ルールの一行が戦士なら、Pythonで振るうYARAは軍団だ。
コマンドラインを超えた真の自動化への第一歩。
>

この記事で扱う内容
- CLIの代わりにyara-pythonを使用する理由と、それがいつ必要になるか
- ライブラリのインストールからルールコンパイル、ファイル・メモリ・バイトスキャンまでの全プロセス
- ディレクトリの再帰スキャンとマッチング結果を扱うクリーンなパターン
- コールバック関数と外部変数(externals)でルールを動的に制御する手法
- 運用環境でよく遭遇する落とし穴と回避策
導入 — CLIを超えて自動化へ
yaraコマンドはアナリストの手になじんだナイフですが、それだけでは届かない領域があります。毎日数千の検体が届き、自動的に分類する必要がある場合、SIEMパイプラインに検出結果を流し込む必要がある場合、またはメモリダンプ内の特定のパターンをプロセスIDごとに追跡する必要がある場合 — これらすべての状況で、アナリストは最終的にコードを書くことになります。
yara-pythonはYARAの公式Pythonバインディングであり、Cで書かれたYARAエンジンのすべての機能をPythonオブジェクトとして公開します。コンパイル・キャッシュ・コールバック・外部変数・メモリ スキャンまで、CLIでは不自然または不可能な作業が、一行のメソッド呼び出しに変わります。
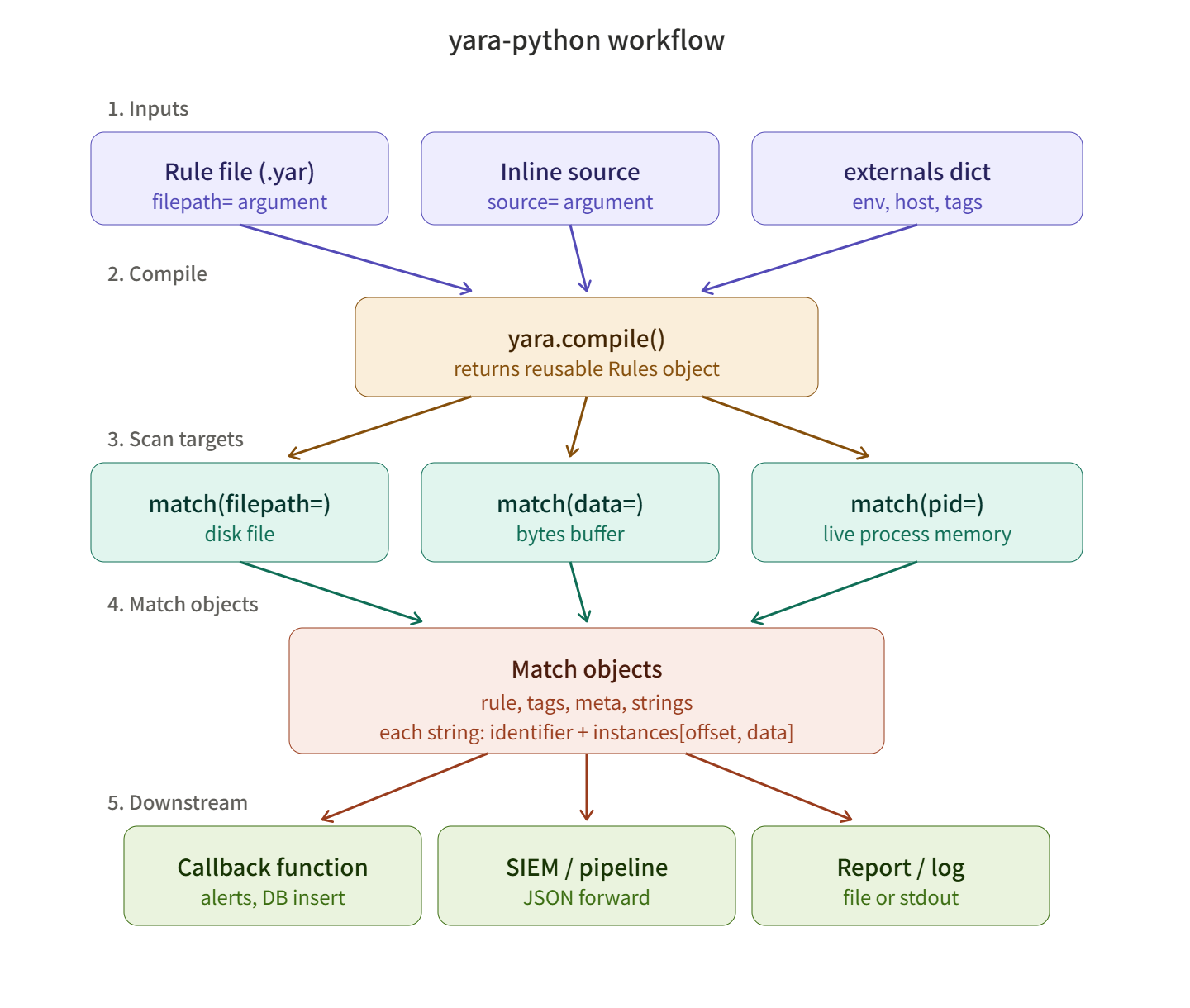
yara-pythonの主要構成
ライブラリの使用フローは単純です。
- yara.compile() — ルールをコンパイルし、再利用可能なRulesオブジェクトを作成します。ファイル、文字列、複数のソースを一度に受け取ることができます。
- rules.match() — ファイルパス、バイトデータ、プロセスPIDのいずれかをスキャン対象として受け取ります。
- Matchオブジェクト — マッチング結果は、ルール名、メタデータ、マッチした文字列とオフセットを含むオブジェクトとして返されます。
この3つをうまく扱えば、どんな自動化も構築できます。
実践 — コードでハンターを作る
ステップ0. 環境準備
# YARAエンジンはすでにインストールされている必要があります
sudo apt install -y yara # Debian / Ubuntu
brew install yara # macOS
# Pythonバインディングのインストール
pip install yara-python
# インストールの確認
python -c "import yara; print(yara.__version__)"ステップ1. 検出対象サンプルファイルの作成
前回と同様に、無害なダミーファイルを使用します。今回はPythonスクリプトで直接生成してみます。
# create_sample.py
SAMPLE = """#!/bin/bash
# Internal task runner v1.0
TASK_ID=ACME-EDU-2026
echo "Starting backup process..."
curl -s http://example-edu-lab.local/healthcheck
echo "Token: EDULAB_SIGNATURE_TOKEN_42"
exit 0
"""
with open("suspicious_sample.txt", "w", encoding="utf-8") as f:
f.write(SAMPLE)
print("[+] sample file created")ステップ2. YARAルールの作成
ルールファイルはそのままにしますが、今回はPythonで2つの方法で扱ってみます — 外部の.yarファイルをロードする方法と、ソース文字列を直接コンパイルする方法です。
// edulab_detector.yar
rule EDULAB_Suspicious_Script
{
meta:
author = "주군의 보안 강의실"
description = "EDULAB 식별자와 토큰을 포함한 셸 스크립트 탐지"
date = "2026-05-23"
severity = "medium"
strings:
$magic = "#!/bin/bash"
$id = "ACME-EDU-2026" ascii
$token = "EDULAB_SIGNATURE_TOKEN_42" ascii
condition:
filesize < 10KB
and $magic at 0
and all of ($id, $token)
}ステップ3. 最初のスキャナーの作成
コアフローであるコンパイル → スキャン → 結果出力を一つのファイルにまとめてみます。
# scanner_basic.py
import yara
# (1) ルールをコンパイル — ファイルからロード
rules = yara.compile(filepath="edulab_detector.yar")
# (2) 対象ファイルをスキャン
matches = rules.match(filepath="suspicious_sample.txt")
# (3) 結果を出力
if not matches:
print("[-] No matches.")
else:
for m in matches:
print(f"[!] Rule matched: {m.rule}")
print(f" Tags : {m.tags}")
print(f" Meta : {m.meta}")
for s in m.strings:
for inst in s.instances:
offset = inst.offset
data = inst.matched_data.decode("utf-8", errors="replace")
print(f" {s.identifier} @ 0x{offset:x} -> {data!r}")正常に動作すると、次のような出力が表示されます。
[!] Rule matched: EDULAB_Suspicious_Script
Tags : []
Meta : {'author': '주군의 보안 강의실', ...}
$magic @ 0x0 -> '#!/bin/bash'
$id @ 0x35 -> 'ACME-EDU-2026'
$token @ 0xa9 -> 'EDULAB_SIGNATURE_TOKEN_42'バージョン注意: yara-python 4.3.0以降、match.stringsはStringMatchオブジェクトのリストとなり、各オブジェクトはidentifierとinstancesを持ちます。それ以前のバージョン(3.x)では、(offset, identifier, data)タプルのリストでした。コード作成前に必ずyara.__version__を確認してください。
ステップ4. ルールを文字列から直接コンパイルする
設定ファイルなしでコード内で動的にルールを生成・テストする際に便利です。CIパイプラインや単体テストで特に威力を発揮します。
# scanner_inline.py
import yara
RULE_SOURCE = """
rule QuickHexSig {
meta:
description = "Detects bash shebang via hex pattern"
strings:
$hex = { 23 21 2F 62 69 6E 2F 62 61 73 68 }
condition:
$hex at 0
}
"""
rules = yara.compile(source=RULE_SOURCE)
# バイトデータを直接スキャンすることもできます — ファイルI/Oなしで!
with open("suspicious_sample.txt", "rb") as f:
data = f.read()
for m in rules.match(data=data):
print(f"[!] {m.rule} matched in-memory buffer.")data=引数は、メモリバッファやネットワークから受け取ったペイロードを即座に検査する際に決定的な武器となります。
ステップ5. ディレクトリ再帰スキャナー
実戦では、一つのファイルだけでなくツリー全体をスキャンします。例外処理とともにきれいにまとめておきます。
# scan_tree.py
import os
import sys
import yara
def build_rules(rule_path: str) -> yara.Rules:
try:
return yara.compile(filepath=rule_path)
except yara.SyntaxError as e:
print(f"[error] rule syntax error: {e}", file=sys.stderr)
sys.exit(1)
def scan_tree(rules: yara.Rules, root: str) -> None:
hit_count = 0
for dirpath, _, filenames in os.walk(root):
for name in filenames:
path = os.path.join(dirpath, name)
try:
matches = rules.match(filepath=path, timeout=10)
except yara.TimeoutError:
print(f"[warn] timeout: {path}", file=sys.stderr)
continue
except (PermissionError, yara.Error) as e:
print(f"[skip] {path}: {e}", file=sys.stderr)
continue
for m in matches:
hit_count += 1
print(f"[HIT] {m.rule} -> {path}")
print(f"
[+] Scan complete. {hit_count} hit(s).")
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: python scan_tree.py <rules.yar> <target_dir>")
sys.exit(1)
rules = build_rules(sys.argv[1])
scan_tree(rules, sys.argv[2])timeout引数に注目してください。巨大なバイナリや圧縮ファイルに遭遇した際に、無限にハングアップするのを防ぎます。
ステップ6. コールバックと外部変数によるきめ細やかな制御
yara-pythonの本当の魅力は、コールバック関数と外部変数にあります。マッチングが発生するたびに呼び出される関数を登録することで、マッチング直後に通知を送信したり、データベースに記録したりするなどの副作用を自然に組み込むことができます。
# scanner_callback.py
import yara
def on_match(data):
"""매칭 발생 시 호출되는 콜백"""
if data["matches"]:
print(f"[CALLBACK] Rule '{data['rule']}' fired")
print(f" Namespace: {data['namespace']}")
print(f" Tags : {data['tags']}")
# ここでSlack通知、DB挿入、SIEM転送などを自由に処理
return yara.CALLBACK_CONTINUE
# 外部変数をルールで参照できるように宣言
RULE = """
rule HighRiskHost {
condition:
env == "production" and filesize < 5KB
}
"""
rules = yara.compile(source=RULE, externals={"env": "staging"})
# スキャン時に外部変数の値を動的に置き換えることができる
rules.match(
filepath="suspicious_sample.txt",
externals={"env": "production"},
callback=on_match,
which_callbacks=yara.CALLBACK_MATCHES,
)externalsは、環境変数、ホストタグ、ユーザーグループなどのコンテキスト情報をルールに注入する洗練された方法です。これにより、同じルールが運用環境では発火し、開発環境では沈黙するように設定できます。
⚠️ 注意事項 — 運用における落とし穴
- コンパイルコスト: yara.compile()は決して軽量ではありません。同じルールを繰り返し使用する場合は、一度コンパイルしたRulesオブジェクトを再利用するか、rules.save() / yara.load()でディスクにキャッシュしておく必要があります。
- スレッド安全性: Rulesオブジェクトはスレッドセーフですが、同じオブジェクトで同時にmatch()を呼び出すと、内部同期コストが発生する可能性があります。高性能が必要な場合は、multiprocessingを検討してください。
- メモリ スキャン権限: rules.match(pid=1234)で他のプロセスのメモリを検査するには、適切な権限(root、CAP_SYS_PTRACEなど)が必要です。権限がない場合、yara.Errorがスローされます。
- 外部変数タイプの一致: externalsに渡す値のタイプ(文字列・整数・浮動小数点数・ブーリアン)がルールで宣言されたタイプと異なる場合、コンパイル段階で失敗します。
- エンコーディングの落とし穴: マッチしたバイトは常にbytes型です。そのまま出力せず、必ず.decode(…, errors=”replace”)で囲むことで、壊れた文字でクラッシュするのを防ぐ必要があります。
✅ まとめ — コードを携えたハンターになる
yara-pythonは単なるバインディングではなく、YARAを真の自動化システムに変貌させる架け橋です。CLIの一行の結果をテキストで受け取り、再度パースしていた時代は終わりました。今や、マッチング結果をオブジェクトとして受け取り、そのままデータパイプラインに流し込むことができます。
次のステップに進むと、このような道が開けます。
- FastAPI / Flaskでラップして社内スキャンAPIを構築する
- CeleryやRQで分散スキャンキューを構築する
- Volatility3プラグインと組み合わせてメモリフォレンジックにYARAを適用する
- VirusTotal API + yara-pythonの組み合わせで社内脅威インテリジェンスワークフローを自動化する
- mkYARA、yaraGenなどのツールでルールを自動生成 → コードで検証するパイプライン
ルールの一行が数百台のサーバーを守り、コードの一つの関数がそのルールを数千回実行します。主君の狩りは、もはや手ではなくコードによって行われます。️
コメントを残す