如果每月的账单让你大吃一惊,你并不孤单。
令牌浪费是所有人的问题。
>

🎯 本文涵盖内容
- 令牌如何精确计费 (输入与输出的区别)
- 如何通过提示缓存(Prompt Caching)将成本降低90%
- 模型选择策略 — 何时使用 Haiku vs Sonnet vs Opus
- claude.ai 普通用户也能应用的实用技巧
- 面向API开发者的代码级优化技术
📌 引言 — 为什么令牌优化很重要
初次使用Claude API时,你可能会遇到这种情况:一开始还不错,但某个时刻月度账单会远超预期。
追溯原因,大多数模式都相似:每次请求都重复发送相同的系统提示,或者对话越长就重新处理整个历史记录,或者对简单任务使用昂贵的Opus模型。
一个开发者的实际案例显示,最初1,000个令牌的会话,经过5次消息交换后膨胀到15,000个令牌以上。这是因为每次对话时,Claude不仅处理新问题,还会重新处理所有之前的提示、之前的响应、代码片段和上下文信息。 BSWEN
本文将系统地解决这个问题。
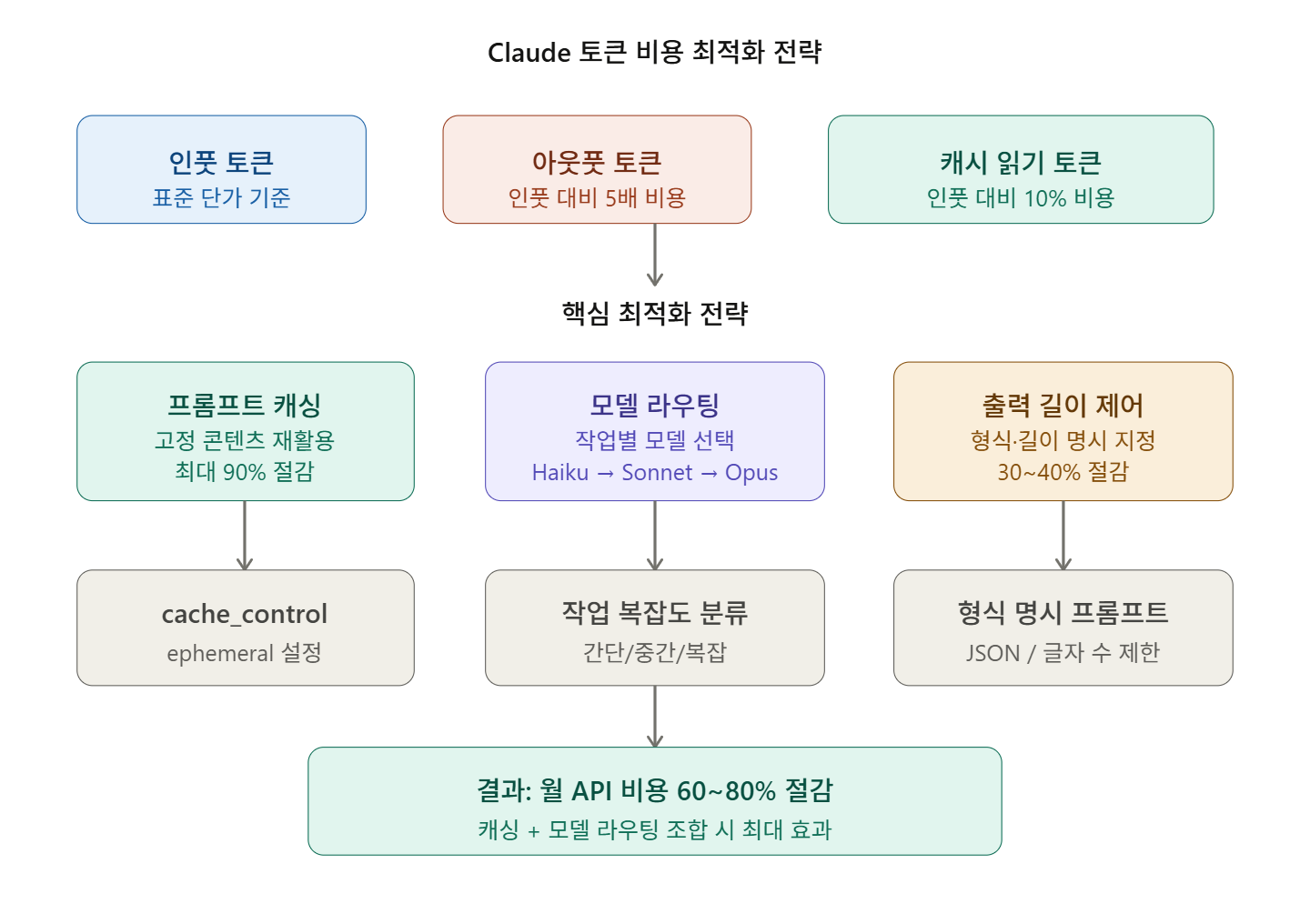
🔍 首先,理解令牌成本结构
输入 vs 输出 — 哪个更贵?
在令牌优化中,首先要了解一个核心事实。
输出令牌比输入令牌贵5倍。 以Sonnet 4为例,500个不必要的响应令牌与浪费2,500个输入令牌的成本相同。优化输出长度比减少输入能带来更大的节约效果。 SitePoint
也就是说,一句“请简短回答”是比你想象中更强大的成本节约方法。
令牌计费结构一览
| 类别 | 说明 | 计费单位 |
| 普通输入 | 每次请求重新处理 | 标准价 |
| 缓存写入 | 保存到缓存时 | 标准价 × 1.25 (5分钟) |
| 缓存读取 | 从缓存加载时 | 标准价 × 0.1 (节省90%!) |
| 输出 | 生成的响应 | 标准价 × 5 |
—
💡 核心技巧 1 — 提示缓存 (Prompt Caching)
概念:“为什么每次都要重新读取相同的内容?”
提示缓存的概念很简单。固定内容(系统提示、文档、工具定义等)只处理一次,后续请求则重用缓存结果。
例如,如果你运营一个每天有数百用户对同一文档提问的系统,通过维护缓存而不是每次都重新处理同一文档,可以节省高达90%的输入令牌成本。 Brunch
如何在API中应用缓存
import anthropic
client = anthropic.Anthropic()
# 在系统提示中添加 cache_control
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[
{
"type": "text",
"text": "당신은 AWS 클라우드 전문가입니다. 아래는 프로젝트 문서입니다...
[수천 토큰의 고정 문서]",
# 👇 这一行是关键!
"cache_control": {"type": "ephemeral"}
}
],
messages=[
{"role": "user", "content": "EC2 비용 최적화 방법을 알려주세요"}
]
)
# 检查使用量
print(f"캐시 읽기 토큰: {response.usage.cache_read_input_tokens}")
print(f"캐시 쓰기 토큰: {response.usage.cache_creation_input_tokens}")###
缓存TTL (有效期) 策略
Anthropic的缓存默认在非活动5分钟后过期。但是,每次缓存命中时,计时器都会重置。因此,在每1-2分钟交换一次消息的活跃编码会话中,缓存会持续保持。相反,如果5分钟以上没有输入,缓存将失效,下一次请求将是冷启动(缓存写入)。 Claude Code Camp
也可以实现1小时的长期缓存:
# 1小时缓存 (需要beta头)
import anthropic
client = anthropic.Anthropic(
default_headers={"anthropic-beta": "extended-cache-ttl-2025-04-11"}
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[
{
"type": "text",
"text": "[대용량 고정 문서...]",
"cache_control": {
"type": "ephemeral",
"ttl": "1h" # 1小时缓存
}
}
],
messages=[{"role": "user", "content": "질문"}]
)⚠️ 注意: 1小时缓存的写入成本是标准价的2倍。仅在请求量足够大的情况下才经济。
💡 核心技巧 2 — 模型选择策略
所有任务都用Opus会让你破产
通常建议80%的任务从Sonnet开始,只有在需要复杂架构决策或深度分析时才切换到Opus。 Claude Fast
| 模型 | 适用任务 | 相对成本 |
| Haiku | 分类、简单问答、关键词提取 | 最低 |
| Sonnet | 编码、分析、一般任务 (大部分) | 中等 |
| Opus | 复杂推理、战略制定 | 最高 |
### 实际路由模式示例
def route_request(task_type: str, complexity: str) -> str:
"""작업 복잡도에 따라 모델 자동 선택"""
if task_type in ["classification", "simple_qa", "keyword_extraction"]:
return "claude-haiku-4-5-20251001" # 最低成本
elif complexity == "high" or task_type in ["architecture", "deep_analysis"]:
return "claude-opus-4-6" # 需要高质量时
else:
return "claude-sonnet-4-6" # 默认 (80%的情况)
# 使用示例
model = route_request(task_type="code_review", complexity="medium")
# → 返回 "claude-sonnet-4-6"💡 核心技巧 3 — 控制输出长度
还记得输出令牌贵5倍的事实吗?因此,控制响应长度对成本节约有最直接的效果。
❌ 令牌浪费型提示
"EC2 비용 최적화 방법을 알려주세요"→ Claude会包含冗长的解释、背景知识、示例和补充说明来响应
✅ 令牌节约型提示
"EC2 비용 최적화 방법을 3가지만, 각 50자 이내로 간결하게 알려주세요"→ 只传递必要的内容
有案例表明,仅在提示中添加明确的长度限制,就能将令牌使用量减少高达40%。核心原则是:“不要让Claude探索你想要什么,而是明确指定你想要什么。” BSWEN
指定响应格式的技巧
# 坏示例
messages=[{"role": "user", "content": "이 코드 리뷰해줘"}]
# 好示例
messages=[{
"role": "user",
"content": """다음 코드를 리뷰해주세요.
형식: JSON으로만 응답
{"issues": [...], "improvements": [...]}
각 항목은 한 줄 이내로 작성"""
}]💡 核心技巧 4 — 上下文管理
对话越长,成本呈线性增长
上下文累积是令牌消耗的主要原因,如果不加以管理,200K令牌的上下文窗口将逐渐被填满。 DeepWiki
不相关的任务务必开启新对话
# 在 Claude Code 中
/clear # 重置当前会话
/compact # 通过对话摘要压缩上下文 (节省约50%)
/cost # 检查当前令牌使用量文件只粘贴必要部分
# ❌ 粘贴整个500行文件
with open("app.py") as f:
code = f.read() # 500行 = 浪费约3,000个令牌
# ✅ 只提取必要的函数
# "请修复 calculate_cost 函数 (第42-67行) 中的错误"💡 核心技巧 5 — Token-Efficient Tool Use (API高级)
对于直接使用API的开发者来说,此功能特别有用。
Token-Efficient Tool Use 目前在Claude Sonnet 4.6和Opus 4.6中可用,只需添加beta头 token-efficient-tools-2025-02-19 即可立即应用。在代理应用程序中结合这些优化,每月API成本可减少60-80%。 Claude Lab
# 启用 Token-Efficient Tool Use
curl https://api.anthropic.com/v1/messages
-H "content-type: application/json"
-H "x-api-key: $ANTHROPIC_API_KEY"
-H "anthropic-version: 2023-06-01"
-H "anthropic-beta: token-efficient-tools-2025-02-19" # 这一行!
-d '{
"model": "claude-sonnet-4-6",
"max_tokens": 1000,
"tools": [...],
"messages": [...]
}'💡 核心技巧 6 — 利用批量API
不紧急的大量任务,使用批量API可享受50%折扣。
import anthropic
client = anthropic.Anthropic()
# 批量处理大量请求
batch_requests = [
{
"custom_id": f"request-{i}",
"params": {
"model": "claude-haiku-4-5-20251001",
"max_tokens": 100,
"messages": [{"role": "user", "content": f"텍스트 {i} 분류해줘"}]
}
}
for i in range(100)
]
# 创建批处理 (24小时内处理,50%折扣)
batch = client.messages.batches.create(requests=batch_requests)
print(f"배치 ID: {batch.id}")⚠️ 常见错误 & 注意事项
破坏缓存的行为:
添加MCP工具、在系统提示中插入时间戳、会话中途切换模型 — 这些行为会使整个缓存失效,导致该请求的成本增加5倍以上。 Claude Code Camp
# ❌ 破坏缓存的模式
system_prompt = f"현재 시각: {datetime.now()}
당신은 전문가입니다..."
# 每次请求时间都不同,导致缓存未命中
# ✅ 正确的模式
system_prompt = "당신은 전문가입니다..."
# 仅对固定内容应用缓存MCP服务器管理:
禁用不必要的MCP服务器。每个激活的MCP服务器都会将工具定义添加到系统提示中,消耗上下文窗口空间。 ClaudeLog
✅ 总结 — 成本节约优先级
按实际应用顺序整理如下:
| 优先级 | 技巧 | 预计节省 |
| 1级 | 应用提示缓存 | 最高90% |
| 2级 | 明确限制输出长度 | 30~40% |
| 3级 | 模型路由 (Haiku/Sonnet/Opus) | 40~70% |
| 4级 | 不相关任务开启新对话 | 20~30% |
| 5级 | 批量API (不紧急的大量任务) | 50% |
| 6级 | Token-Efficient Tool Use 头 | 额外10~20% |
其中,仅提示缓存 + 模型路由的正确应用,在大多数情况下就能将成本降低一半以上。
下一步,建议参考Anthropic官方的提示工程指南以及Claude Code中的 /compact、/cost 命令。
发表回复