AIが書いたコードを同じAIにレビューさせるのは、
学生に自分の試験用紙を採点させるようなものだ。
>

この記事で扱うこと
- なぜ単一のAIコーディングツールでは不十分なのか — 追従バイアス(sycophancy bias)の罠
- Claude Code(作成)+ Codex(検証)デュアルワークフローの動作原理
- 公式リリースされたOpenAI Codex Plugin for Claude Codeの使用方法
- 一般レビュー vs 敵対的レビュー(adversarial review)の決定的な違い
- 講師・実務者の観点から見た導入戦略と費用対効果のポイント
導入 — 「一人で書いて一人で検証する」時代の終焉
過去1〜2年間、私たちは一つのツールに依存するコーディングに慣れてきました。Cursor、Copilot、Claude Code、Codex — どれか一つをうまく使えば、生産性は2倍、3倍になります。
しかし、2026年に入り、実務者の間で興味深い変化が観察されています。「一つでは不十分だ」という合意が急速に形成されています。単にバックアップ用として二つを使うのではなく、一方が作成し、もう一方が検証するという明確な役割分担が登場したのです。
最も代表的な組み合わせが、まさにClaude Code(Anthropic)+ Codex(OpenAI)です。両社が競合であるにもかかわらず、2026年4月にOpenAIが直接Claude Code用Codexプラグインを公式配布したことで、このパターンが本格的に標準として定着しました。
なぜこのようなことが起こったのでしょうか?
問題の本質 — AIは自分が書いたコードを疑わない
追従バイアス(Sycophancy Bias)とは
LLMにはよく知られた弱点が一つあります。自分が作成した成果物や自分のスタイルに似た成果物を寛大に評価するというものです。
同じモデルがコードを作成し、そのコードを再度レビューすると、すでに学習された自己パターン内で「正常」を判断するため、ブラインドスポット(blind spot)がそのまま維持されます。例えるなら、自分の文章の誤字を自分では見つけられない現象に似ています。
この問題を解決する最も直感的な方法は、異なる学習データ・異なるRLHF・異なるアーキテクチャを持つモデルにレビューを任せることです。
なぜClaude × Codexの組み合わせなのか
| 区分 | Claude Code (Opus 4.7) | Codex (GPT-5.4) |
| 運用方式 | ローカル実行、コンピュータ使用・ブラウザ自動化に強み | クラウドサンドボックス、OSカーネル単位の隔離 |
| ガバナンス | 26個のプログラマブルフック — きめ細やかなポリシー制御 | Seatbelt / Landlock / seccomp — 強力な隔離 |
| 強み | 一貫性、マルチエージェントオーケストレーション、可読性の高い出力 | 高速処理、自律性、強力なセキュリティガードレール |
| トークン使用 | 多く使うが、出力品質が高い | 効率的だが、一貫性はやや低い |
| ブラインド評価 | コード可読性 67%優勢 | 費用対効果優勢 |
これら二つのツールは単に「似たようなツール二つ」ではなく、設計思想が異なるツールです。そのため、一方が見落とすものをもう一方が見つけ出す可能性が高いのです。
️ デュアルワークフローの核心 — 5段階構造
実務で最も広く普及しているパターンは、5段階(Research → Plan → Execute → Review → Ship)構造です。ここにClaudeとCodexの役割をマッピングすると以下のようになります。
- Research — Claude Code(Plan Mode)でコードベース分析および要件整理
- Plan — Claude Opusで設計案作成
- Execute — Claude SonnetまたはClaude Codeで実際の実装
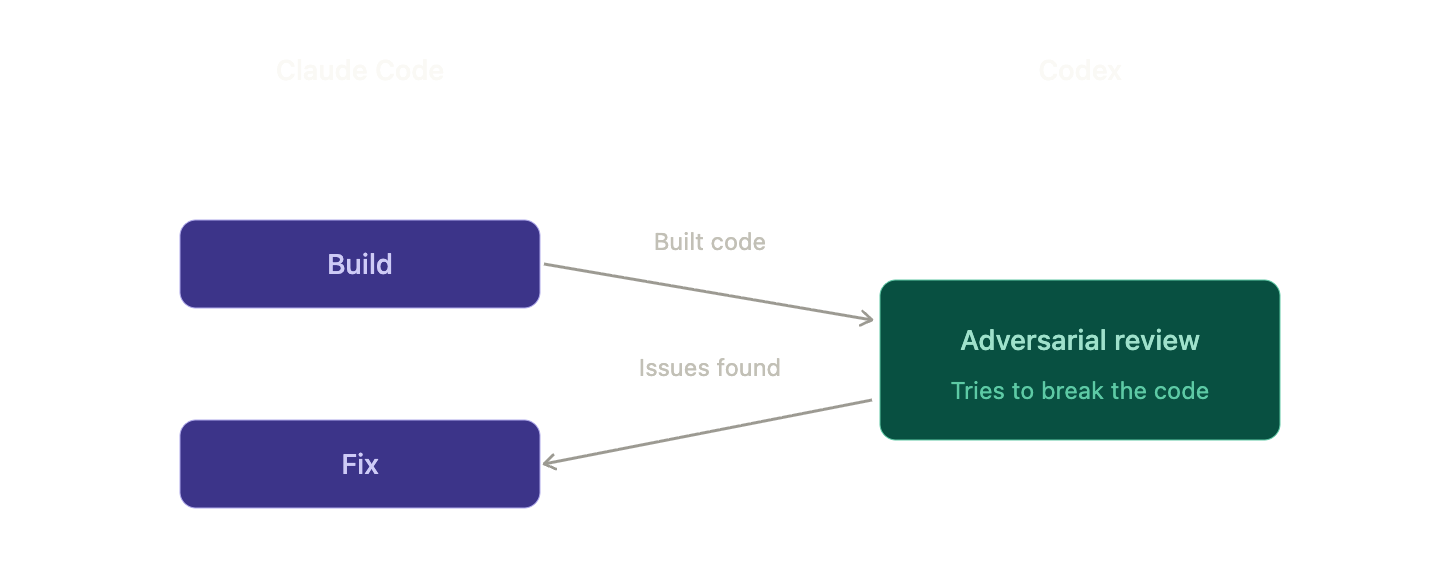
- Review — Codexで敵対的レビュー(←核心!)
- Ship — レビュー結果を反映してClaude Codeが最終修正後、デプロイ
ここで4段階目がデュアルワークフローの本質であり、単一ツールワークフローと決定的に異なる点です。
実践 — Codex Plugin for Claude Codeの使用方法
インストール
OpenAIが公式配布したプラグインはGitHubから入手できます。ChatGPTサブスクリプション(無料版を含む)またはOpenAI APIキー、そしてNode.js 18.18以上が必要です。
# Claude Codeがすでにインストールされていると仮定
# Codexプラグインをインストール
npm install -g @openai/codex-plugin-cc
# Claude Code内でプラグインを有効化
claude plugin add codex三つの主要コマンド
プラグインは単なるレビューツールではなく、三つの異なる役割を果たします。
# 1. 標準レビュー — Codexが一般的なコードレビューを実行
/codex:review
# 2. 敵対的レビュー — Codexがコードを「破壊しようと」試みる
/codex:adversarial-review
# 3. タスク委任 — 特定のタスクをCodexに委任
/codex:rescue investigate why the tests started failing
/codex:rescue --background fix the regression最も強力な武器 — 敵対的レビュー(Adversarial Review)
/codex:reviewが「このコードどうですか?」であるならば、/codex:adversarial-reviewは「このコードを壊してみて」です。
Codexは親切な同僚レビューアではなく、悪意のある侵入テスターの視点に変身します。エッジケースを見つけ出し、仮定を疑い、セキュリティの脆弱性を探索します。一般的なレビューでは決して発見できない種類のバグがここから見つかります。
# 例のワークフロー
$ claude
> 결제 모듈에 retry 로직 추가해줘
[Claude가 코드 작성...]
> /codex:adversarial-review
[Codex가 코드를 분석하며 공격 벡터 탐색...]
⚠️ Found 3 potential issues:
1. Race condition: 동시 retry 시 중복 결제 가능
2. Error swallowing: 5xx와 4xx를 동일하게 retry 처리
3. Missing idempotency key — 멱등성 보장 없음
> 좋아, 이 세 가지 다 수정해줘
[Claude가 수정 코드 적용...]Code Review Agent Benchmark(c-CRAB)の最近の評価でも、単一モデルレビューシステムは、実際の人間レビューアが発見した問題の約40%しか識別できなかったという結果が出ています。デュアル検証の必要性が定量的に証明されたわけです。
⚠️ 注意事項 — デュアルだからといって全てが良いわけではない
1. コストが2倍になる
Claude Pro($20)+ ChatGPT Plus($20)= 月額$40が基本ラインです。API呼び出しまで含めるとさらにかかります。全てのPRをデュアル検証するのではなく、セキュリティ・決済・認証など影響の大きい領域に選択的に適用してください。
2. レビュー結果の「解釈」責任は人にある
Codexが「危険」とマークした項目が全て本当の危険とは限りません。AIが検出するのは疑わしい区間に過ぎず、最終的な判断は結局開発者の役割です。レビュー結果を無批判に全て反映すると、かえってコードが劣化する可能性があります。
3. 「AIがAIを検証」の限界
InfoQで一読者が正確に指摘したように、AIが作成したコードをAIがレビューする構造は、依然として人間による検証の代替ではなく補助です。特にビジネスロジックの意図との整合性は、人間だけが判断できます。
4. セキュリティ情報漏洩に注意
コードを他社のクラウドに送信する行為です。シークレットキー、内部インフラ構造、機密データが含まれるコードをそのまま敵対的レビューに渡さないでください。事前のマスキングは必須です。
✅ まとめ — 2026年AIコーディングの標準は「デュアル」である
核心を再度まとめると以下の通りです。
- 単一モデルの自己レビューは追従バイアスに脆弱 — 自分のパターンは自分では見えない
- Claude Code(作成)+ Codex(検証)の組み合わせは、設計思想が異なる二つのモデルの視点を結合する
- OpenAI公式プラグインにより、一つのターミナルから二つのツールをシームレスに連携できる
- 真の価値は/codex:adversarial-review — 「壊してみて」モードから生まれる
- コスト・範囲・セキュリティを考慮し、選択的に適用することが賢明である
次のステップとしては、CLAUDE.mdとREVIEW.mdを活用してチームのレビューポリシーを明文化し、CI/CDパイプラインにデュアル検証を自動化するワークフローを検討してみるのが良いでしょう。一つのツールから別のツールへのスムーズなハンドオフ — これが2026年AIコーディングの核心的な能力です。
コメントを残す