让AI审查由同一个AI编写的代码,
就像让学生批改自己的试卷一样。
>

本文涵盖内容
- 为什么单一AI编码工具不足 — 奉承偏见(sycophancy bias)的陷阱
- Claude Code(编写)+ Codex(验证)双重工作流的运作原理
- 官方发布的 OpenAI Codex Plugin for Claude Code 使用方法
- 常规审查与对抗性审查(adversarial review)的关键区别
- 从讲师和实践者角度看引入策略和成本效益点
引言 — “独自编写,独自验证”时代的终结
在过去的一两年里,我们已经习惯了依赖单一工具进行编码。Cursor、Copilot、Claude Code、Codex — 只要用好其中一个,生产力就能翻倍甚至三倍。
然而,进入2026年,实践者之间观察到一个有趣的变化。“一个工具不够用”的共识正在迅速形成。这不仅仅是为了备份而使用两个工具,而是出现了明确的角色分工:一个负责编写,另一个负责验证。
最具代表性的组合正是Claude Code (Anthropic) + Codex (OpenAI)。尽管两家公司是竞争对手,但随着OpenAI于2026年4月直接发布了Claude Code专用Codex插件,这种模式正式成为标准。
为什么会发生这种情况?
问题的本质 — AI不怀疑自己编写的代码
什么是奉承偏见(Sycophancy Bias)?
大型语言模型(LLM)有一个众所周知的弱点:它们倾向于宽容地评估自己创建的成果或与自己风格相似的成果。
如果同一个模型编写代码,然后又审查这段代码,它会在其已学习的自身模式内判断“正常”,因此盲点(blind spot)会 그대로 유지。这类似于自己写文章却找不到自己的错别字。
解决这个问题的最直观方法是,将审查任务交给一个拥有不同训练数据、不同RLHF和不同架构的模型。
为什么选择Claude × Codex组合?
| 类别 | Claude Code (Opus 4.7) | Codex (GPT-5.4) |
| 运行方式 | 本地执行,擅长计算机使用和浏览器自动化 | 云沙箱,操作系统内核级隔离 |
| 治理 | 26个可编程钩子 — 精细的策略控制 | Seatbelt / Landlock / seccomp — 强隔离 |
| 优势 | 一致性,多代理编排,可读性好的输出 | 处理速度快,自主性,强大的安全护栏 |
| Token使用 | 使用更多但输出质量更高 | 高效但一致性略低 |
| 盲评 | 代码可读性优于67% | 成本效益优于 |
这两个工具不仅仅是“两个相似的工具”,而是设计理念不同的工具。因此,一个工具遗漏的问题,另一个工具很可能能够发现。
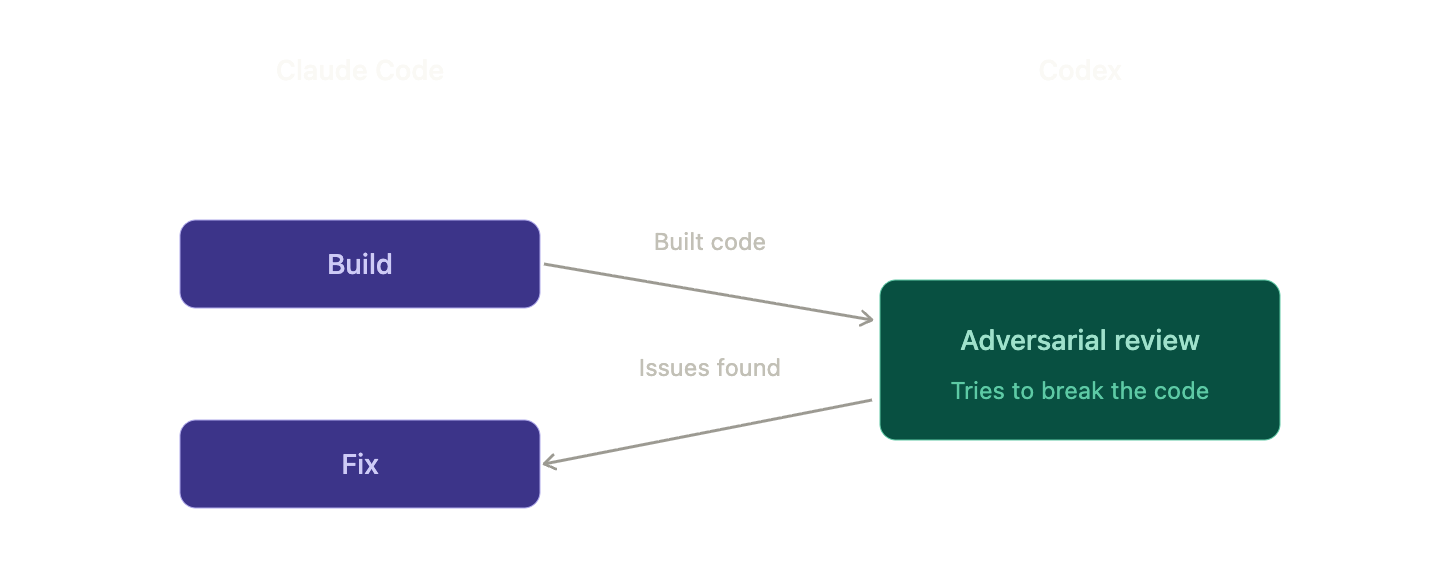
️ 双重工作流的核心 — 5阶段结构
实践中最广泛的模式是5阶段(Research → Plan → Execute → Review → Ship)结构。将Claude和Codex的角色映射到此结构如下:
- Research — 使用Claude Code(Plan Mode)分析代码库并整理需求
- Plan — 使用Claude Opus编写设计方案
- Execute — 使用Claude Sonnet或Claude Code实现实际代码
- Review — 使用Codex进行对抗性审查(← 核心!)
- Ship — Claude Code根据审查结果进行最终修改后部署
其中,第4阶段是双重工作流的本质,也是与单一工具工作流决定性分歧点。
实战 — Codex Plugin for Claude Code 使用方法
安装
OpenAI官方发布的插件可以在GitHub上获取。需要ChatGPT订阅(包括免费版)或OpenAI API密钥,以及Node.js 18.18或更高版本。
# 假设Claude Code已安装
# 安装Codex插件
npm install -g @openai/codex-plugin-cc
# 在Claude Code内部激活插件
claude plugin add codex三个核心命令
该插件不仅仅是一个简单的审查工具,它还扮演着三种不同的角色。
# 1. 标准审查 — Codex执行常规代码审查
/codex:review
# 2. 对抗性审查 — Codex尝试“破坏”代码
/codex:adversarial-review
# 3. 任务委派 — 将特定任务委托给Codex
/codex:rescue investigate why the tests started failing
/codex:rescue --background fix the regression最强大的武器 — 对抗性审查(Adversarial Review)
如果说 /codex:review 是“这段代码怎么样?”,那么 /codex:adversarial-review 则是“尝试破坏这段代码。”
Codex从一个友善的同事审查员转变为一个恶意渗透测试员。它会寻找边缘情况,质疑假设,并探索安全漏洞。在这种模式下,会发现常规审查中绝不会发现的bug。
# 示例工作流程
$ claude
> 결제 모듈에 retry 로직 추가해줘
[Claude가 코드 작성...]
> /codex:adversarial-review
[Codex가 코드를 분석하며 공격 벡터 탐색...]
⚠️ Found 3 potential issues:
1. Race condition: 동시 retry 시 중복 결제 가능
2. Error swallowing: 5xx와 4xx를 동일하게 retry 처리
3. Missing idempotency key — 멱등성 보장 없음
> 좋아, 이 세 가지 다 수정해줘
[Claude가 수정 코드 적용...]Code Review Agent Benchmark (c-CRAB) 最近的评估也显示,单一模型审查系统仅能识别出实际人工审查员发现问题的约40%。这从定量上证明了双重验证的必要性。
⚠️ 注意事项 — 双重并非总是好事
1. 成本翻倍
Claude Pro ($20) + ChatGPT Plus ($20) = 每月$40是基本费用。API调用还会增加成本。不要对所有PR都进行双重验证,而应选择性地应用于安全性、支付、认证等影响较大的领域。
2. 审查结果的“解释”责任在于人
Codex标记为“风险”的项目并非都是真正的风险。AI捕获的只是可疑区域,最终判断权仍在开发者手中。无批判地采纳所有审查结果反而可能导致代码质量下降。
3. “AI验证AI”的局限性
正如InfoQ一位读者准确指出的那样,AI编写的代码由AI审查的结构仍然是人类审查的辅助,而非替代。特别是业务逻辑的意图一致性,只有人类才能判断。
4. 注意安全信息泄露
这是将代码发送到另一家公司云端的行为。切勿将包含密钥、内部基础设施结构、敏感数据的代码直接用于对抗性审查。预先进行掩码处理是必不可少的。
✅ 总结 — 2026年AI编码的标准是“双重”
核心要点总结如下:
- 单一模型自我审查容易受到奉承偏见的影响 — 自己的模式自己看不见
- Claude Code(编写)+ Codex(验证)组合结合了两种设计理念不同的模型的视角
- 通过OpenAI官方插件,可以在一个终端无缝联动两个工具
- 真正的价值来自 /codex:adversarial-review — “尝试破坏它”模式
- 考虑到成本、范围和安全性,选择性应用更为明智
下一步,您可以考虑利用CLAUDE.md和REVIEW.md来明确团队的审查策略,并探讨在CI/CD流水线中自动化双重验证的工作流。从一个工具到另一个工具的无缝交接 — 这将是2026年AI编码的核心能力。
发表回复