静态抑或动态,此乃问题所在。
— 而LLM正在重写这个答案。
>

本文涵盖内容
- 5分钟内总结SAST与DAST的本质区别
- LLM为两大阵营带来的颠覆性变革
- LLM SAST与LLM DAST的优缺点比较
- 实际部署时可能遇到的陷阱与成本结构
- 将LLM融入DevSecOps流水线的逐步指南
引言:安全测试为何再次升温
如今,代码的生成速度已超越人类。Copilot、Cursor、Claude Code等AI助手每天吐出数万行代码,开发者甚至来不及审查就合并了PR。问题在于——如此快速增长的代码,并不会同样快速地变得安全。
传统的SAST和DAST难以跟上这个时代的步伐。基于规则的扫描器会像炸弹一样抛出大量误报(false positive),导致开发者最终完全忽视警报。业界称之为“警报疲劳”。这正是“狼来了”的故事所描述的现象:喊得太多,狼真的来了也没人信。
此时,LLM这一变量介入。随着能够理解代码含义的AI出现,安全测试的格局再次被撼动。
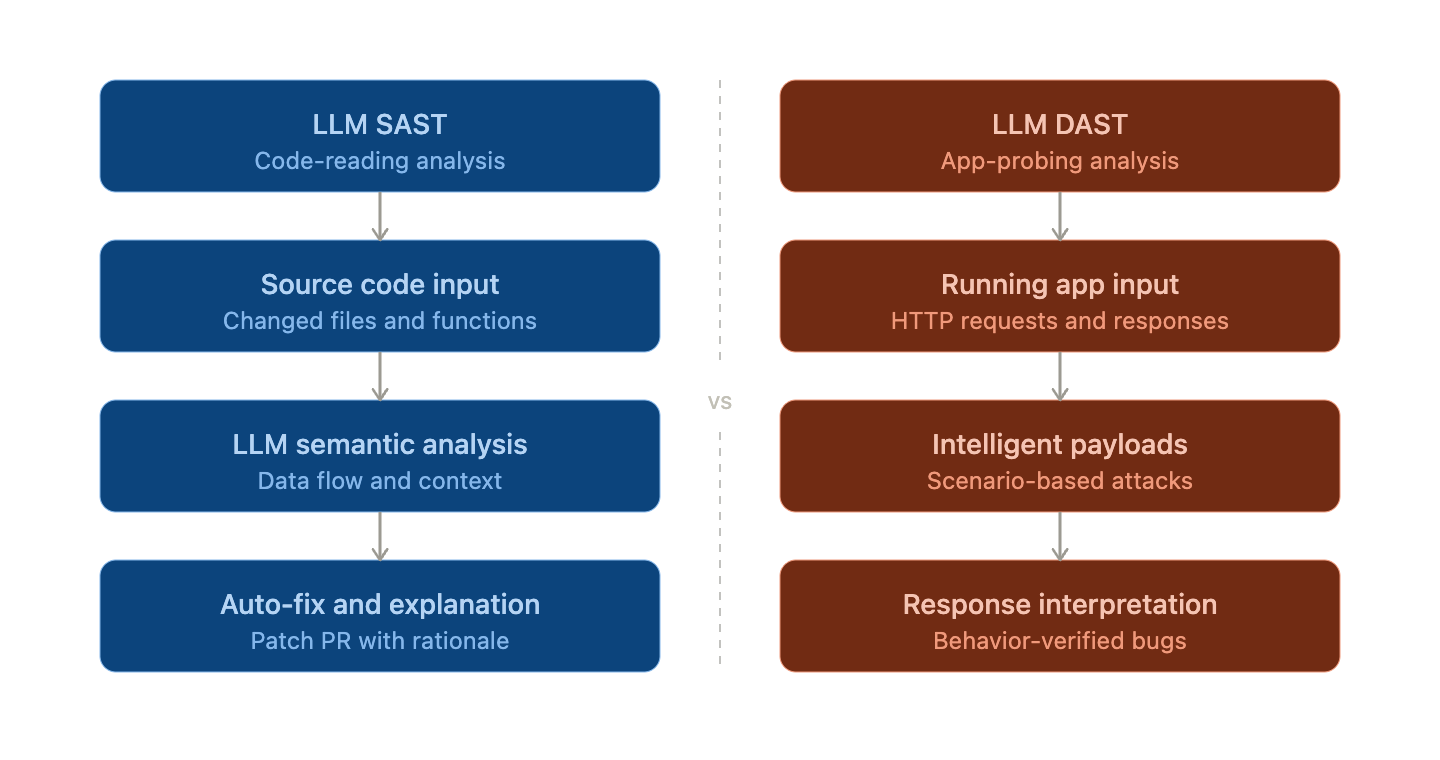
SAST与DAST,有何不同?
首先,我们从基础知识开始。
SAST (静态应用安全测试)
- 一句话总结:“摊开代码阅读”
- 分析对象:源代码、字节码、二进制文件
- 时机:构建阶段(不执行)
- 视角:白盒 — 了解内部结构
- 捕获内容:SQL注入模式、硬编码密码、不安全的函数调用、数据流漏洞
DAST (动态应用安全测试)
- 一句话总结:“实际敲击应用程序”
- 分析对象:运行中的应用程序(HTTP请求·响应)
- 时机:预演或生产环境
- 视角:黑盒 — 在不了解内部结构的情况下从外部攻击
- 捕获内容:认证·授权绕过、会话管理缺陷、服务器配置错误、实际触发的XSS
用一个简单的比喻来总结:
SAST就像一位建筑审查员,摊开建筑图纸,指出“这堵墙太薄了,有倒塌的风险”。
DAST则像一位安全检查员,拿着锤子去实际的建筑物上,确认“这里真的会塌”。
两者都不可或缺。仅凭图纸无法发现施工缺陷,仅凭敲击也无法发现设计缺陷。
LLM带来的变革:从模式匹配到语义理解
传统SAST的顽疾
现有SAST工具的核心归根结底是模式匹配。它们解析AST(抽象语法树),并将其与预定义的规则进行匹配。因此,其局限性显而易见。
- 不了解上下文 → 无法识别“此输入值已在上方中间件中验证”
- 不理解意图 → 坚持认为安全代码存在风险
- 结果? 误报泛滥,开发者信任丧失
传统DAST的顽疾
DAST机械地抛出预设的有效载荷。SQL注入有效载荷从1到100,XSS有效载荷从1到50……因此,它无法捕获以下问题:
- 业务逻辑缺陷:“使用1万积分 → 退款时退还1万5千积分”之类的逻辑缺陷直接通过
- 多阶段场景:无法追踪登录 → 订单 → 支付流程中微妙的缺陷
- 缺乏工作流理解:仅抛出一次性有效载荷即结束
当LLM介入时
LLM将代码和HTTP流量视为语言,关注其含义而非模式。因此,两大阵营都发生了巨大变化。
LLM SAST阵营的变化
- 数据流追踪时理解含义 → 自然语言推断“此变量为用户输入,未经验证即进入SQL”
- 自动修复代码建议 — 不仅仅是警告,而是自动生成“可以这样修复”的PR
- 自然语言解释漏洞 → 初级开发者也能即时理解
- 代表工具:GitHub Copilot Autofix, Snyk DeepCode AI, Amazon CodeGuru Security, Checkmarx One AI Security Champion
LLM DAST阵营的变化
- LLM根据情况生成有效载荷 → 根据响应调整后续攻击
- 业务逻辑漏洞检测 → 自动生成多阶段场景
- 语义化解释响应 → LLM识别“错误消息中暴露了DB堆栈跟踪”
- 代表工具:PortSwigger Burp Suite AI, ZAP AI, StackHawk AI
同一漏洞,不同视角
让我们看看两大阵营如何以不同视角看待同一个SQL注入漏洞。
# 易受攻击的代码
def get_user(user_id):
query = f"SELECT * FROM users WHERE id = {user_id}"
return db.execute(query)LLM SAST的视角
“user_id作为函数参数传入,未经验证或转义,通过f-string直接插入到SQL查询中。这是一个SQL注入漏洞,应改为参数化查询(prepared statement)。请按如下方式修改:”
# 自动建议的补丁
def get_user(user_id):
query = "SELECT * FROM users WHERE id = %s"
return db.execute(query, (user_id,))LLM DAST的视角
- 请求 /users?id=1 → 确认正常响应
- 请求 /users?id=1′ OR ‘1’=’1 → 确认所有用户数据响应
- 在响应中发现PostgreSQL错误消息暴露
- 确认通过额外有效载荷提取数据的可能性 → 报告漏洞已确认
它们通过不同的路径达到相同的结论。因此,两者是互补的。SAST证明“为何危险”,而DAST证明“是否真的会爆发”。
⚠️ LLM安全测试的陷阱区
有光明就有阴影。基于LLM的安全测试也确实存在需要警惕的地方。
1. 幻觉风险
LLM会编造看似合理的谎言。它可能会坚持认为不存在的函数“正在此处被调用”,或者将实际上安全的代码报告为存在漏洞。切勿未经验证就信任。
2. 漏报陷阱
更危险的反而是漏报(false negative)。如果LLM断言“这段代码是安全的”,但实际上它存在漏洞呢?一个漏报比一万个误报更具致命性。
3. 代码外部泄露风险
使用SaaS型LLM SAST意味着内部源代码会被传输到外部LLM API。在金融、公共机构和军事环境中,这直接构成合规性违规。必须认真考虑本地部署LLM(如自托管开源模型)的选项。
4. 成本与响应时间
每次PR都运行LLM SAST会迅速累积令牌成本。此外,LLM的响应时间可能会拖慢CI流水线。需要设计在哪个阶段、以何种深度进行应用。
5. 提示注入 — 新的攻击面
LLM DAST生成有效载荷,反过来也意味着LLM本身可能成为攻击目标。如果被分析的应用程序与LLM集成,那么甚至需要考虑安全扫描器的LLM被反向操控的场景。
️ 融入DevSecOps流水线的5个阶段
理想的实施阶段可以这样设计:
- IDE阶段 — 轻量级LLM SAST辅助。开发者编码时提供实时提示。
- PR阶段 — 精密LLM SAST。主要针对修改文件,自动生成修复PR。
- 构建阶段 — 传统SAST + LLM SAST并行。平衡速度与准确性。
- 预演阶段 — 执行LLM DAST。基于场景,检查业务逻辑。
- 运营阶段 — 轻量级DAST监控 + RASP(运行时应用自保护)。
核心在于“在何处放置何物”。如果在所有阶段都部署所有工具,成本和警报疲劳都将无法承受。
✅ 总结:并非竞争,而是二重奏
LLM SAST和LLM DAST并非相互替代品。它们是二重奏伙伴,从不同角度审视同一个问题。只有“阅读”代码的视角与“敲击”代码的视角相结合,才能完成真正的安全测试。
LLM将两大阵营都从“模式匹配”提升到了“语义理解”。然而,LLM并非万能,只有与人类安全工程师的验证相结合时,才能发挥最强大的作用。
以下是一些可供进一步学习的关键词:
- IAST (交互式应用安全测试) — SAST与DAST的混合体
- SCA (软件成分分析) — 开源依赖漏洞
- RASP (运行时应用自保护) — 运营阶段的自我防御
- AI Red Teaming — 针对LLM自身的安全测试
发表回复