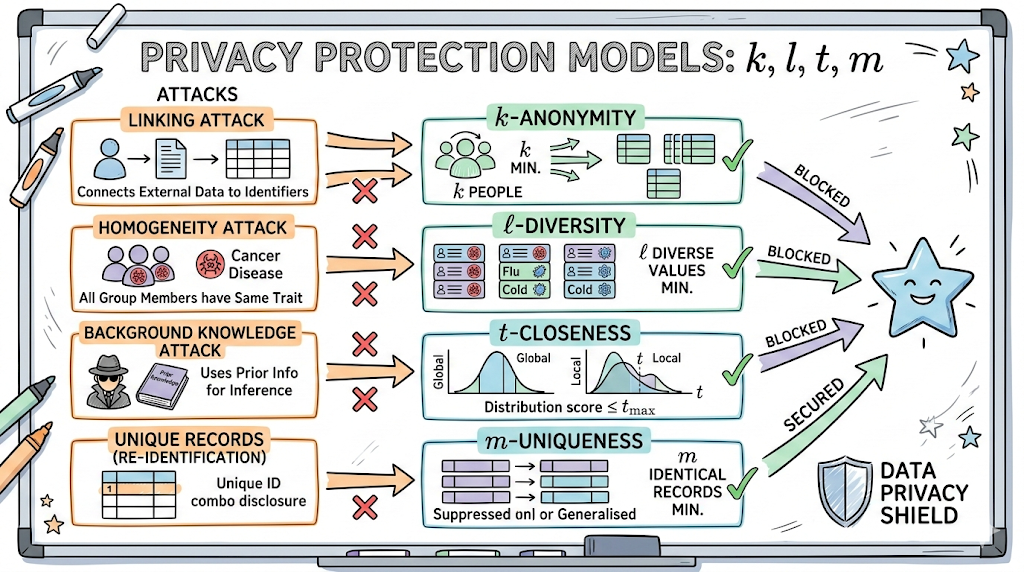
1. 为什么仅仅删除姓名是不够的?(数据攻击的类型)
即使删除了姓名、身份证号等直接标识符,如果与其他信息结合,也很快就能识别出个人身份。有三种主要的攻击方式利用了这一点。😈
- 🔗 连接攻击 (Linking Attack): 将去标识化数据与外部公开数据(例如:地址簿、社交媒体)结合,以识别特定个人的攻击。
- 👯 同质性攻击 (Homogeneity Attack): 当个人被分组时,该组内的所有敏感信息(例如疾病)都相同,从而使攻击者能够猜测某人是谁的攻击。
- 🧠 背景知识攻击 (Background Knowledge Attack): 利用攻击者的先验知识(例如“那个人平时喜欢喝酒,所以他一定有肝病”)来推断信息的攻击。
2. 保护数据的四大模型:隐私保护模型
为了防止这些攻击而进行数学设计的模型,正是我们今天学习的主角。
① k-匿名性 (k-anonymity): “独自一人很危险,必须k人以上!”
这是防御连接攻击最基础的模型。
- 核心: 泛化数据,使具有相同属性的记录至少存在k个。
- 效果: 即使攻击者查看数据,也无法识别出至少k个人中的具体是谁。(识别概率 1/k)
② l-多样性 (l-diversity): “即使在组内也要保持个性!”
仅靠k-匿名性无法阻止同质性攻击。(例如:如果3人被分组,而这3人都是癌症患者)
- 核心: 在同一组内,敏感信息(例如疾病名称)必须包含至少l种不同类型。
- 效果: 确保组内信息的多样性,防止对特定疾病名称的确定性。
③ t-接近性 (t-closeness): “偏颇的信息会引起怀疑!”
l-多样性也可能容易受到背景知识攻击或倾斜攻击的影响。
- 核心: 特定组的敏感信息分布必须与整个数据集的分布相似(距离小于或等于t)。
- 效果: 防止特定群体中某种疾病比例异常高的情况,从而从根本上阻止推断。
④ m-唯一性 (m-uniqueness): “唯一的数据是删除对象!”
与k-匿名性相似,但该模型更侧重于消除“唯一性”。
- 核心: 管理数据集,使其中存在至少m个相同的属性组合。
- 效果: 防止出现孤立数据(Outlier),从而降低再识别的可能性。
3. 一目了然的比较表 📊
| 模型名称 | 主要防御攻击 | 核心思想 |
|---|---|---|
| k-匿名性 | 连接攻击 | 保持k个或更多具有相同属性的记录 |
| l-多样性 | 同质性攻击,背景知识攻击 | 包含l种或更多类型的敏感信息 |
| t-接近性 | 倾斜攻击,背景知识攻击 | 最小化整体与组之间的数据分布差异 |
| m-唯一性 | 再识别攻击 | 保持m个相同的数据组合以避免唯一性 |
—
4. 通过代码理解去标识化概念(Python示例)💻
我们来看看如何通过代码简单地对数据进行分组并应用k-匿名性?
import pandas as pd
# 原始数据:姓名、年龄、地区、疾病
data = {
'Name': ['주군', 'A', 'B', 'C'],
'Age': [25, 28, 41, 44],
'City': ['서울', '서울', '부산', '부산'],
'Disease': ['감기', '독감', '위암', '위암']
}
df = pd.DataFrame(data)
# 1. 移除标识符(姓名)
df_anon = df.drop('Name', axis=1)
# 2. 年龄泛化(k-匿名性应用示例:按10岁为单位分组)
df_anon['Age'] = df_anon['Age'].apply(lambda x: f"{(x//10)*10}岁")
# 检查结果
print(df_anon)
# 输出结果:形成了年龄和地区相同的“20多岁-首尔”组和“40多岁-釜山”组!🕵️ 总结与结束
数据就像一把“双刃剑”。用得好是良药,管理不当则是毒药。我们今天学习的k, l, t模型是坚实的盾牌,让我们能够安心地利用数据。🛡️
您处理的数据拥有怎样的盾牌?在一个安全数据利用即竞争力的时代!
发表回复