“我让AI做了,结果运行得很好。”
您知道那段代码中硬编码了密码吗?
🎯 本文涵盖内容
- 使用AI Agent开发时无意中犯下的安全错误
- 无代码和非专业开发者开发的结构性风险
- 为什么硬编码的秘密是致命的(包括实际案例)
- AI进一步发展后,这个问题会自动解决吗?
- 我们现在需要进行的现实反思和应对
📌 引言 / 背景 — “只要能运行不就行了吗?”
如今,开发环境正在迅速变化。ChatGPT、Claude、Cursor、GitHub Copilot……我们进入了一个时代,只要对AI说“帮我做这个”,一段像样的代码就能立刻生成。
多亏了这一点,许多事情都变得可能。产品经理可以直接制作原型,市场营销人员可以配置数据管道,设计师可以集成API。“非专业人士也能开发”这句话不再是口号,而是现实。
但是,存在一个问题。
AI确实能很好地编写代码。但是,AI不会自动处理安全问题。或者更准确地说——如果你不问,它就不会处理。
# AI随意生成的代码
import openai
client = openai.OpenAI(api_key="sk-proj-xxxxxxxxxxxxxxxxxxxxxxxx") # 😱
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "안녕"}]
)这样的代码上传到GitHub只需几分钟。而这个API密钥被盗取所需的时间……则短得多。

🔍 为什么AI不处理安全问题?
AI的首要目标是“让请求的功能运行起来”。如果用户说“帮我编写上传文件到AWS S3的代码”,它会首先提供最快运行的代码。
如果此时不一并要求遵循安全最佳实践,AI就会理所当然地将Access Key直接嵌入到代码中。
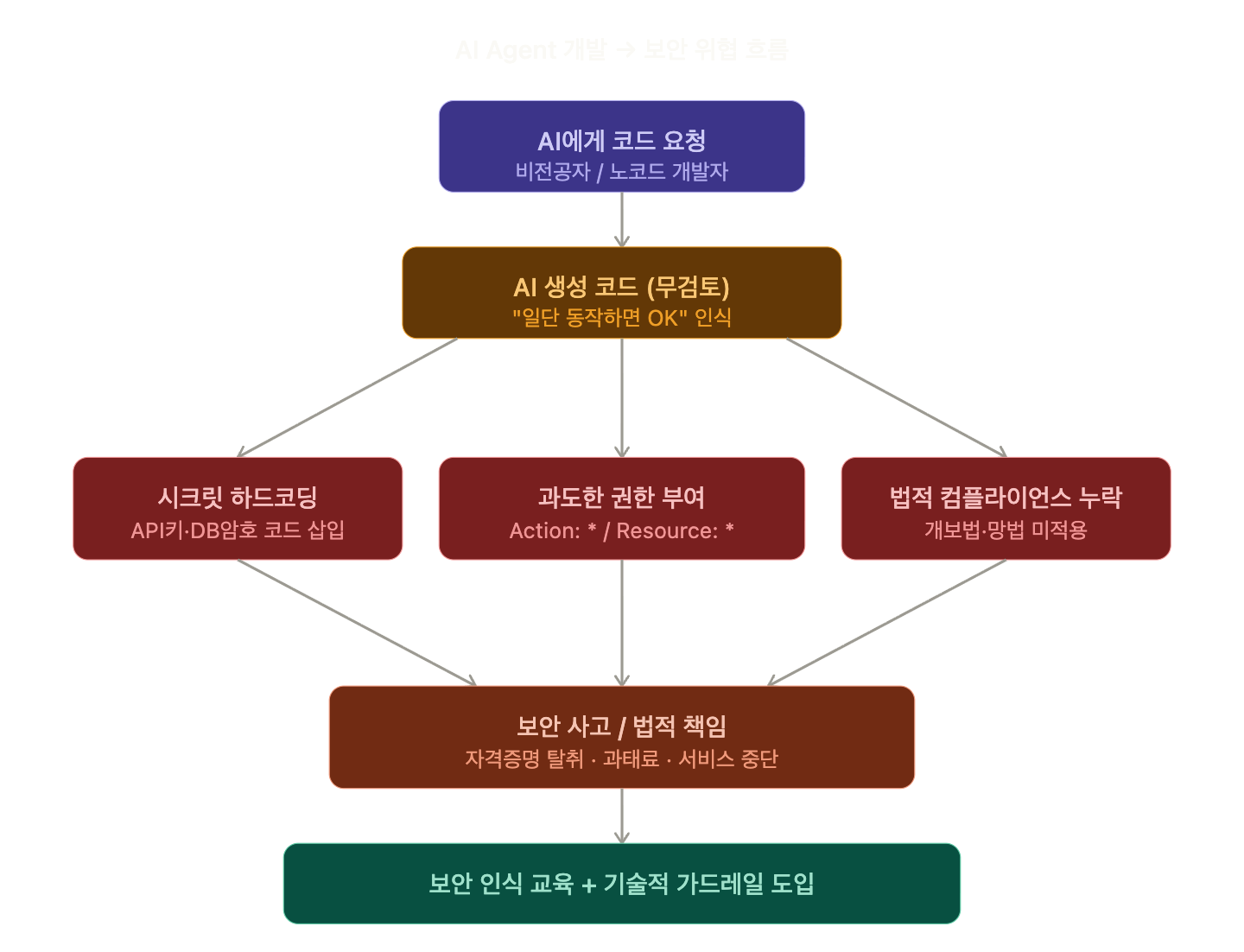
🧩 什么是硬编码?
硬编码(Hardcoding)是指将值直接写入代码的行为。从安全角度来看,将秘密信息直接写入代码尤其成问题:
| 不应硬编码的内容 | 为何危险 |
| API密钥 (OpenAI, Stripe, AWS等) | 上传到GitHub时会向全世界公开 |
| 数据库密码 | 仅通过代码共享即可访问数据库 |
| JWT Secret | 可能伪造令牌 |
| 云IAM凭证 | 存在云权限被完全窃取的风险 |
| OAuth Client Secret | 可能冒充服务 |
实际上,在2023年至2024年期间,GitHub上报告了数百万起秘密信息泄露事件。其中相当一部分是“直接上传了AI生成的代码”的情况。
🔐 正确方法:环境变量和秘密管理
# ✅ 正确方法 — 使用环境变量
import os
from openai import OpenAI
# API密钥从环境变量中读取
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
# 本地开发时使用.env文件,但务必将其添加到.gitignore
# 在生产环境中,使用AWS Secrets Manager、Azure Key Vault、
# HashiCorp Vault等专用服务# .env文件(绝不上传到Git)
OPENAI_API_KEY=sk-proj-xxxx
DB_PASSWORD=my_secret_password
# 务必添加到.gitignore
.env
*.env向AI请求代码时,需要养成这样提问的习惯:
编写AWS SDK集成代码。
但是,凭证不要硬编码,而是使用环境变量或IAM角色。
仅仅这一句话的差别,就能区分安全代码和危险代码。
🏗️ 无代码·非专业开发者开发的结构性问题
硬编码实际上只是冰山一角。我们需要探讨更根本的问题。
1️⃣ 在不了解基础设施结构的情况下进行开发
使用无代码工具或AI创建某些东西时,很多人并不知道它实际运行在什么样的基础设施上。
例如,使用Make(原Integromat)或Zapier创建自动化时——有多少人知道我的数据会经过哪些服务器,以什么权限访问,日志会保存在哪里?
这不仅仅是好奇心的问题,更是法律责任的问题。
2️⃣ 在不了解法律的情况下处理个人信息
在韩国运营服务,至少需要了解以下两部法律:
- 个人信息保护法(个保法):收集·处理个人信息时的同意义务、安全措施义务
- 信息通信网利用促进及信息保护等相关法律(网法):技术性·管理性保护措施义务
如果使用AI创建了会员注册表单,但没有个人信息处理方针,没有加密,也没有正确获得收集同意——那不仅仅是简单的失误,而是违法行为。罚款最高可达数千万韩元,甚至可能达到销售额的3%。
AI不会在“帮我实现这个功能”的请求中自动附带法律合规性。
3️⃣ 不了解最小权限原则
// 😱 AI随意生成的IAM策略
{
"Effect": "Allow",
"Action": "*",
"Resource": "*"
}“先让它都能用”这种方法虽然方便,但却是致命的。最小权限原则(Principle of Least Privilege)是安全的基本中的基本,如果不了解这一点,就会将AI生成的“能运行就行”的设置直接部署到生产环境中。
💭 AI进一步发展后,这个问题会解决吗?
这个问题非常重要,需要坦诚回答。
部分上会好转。
GitHub Copilot已经通过秘密扫描功能检测并警告硬编码的API密钥。AWS或Azure等云服务也运行着当凭证上传到公共仓库时自动禁用它们的机制。AI模型本身也在朝着更积极地提出安全最佳实践的方向发展。
但有些问题根本上无法解决。 技术性的防护措施只能捕捉已知模式。法律和法规无法由AI代替判断。最重要的是,责任仍然在于人。
当发生数据泄露事件时,“这是AI生成的代码”在法律上和道德上都不能成为免罪符。部署服务的人将承担责任。
🔑 AI可以提高工具的性能,但负责任地使用工具的判断力需要人来培养。
🧭 我们现在应该做的事情
在这个时代,所有参与开发的人——无论是开发者、产品经理还是市场营销人员——都应该了解以下最低限度的知识。
✏️ 向AI请求代码时
- 始终附加“应用安全最佳实践”的条件
- 明确要求绝不要将秘密信息直接写入代码
- 在直接复制粘贴生成的代码之前,至少阅读一遍
🏢 组织层面
- 代码审查文化:AI生成的代码也应进行审查
- 引入秘密扫描工具:如truffleHog、gitleaks、GitHub的Secret Scanning等
- 最小权限策略常态化:默认值不应是“所有权限”
- 面向非专业人士的安全意识教育:每年至少进行一次基本安全教育
📚 个人层面
如果您现在运营的服务没有个人信息处理方针,请向AI提问:
“如果我在中国运营一个收集电子邮件的服务,根据个人信息保护法,我有哪些义务?”
AI会给出很好的答案。问题仅仅在于——你必须先问。
✅ 总结 / 结束语
AI降低了开发门槛,这无疑是件好事。更多的人能够创造更多的事物。
但是,门槛降低了,责任并没有随之降低。
硬编码的秘密、过度的权限、缺乏法律合规性——这些问题即使AI发展了也无法“自动解决”。因为这些不是技术问题,而是判断和责任的问题。
在这个时代,如果您正在利用AI创造事物,请至少记住这一点:
💬 “AI只解决我提出的问题。它不会为我没有提出的问题负责。”
发表回复