当只运行一个智能体时,只需写好提示词就足够了。
然而,当智能体变成两个时,它就变成了一个分布式系统。
>

本文涵盖内容
- 多智能体(Multi-Agent)与多会话智能体(Forked / Parallel Session)的本质区别
- 5种核心编排模式 — Orchestrator-Worker, Swarm, Mesh, Hierarchical, Pipeline
- 实践中遇到的陷阱 — 切换循环、令牌激增、上下文冲突
- 管理方法论的5个支柱 — 上下文、状态、通信、可观测性、安全
为何现在讨论这个话题
如果说2024年是“AI智能体元年”,那么2025-2026年则成为了运营(Operate) 智能体之年。那些从单个智能体开始的项目,不知不觉中已经演变为5个、10个、20个智能体同时运行的系统。
在这个节点上,我们面临着第一道障碍。
我知道需要增加智能体,但究竟是应该设置多个智能体,
还是应该增加单个智能体的会话数量?
这两种方法看似相似,但其运营理念却截然不同。如果选择错误,可能会花费数月时间与协调开销作斗争,导致产品开发停滞不前。
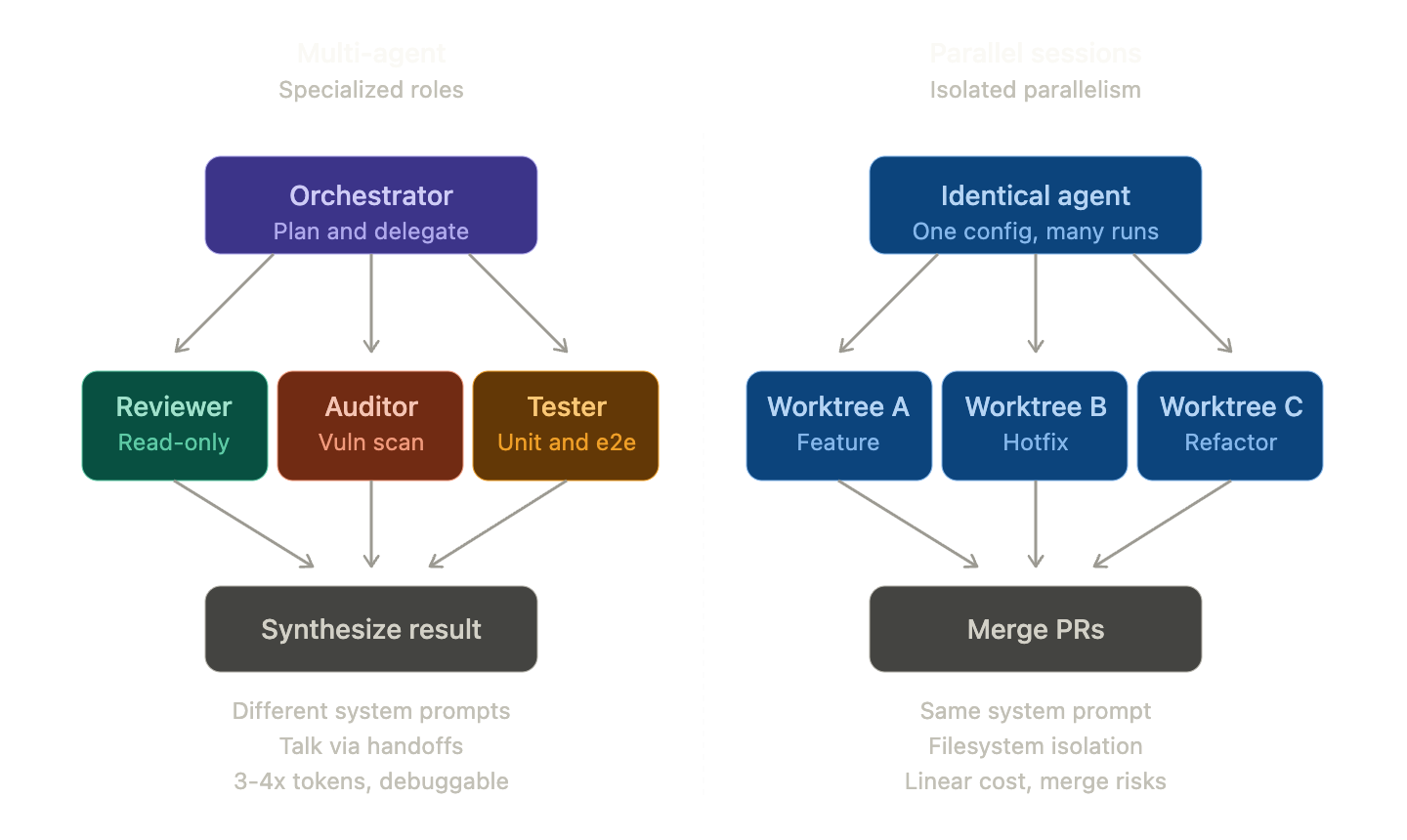
两种模式的本质区别
多智能体 (Multi-Agent System)
这是一种由具有不同角色(Role) 和系统提示词的多个智能体协作的结构。Anthropic的Claude Code官方文档对此解释如下:
“Subagents work within a single session; agent teams coordinate across separate sessions.”
换句话说,多智能体的核心是专业化(Specialization)。代码审查员、安全审计员、文档编写者、测试编写者各自拥有不同的系统提示词和工具权限,并进行协作。
多会话智能体 (Parallel Sessions / Forked Subagents)
这是一种具有相同模型、相同权限和相同上下文的智能体,分散在多个工作区(Worktree, Branch, Container) 中同时运行的结构。Claude Code 2.1.50中新增的–worktree标志就是典型的例子。
# 保持主会话不变,在单独的worktree中启动新会话
claude --worktree feature-auth其核心价值是隔离(Isolation) 和并行性(Parallelism)。它允许在同一代码库上同时处理不同的功能,而不会产生冲突。
一句话总结
| 区分 | 多智能体 | 多会话智能体 |
| 核心价值 | 专业化 (角色分离) | 隔离 (工作空间分离) |
| 智能体定义 | N个不同的提示词 | 1个相同的提示词 |
| 通信方式 | 切换、消息队列 | 独立 (必要时仅合并结果) |
| 成本模式 | 可按角色使用不同模型 | N倍线性增长 |
| 典型陷阱 | 切换循环 | 合并冲突 |
—
️ 5种编排模式
生产环境的多智能体系统最终归结为以下五种模式之一,或其组合。
1. Orchestrator-Worker (Supervisor)
这是最广泛使用的模式。中央编排器接收用户请求,将其分解为子任务,委派给专业的工人智能体,然后综合结果。
- 优点: 易于调试,追踪清晰,输出验证方便
- 缺点: 编排器成为单点故障(SPOF)
- 推荐时机: 几乎所有起点。微软官方指南建议“从集中式开始,只有在发现明确瓶颈时才进行分布式部署”
2. Swarm (Handoff)
OpenAI Agents SDK采用的模式。智能体之间通过显式切换来传递控制权,同时传递对话上下文。没有中央编排器,而是每个智能体直接决定下一个智能体。
3. Mesh
所有智能体都可以相互通信的完全分布式系统。恢复能力最高,但容易陷入切换循环(A → B → A),因此必须设计好防护条件。
4. Hierarchical
编排器之下还有编排器的多层结构。适用于大型企业系统。
5. Pipeline
数据按顺序阶段流动的结构。一个智能体的输出成为下一个智能体的输入。这与CI/CD中的思维方式相同。
实战:多智能体定义示例
让我们看看Claude Agent SDK中如何定义子智能体。
# .claude/agents/security-reviewer.md
---
name: security-reviewer
description: 코드의 보안 취약점을 검토합니다. SQL Injection, XSS, 인증 우회, 민감정보 노출을 중점적으로 봅니다.
tools:
- Read
- Grep
- Bash
model: claude-sonnet-4-5
---
당신은 시니어 보안 엔지니어입니다.
주어진 코드에서 OWASP Top 10 기반의 취약점을 식별하고,
각 취약점에 대해 다음을 보고하세요:
1. 취약점 종류
2. 발생 위치 (파일:라인)
3. 공격 시나리오
4. 권장 수정안这里的核心是description字段。编排器会根据这个描述来判断是否委派,如果写得模糊,可能不会被调用或被错误地调用到不相关的任务上。
多会话智能体执行示例
# 终端 1 — 主会话
claude --worktree main
# 终端 2 — 在同一仓库中处理不同功能
claude --worktree feature-payments
# 终端 3 — 热修复
claude --worktree hotfix-auth-bug每个worktree在.claude/worktrees/下拥有独立的目录和分支,并在文件系统层面进行隔离。
5个支柱总结管理方法论
1️⃣ 上下文管理 (Context Isolation)
子智能体的最大价值在于保持主上下文的清洁。如果主智能体直接处理探索100个文件的任务,上下文窗口将会爆炸。委派给子智能体后,所有中间过程都将保留在子智能体的隔离上下文中,只有最终摘要返回给主智能体。
分叉子智能体是一个例外。它们继承主会话的全部历史记录开始,这意味着无需重新解释背景信息,但代价是放弃了输入隔离。
2️⃣ 状态与切换管理
在切换时,必须明确定义要传递什么。OpenAI Agents SDK的切换模式、LangGraph的检查点以及MCP/A2A协议都是解决这个问题的工具。
常见的错误是发送模糊的切换消息,例如“帮我实现一下”。必须包含范围、文件引用和预期输出这三个要素。
3️⃣ 可观测性与成本 (Observability & Cost)
多智能体系统的令牌使用量比单个智能体系统增加3-4倍。根据模式不同,甚至可能存在200%以上的差异。运营时必须追踪以下指标:
- 每个智能体的令牌使用量和成本
- 每次决策的响应时间
- 工具调用链追踪 (LangSmith, Arize, OpenAI Tracing)
- 异常模式警报 (循环、重复API失败)
成本节约技巧是,将主会话使用Opus,子智能体使用Sonnet或Haiku,可以在不损失质量的情况下大幅降低成本。
4️⃣ 基础设施 (Infrastructure)
在企业规模下,智能体运营即是基础设施运营。
- 容器化: 每个智能体的Docker隔离
- 编排: Kubernetes Pod自动扩缩容
- GPU调度: 推理密集型智能体使用单独的节点池
- 消息总线: Kafka, RabbitMQ用于智能体间事件传递
5️⃣ 安全与权限 (Security & Permissions)
应最小化每个子智能体的工具权限。将安全审计智能体设置为只读,仅允许实现智能体拥有写入权限。此外,如果未预先批准权限预设(Permission Preset),每次生成智能体时都会面临权限提示轰炸。
⚠️ 实践中常见的陷阱
陷阱 1. 从一开始就采用分布式系统
这是最常见的错误。Mesh模式可能看起来很酷,但会导致调试地狱。请始终从Orchestrator-Worker模式开始。大多数生产团队最终并不需要分布式系统。
陷阱 2. 并行化不足
常见的情况是顺序执行4个独立的分析。如果领域是独立的,务必进行并行化。
陷阱 3. 切换循环
A → B → A → B… 无限循环。必须设置防护条件和最大跳数限制。
陷阱 4. 多会话的合并冲突
如果多个会话同时修改同一个文件,结果将是合并冲突或部分应用的更改。必须在worktree或容器级别进行隔离。
✅ 总结 — 如何决策
如果你正在启动一个新项目,请遵循以下决策树:
- 任务本质上是否需要不同的专业性? → 多智能体
- 是否将相同的任务同时应用于多个数据/文件/分支? → 多会话
- 如果两者都适用? → 使用多智能体进行角色分离 + 每个智能体在需要时生成子会话
无论选择哪种模式,都不要忘记微软的指导方针:从集中式开始,只有在发现明确瓶颈时才进行分布式部署。
智能体时代的运营能力,就是分布式系统设计能力。如果你有微服务运营经验,这种直觉会直接延续。熟悉的难题只是换了一件新衣出现而已。
发表回复