在运营Kubernetes集群时,经常会遇到需要将特定Pod明确部署到所需节点的情况。今天,我们将详细介绍最直观和基础的调度方法:nodeName和nodeSelector。
1. 什么是Pod调度? 📍
在Kubernetes中,调度是决定将待处理的Pod分配到哪个合适的节点并执行的过程。默认情况下,kube-scheduler会检查节点资源状态并自动进行部署,但当管理员需要直接控制时,就会使用nodeName和nodeSelector。
2. 最强大和简单的方法:nodeName 🎯
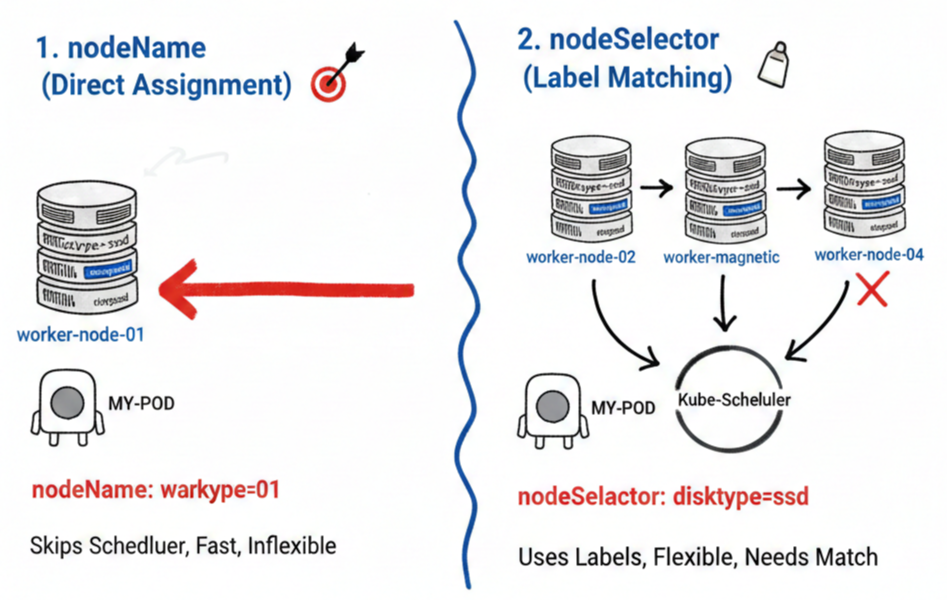
nodeName完全忽略调度器的复杂计算,通过明确指定特定节点名称来强制将Pod部署到该节点。
- 特点: 它绕过kube-scheduler,直接向指定节点的kubelet请求运行Pod。
- 优点: 非常快速和确定。
- 缺点: 缺乏灵活性。如果指定名称的节点不存在或资源不足,Pod将无法运行。
💻 YAML配置示例
YAML
apiVersion: v1
kind: Pod
metadata:
name: nodename-pod
spec:
containers:
- name: nginx
image: nginx
nodeName: worker-node-01 # 必须只分配到此节点3. 基于标签的灵活选择:nodeSelector 🏷️
nodeSelector是一种基于节点上设置的
标签(Label)
来选择Pod将被分配到的节点组的方法。它是目前Kubernetes中最推荐的基础调度方法。
- 特点: Pod只会被部署到具有与Pod规范中定义的键值对(Key-Value pair)匹配的标签的节点上。
- 使用流程:
- 为节点添加标签。
- 在Pod的YAML配置中的nodeSelector中明确指定这些标签。
🛠️ 为节点指定标签
首先,在终端中为节点赋予独特的特性。
Bash
kubectl label nodes worker-node-02 disktype=ssd💻 YAML配置示例
YAML
apiVersion: v1
kind: Pod
metadata:
name: nodeselector-pod
spec:
containers:
- name: nginx
image: nginx
nodeSelector:
disktype: ssd # 只部署到带有 'disktype=ssd' 标签的节点4. nodeName vs nodeSelector 比较总结 📊
| 分类 | nodeName | nodeSelector |
| — | — | — |
| 方式 | 直接指定节点名称 | 将节点标签指定为条件 |
| 调度器介入 | X (绕过调度器) | O (调度器搜索条件) |
| 灵活性 | 非常低 (固定) | 中等 (从具有相同标签的节点中选择) |
| 推荐用途 | 调试特定节点故障时 | 需要特定硬件(GPU, SSD)时 |
—
5. 注意事项和局限性 ⚠️
- 大小写敏感: 标签的键和值严格区分大小写。
- 匹配要求: nodeSelector中指定的所有标签都必须存在于节点上。如果有一个不匹配,Pod将保持Pending状态。
- 复杂条件: 像“节点A或B”、“排除没有标签的节点”这样的复杂逻辑很难用nodeSelector实现。在这种情况下,应使用更高级的概念Node Affinity。
希望这些信息能帮助您高效管理集群资源。
发表回复